







1. 句法语义分析
按照某种语法体系,将句子从词语的序列形式转化为图的结构(通常为树结构),刻画句子内部的语义关系(主谓宾,施事受事等);
2. 三要素:文法(语法结构),数据(基于语法标注数据),算法;
3. 文法发展
短语结构,句法依存,通用依存,语义依存;
从句法逐渐到语义过度 ;
短语结构与句法依存:
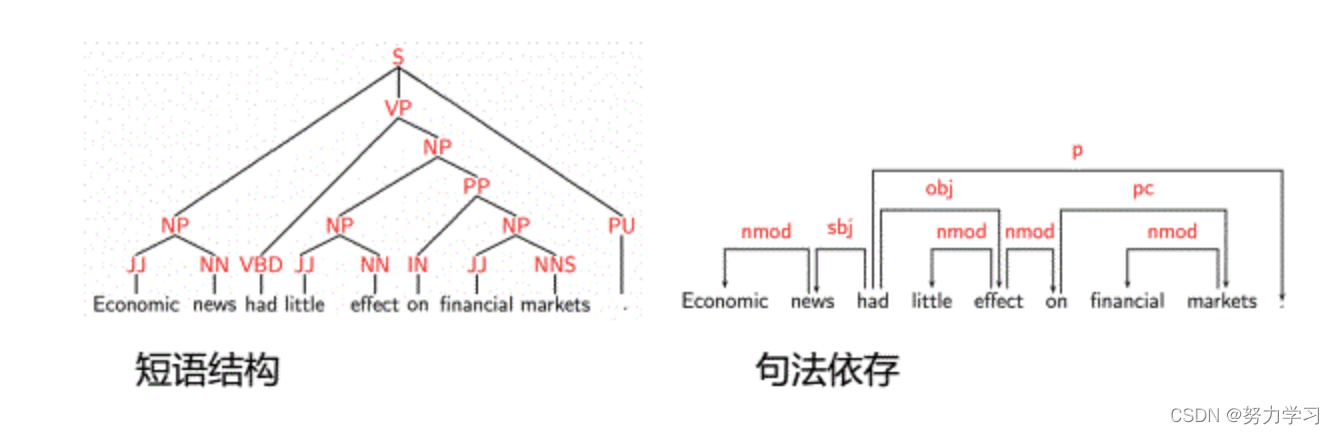
依存分析更直观,标注更方便;
通用文法依存:
最早是由斯坦福提出的;
直接标注实词之间的关系;

语义依存文法:
2012年树状结构,词与词之间的关系,不再是主谓宾这种句法关系,而是施事,受事的语义关系
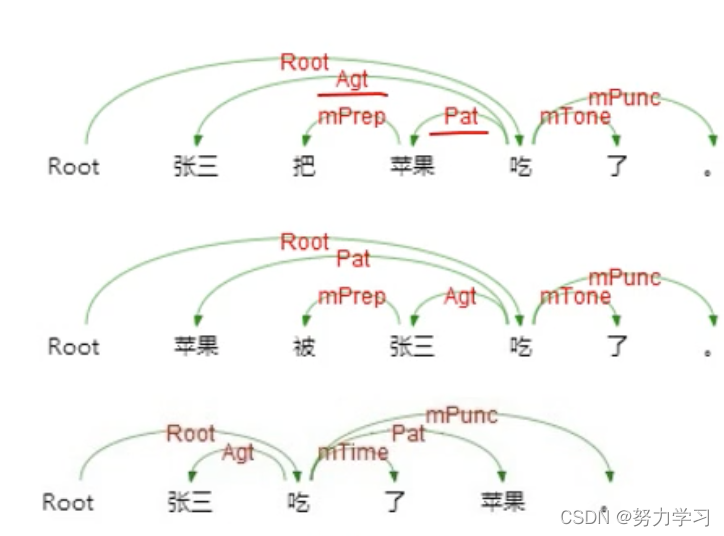
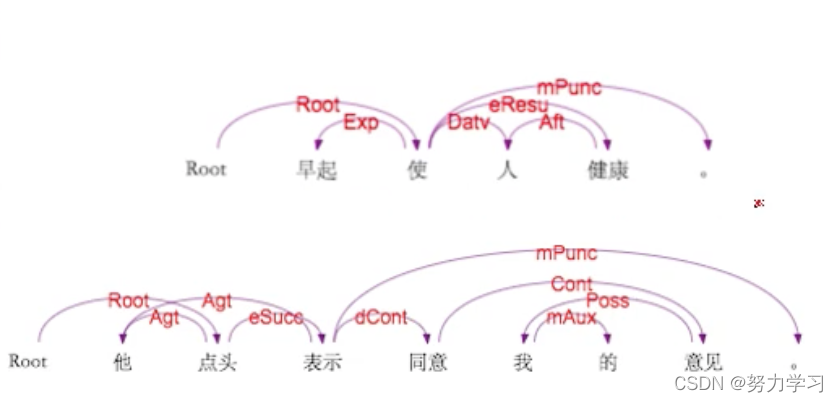
2016年变换为语义依存图的结构
4. 数据变化趋势
单语言单领域,多语言树库,多领域树库,通用树库,语义依存
资源丰富到资源贫乏;
多语言树库:
CoNLL2006 2007评测 10-12种语言
不同语言用不同的依存标注规范来标注,当时不同语言做不同语言的,没有用到多语技术
CoNLL 2009多语依存句法分析和语义角色评测 7种语言
趋势: 多语言,句法和语义的联合
也是每种语言处理每种语言的
多领域依存句法分析:
SANCL 2012评测 -- Google组织
非规范语言句法分析
通用依存树库
统一的词性和语法标注体系
50多种语言,70多个树库;
依存关系与语言无关,统一的标注,不同语言可以互相帮助
CoNLL 2017-- 多语的依存句法分析,端对端的,输入文档,输出句法分析结果(包括分词,分句,词性标注,依存句法分析)
5. 算法发展趋势
PCFG,基于图,基于转移,深度学习
先使用较少特征,到较多特征,再到使用较少的特征;
短语结构PCFG
产生式规则 概率
满足规则,同时概率最高
动态规划算法,
基于图的依存句法分析
从完全图(词与词之间都有依存的弧,弧之间还有分数)中找到分数最高的树
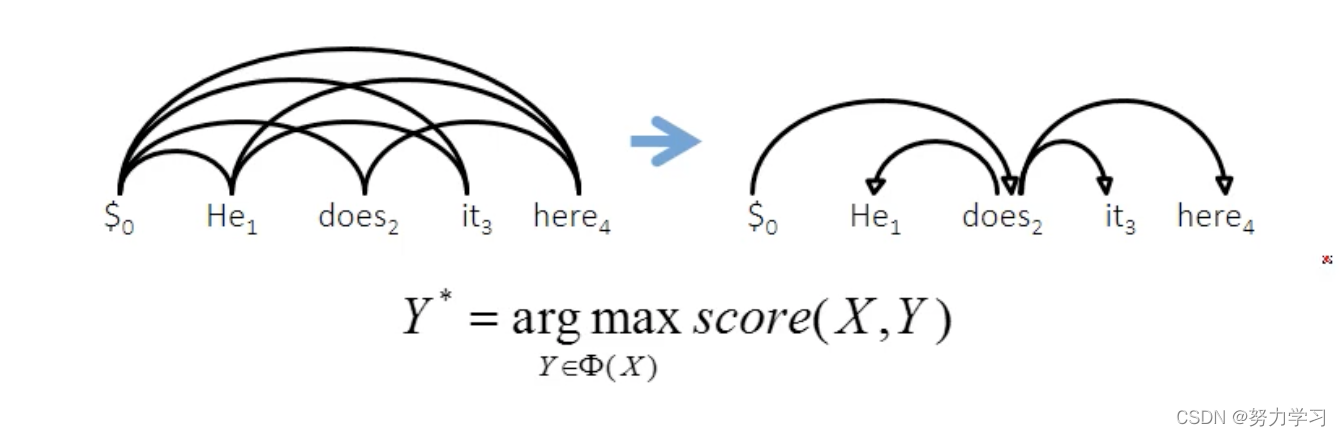
如何计算依存树的分数:
依存书的分数,是每条依存弧分数之和:
父节点到子节点形成一条弧;
如何计算依存弧的分数:
使用特征向量的方法,来表示依存弧,依存弧的分数为特征的线性加权
提取特征是很繁琐和困难的问题(要考虑很多因素)
基于转移的依存句法分析方法
从初始状态到终止状态的动作转移序列
训练分类器,让分类器产生相应的动作,使得从初始状态到终止状态,同时画出依存树
状态 = 栈 + buffer + 相应的操作(动作序列,向左加弧,向右加弧,转移)
基于神经网络依存句法分析
Fast and Accurate Dependency Parser using Neural Network, 从句子中之提取原子的最基本的特征,把特征向量化,隐层特征组合。 这个工作仍然需要人工提取特征。
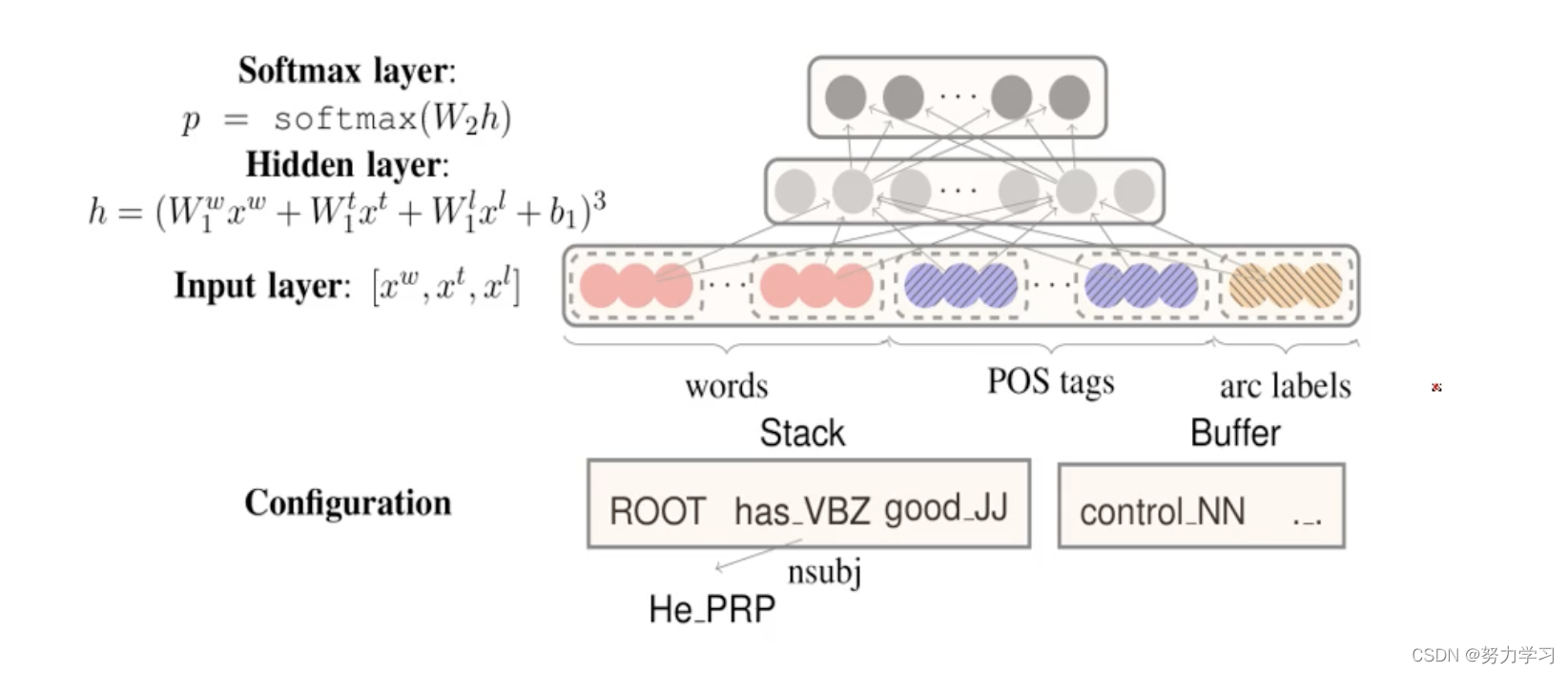
Stack LSTM(用LSTM来表示stack(动态的LSTM)和buffer),不用人工提取特征,只用相应的词输入,通过LSTM进行特征的组合;
全局归一化,解码,训练beam search
SyntaxNet: Google,全局归一化,beam search进行训练
6. 语言技术平台
LTP--语言分析工具
 http://ltp.ai/
http://ltp.ai/应用: 作为抽取规则,作为输入特征(语义角色标注,关系抽取;句法依存结果容易帮助获得关系)
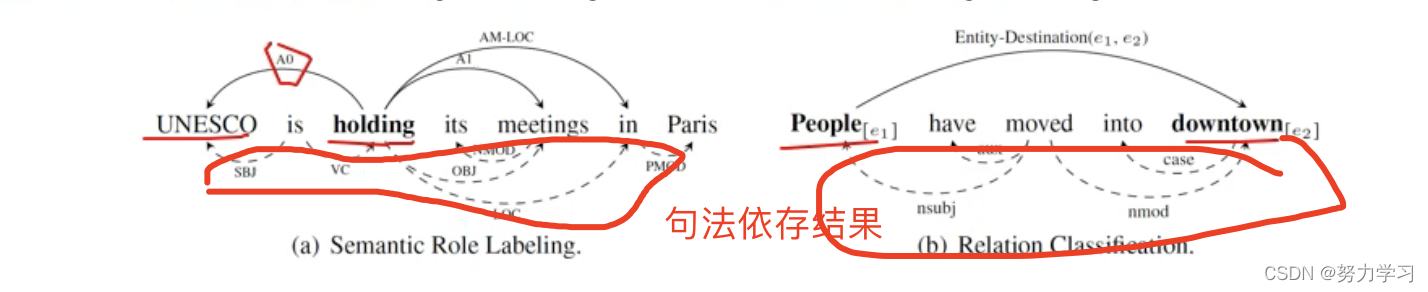
作为输入结构(循环神经网络按照顺序输入,递归神经网络(将语义分析结果作为输入,从结构上判断先组合哪些词,更能刻画结构的信息))


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









