







目录
关于填充(padding)和截断(truncation)的所有信息
对于预训练好的模型参数,我们需要从网上下下来。
from_pretrained()
站在巨人的肩膀上,我们得多用用from_pretrained()这个函数。
参数
1. pretrained_model_name_or_path:
可以是模型名称如 bert-base-uncased ,或者是 path 如 /home/xx/model
2. model_args:
一个可选择的参数序列,可以额外修改模型的参数;
3. config:
自动载入,放在和model同一目录即可;
4. cache_dir:
用来存放下载的文件目录;
清华源还支持huggingface hub自动下载
使用方法
注意:transformers > 3.1.0 的版本支持下面的 mirror 选项。
只需在 from_pretrained 函数调用中添加 mirror 选项,如:
AutoModel.from_pretrained('bert-base-uncased', mirror='tuna')目前内置的两个来源为 tuna 与 bfsu。此外,也可以显式提供镜像地址,如:
AutoModel.from_pretrained('bert-base-uncased', mirror='https://mirrors.tuna.tsinghua.edu.cn/hugging-face-models')清华源21年已经失效;
Roberta pretrain
直接在网站里面搜索模型,下载模型到本地~
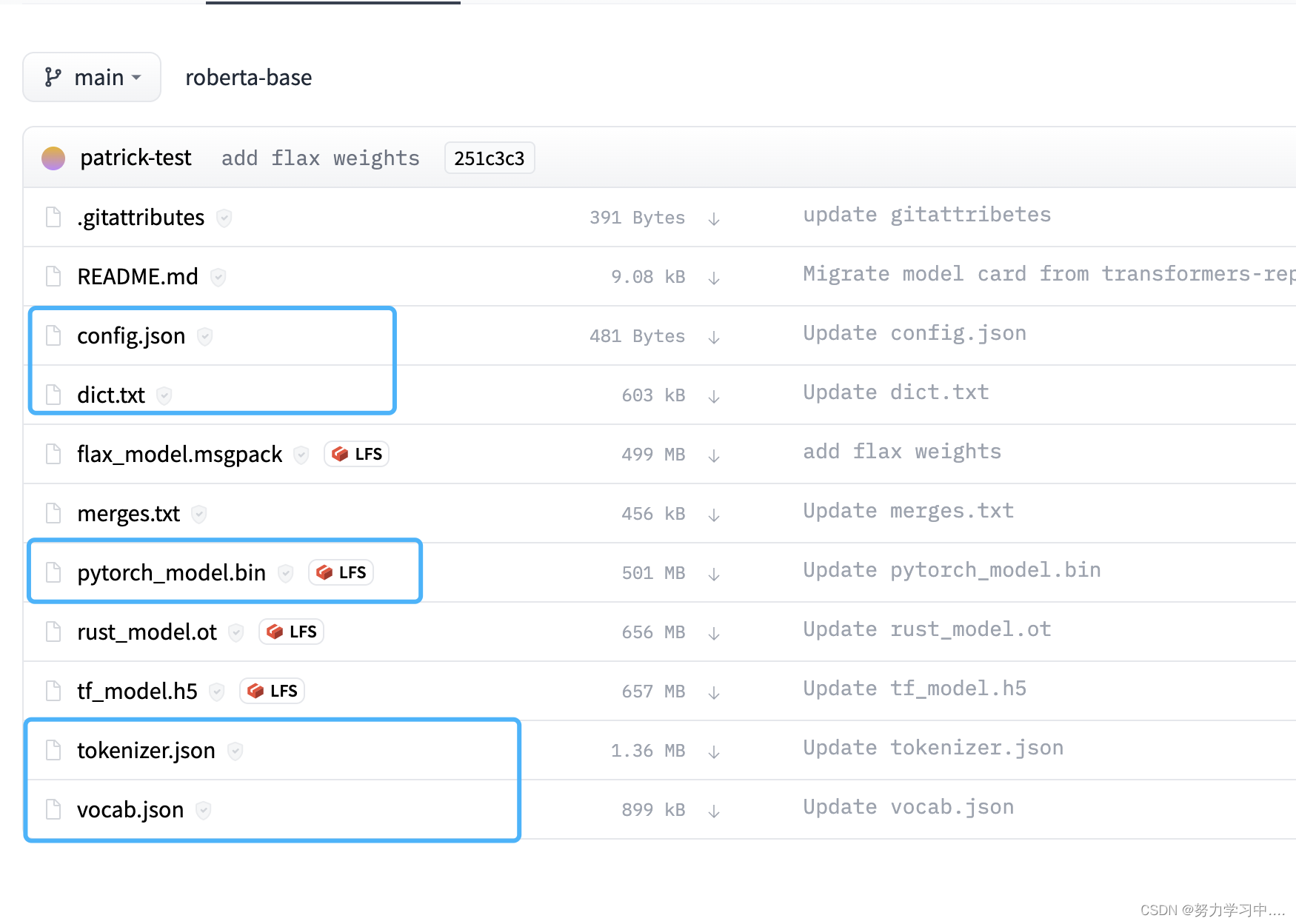
下载到本地,放到同一个文件夹就可以;
上面其他几个比较大的模型文件是用tensorflow等其他语言写的;
然后调用就可以:
from transformers import pipeline, AutoTokenizer,AutoConfig,AutoModel
BERT_MODEL_DIR = "Data/bert"
config = AutoConfig.from_pretrained(BERT_MODEL_DIR)
tokenizer = AutoTokenizer.from_pretrained(BERT_MODEL_DIR)
model = AutoModel.from_pretrained(BERT_MODEL_DIR)
feature_extract=pipeline('feature-extraction',config=config,model=model,tokenizer=tokenizer,framework='pt')tokenizer
(1) tokenizer首先将给定的文本拆分为通常称为tokens的单词(或单词的一部分,标点符号等,在中文里可能就是词或字,根据模型的不同拆分算法也不同);
(2)然后tokenizer能够将tokens转换为数字,以便能够构建张量并输入到模型中;
(3)当然了,大多数预训练语言模型都需要额外的tokens才能作为一次正常的输入(例如,BERT中的[CLS]),这些都会由tokenizer自动完成。
要自动下载在特定模型在预训练或微调期间使用的vocab,可以使用from_pretrained()方法.
在神经网络中,我们常常是通过一个batch的形式来作为一次输入,这个时候你可能想要:
- 如果必要,将每个文本序列填充到最大的长度;
- 如果必要,将每个文本序列截断到模型可以接受的最大长度;
- 返回张量。
将文本序列列表提供给tokenizer时,可以使用以下选项来完成所有这些操作(即设置padding=True, truncation=True, return_tensors="pt"):
batch = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
如果是填充的元素,对应的位置即为0。
关于填充(padding)和截断(truncation)的所有信息
三个参数 padding , truncation 和 max_length 将做进一步的介绍
(1) padding用于填充。
它的参数可以是布尔值或字符串.
True或”longest“:填充到最长序列(如果你仅提供单个序列,则不会填充);
“max_length”:用于指定你想要填充的最大长度,如果max_length=Flase,那么填充到模型能接受的最大长度(这样即使你只输入单个序列,那么也会被填充到指定长度);
False或“do_not_pad”:不填充序列。这是默认行为;
(2) truncation用于截断。它的参数可以是布尔值或字符串:
如果为True或“only_first”,则将其截断为max_length参数指定的最大长度,如果未提供max_length = None,则模型会截断为模型接受的最大长度;
如果提供的是一对文本序列,则只会截断这一对中的第一个文本序列(因为参数“only_first”),如果参数是“only_second”,则只会截断这一对中的第二个文本序列;
“longest_first”截断为max_length参数指定的最大长度,如果max_length = None,则截断到模型接受的最大长度;
False或“do_not_truncate”不截断序列。这是默认行为;
参考:HuggingFace | 在HuggingFace中预处理数据的几种方式 - 知乎
做记录方便自己看,希望大家去看原作者的,更简单易懂!!!

















 4416
4416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









