







目录
解的存在性 (Existence of solution for the system)
基本再生数 (Basic reproduction number)
模型的正性和有效性 (Positivity and validity of the model)
摘要(Abstract)
这篇论文提出了一个新的数学流行病模型,用于研究数字网络(包括社交网络)中错误信息的传播。
该模型考虑了网络中个体对错误信息的态度以及人类智能的特征,这些特征在判断和传播错误信息方面发挥着重要作用。通过数学分析,论文证明了该模型在实时环境中的存在性和有效性;
该论文利用真实世界的数据进行模拟,预测了错误信息如何在不同的全球社区中传播,以及政策制定者应该何时采取干预措施。
模拟结果表明,通过隔离虚假新闻等有效的干预机制,可以有效地控制错误信息在较大群体中的传播。该模型还可以分析经常受到虚假信息影响并传播虚假新闻的群体的情感和社会智能。
绪论(Introduction)
背景与意义
论文指出,在线数字网络(包括社交网络)对个人的生活产生了重大影响,并在信息传播方面发挥着重要作用,进而影响全球社会。然而,这些平台也成为了错误信息迅速传播的温床,对社会凝聚力、民主进程和公共健康构成了重大挑战。
在数字时代,社交媒体平台已成为信息传播不可或缺的一部分,塑造公众舆论并影响社会讨论。因此,研究虚假或误导性信息在社交网络中的传播已成为一个关键领域,涉及计算机科学、社会学、心理学和传播学等多个学科。
问题提出
论文强调,社交智能(有效理解和驾驭社交环境的能力)在个体和组织之间建立联系和伙伴关系方面至关重要。然而,虚假新闻和错误信息的传播是建立信任和信誉的重大障碍。一些人利用数字网络传播虚假信息以获取利益,损害了个人和社区的声誉和信任。
情商和社交智能水平较低的人更有可能在不考虑其有效性的情况下分享虚假新闻和错误信息。此外,接触虚假新闻和错误信息可能会影响个人的社交智能,使其对共享信息的真实性和准确性产生怀疑。
多项研究表明,错误信息和虚假新闻对社会产生了不利影响,尤其是在医疗保健领域。虚假新闻和错误信息可能对个人和组织的声誉产生不利影响,甚至可能误导一群人反对政府或特定的治疗方法。在COVID-19大流行期间,虚假和伪造的新闻在社会中造成了额外的焦虑,与医疗实践相关的事件以及疫苗犹豫证明了这一点。与此同时,通过数字网络传播的错误信息也被发现影响了个人的心理健康。接触错误信息的人在决策和解决问题的能力方面存在困难。
相关概念辨析
论文对谣言、错误信息、虚假信息和假新闻等术语进行了区分。
谣言(Rumors):是从人到人传递的故事,通常没有证据支持。
错误信息(Misinformation):指的是传播不正确的消息,但并非故意造成伤害。
虚假信息(Disinformation):指的是个人有明确的目的故意捏造和传播不正确的内容以造成伤害。
假新闻(Fake news):是一种旨在伪装成真实新闻的欺骗形式,在社交媒体上广泛传播,难以与真实新闻区分开来。
错误信息传播的特点
论文指出,社交媒体中的错误信息具有病毒式传播的特点,通常比准确信息传播得更快更远。以下几个因素推动了这种现象:
1. 回音室和过滤气泡:数字和社交媒体算法通常会向用户展示强化其信念的内容,形成回音室,从而在志同道合的社区中传播错误信息。
2.情感诉求:虚假信息通常会引发强烈的情感反应,增加分享和参与的可能性。
3.确认偏误:用户更倾向于接受和传播证实其先前存在的信念或偏见的信息。
4.网络效应:社交网络互连的性质允许信息在不同的用户群体中快速、呈指数级地传播。
5.内容创建和分享的低门槛:在社交媒体平台上创建和传播内容的便利性促进了未经证实信息的快速传播。
6. 缺乏事实核查:信息的流动速度通常超过了传统的事实核查机制。
流行病模型的类比
论文指出,错误信息在社交网络中的传播动态类似于流行病学模型,其中“感染”代表接触和分享虚假信息。这种类比促使人们尝试建立各种数学模型来捕捉和预测错误信息的传播,并借鉴疾病传播模型。理解这些相互作用对于设计成功的错误信息预防技术至关重要。这些措施包括提高数字素养,升级平台算法以检测和防止误导性信息的传播,以及进行有针对性的干预以破坏错误信息传播的循环。
现有模型的不足
论文认为,尽管已经发展出几种数学流行病模型,但大多数模型仍然需要解释人类选择的本质和社会影响。
当前的模型也没有考虑到人们可能出于各种原因传播虚假信息这一现实。
此外,他们也未能解释超级传播者制造假新闻的可能性,在这些情况下,一些病毒式错误信息可以传播很长时间。
这些模型还假设人们是理性行为者,他们根据对信息的仔细考虑做出判断。
论文贡献
考虑到以上不足,论文做出了以下贡献:
1.创建了一个数学流行病模型,该模型考虑了人类选择的本质和社会智能以及受约束的状态,并考虑了幂律特性。
2.在数学上证明了该模型在现实世界中的存在性。
3.使用该模型和真实世界的数据分析了不同社区中虚假新闻的刚性。
论文结构
论文分为七个部分。
下一节讨论了常用于探索社交网络的相关流行病模型。
在“模型属性”中,定义并以数学方式讨论了所提出的模型。
“模型分析”讨论了模型的属性,这些属性证明了解在现实世界中的有效性和存在性。使用R在模拟环境和真实世界数据中解释了模型的意义。
“模拟结果”解释了模拟结果。
“讨论”描述了发现和观察到的参数,
“结论和未来范围”检查了研究的未来范围和结论。
相关工作(Related Works)
“相关工作(Related Works)”部分主要讨论了已有的研究成果和模型,并指出了它们在处理错误信息传播问题上的局限性。
对错误信息传播原因和机制的探索
许多研究致力于探索错误信息在不同数字网络平台上快速传播的原因和机制。研究表明,人际关系较少的人对于谣言的迅速传播至关重要。
虚假新闻分类方法
近年来,涌现出一些虚假新闻分类机制,这些机制通常通过预处理数据、结合Glove词嵌入过程和机器学习模型来实现。这些方法在区分虚假新闻和真实新闻方面取得了较好的效果;
干预机制的挑战
尽管虚假新闻分类方法不断发展,但在正确的环境和时间应用干预机制以对抗错误信息的传播仍然是一个挑战。虚假新闻的传播速度取决于每个社区的多种因素;
社交媒体谣言的影响
社交媒体上的谣言可能会对个人声誉产生负面影响,无论是学生还是专业人士。而且,一旦声誉受损,重建起来非常困难;
流行病模型的应用
虽然阻止虚假新闻的产生几乎是不可能的,但已经提出了几种流行病模型来研究和分析信息的传播。社交网络中的流行病模型是用于研究传染病在社交网络中传播的数学模型。这些模型有助于更好地理解错误信息在数字网络中的传播方式以及如何处理它们。
人工智能和大型语言模型(LLM)的影响
由于数字网络中错误信息的日益普及,理解其传播变得越来越重要。最近的研究探讨了人工智能(AI)和大型语言模型(LLM)在错误信息活动中的作用,强调了人工智能驱动的内容可能会加剧这个问题。
心理因素和治疗方法
大量的研究工作检验了影响人们接受虚假信息的心理因素以及治疗的有效性。研究表明,人们的评估和在线信息分享会显著影响他们的情绪反应和认知偏差。
心理免疫策略
一些研究还着眼于如何将预先接触欺骗策略用作一种免疫方法,以增强社区和个人对欺骗努力的抵抗力。这些结果强调了在制定对抗虚假信息的方法时,考虑心理和技术因素的重要性,因为它会增加个人的焦虑,尤其是在危机时期。
社交网络流行病模型的重要性
与病原病毒不同,错误信息通过社交接触传播,并且容易受到社会偏见和情绪反应的影响,因此社交网络流行病模型对于研究错误信息至关重要。传统的流行病模型侧重于传染病。通过考虑这些社会和心理因素以及网络结构本身,这些模型使研究人员能够研究错误信息在网络中的传播。
网络流行病模型
基于网络的流行病模型(研究疾病在社交网络结构框架内的传播)近年来受到了越来越多的关注。这些模型考虑了人们彼此建立的各种连接以及这些连接如何影响疾病的传播。包括艾滋病毒、埃博拉病毒和COVID-19在内的疾病都已使用基于网络的模型进行研究。最常见的模型是SI、SIR和SIS模型.
传统流行病模型
这些模型将整个网络的人口分为易感者(S)、感染者(I)和康复者(R)。易感-感染-恢复(SIR)模型是研究最广泛的网络流行病模型之一,它已经以多种方式扩展,以包括网络拓扑。例如,可以修改SIR模型以考虑网络中的异质混合模式,包括更有可能传播疾病的高度连接的“中心”人物.
其他模型
易感-感染-易感(SIS)模型认为人们可以多次感染,而易感-暴露-感染-恢复(SEIR)模型包括一个“暴露”状态,适用于已感染但尚未传播的人。为了探索传染病通过社交网络的传播,SEIR模型也已扩展到包含网络结构。在网络SEIR模型中,人们不仅通过其疾病状态联系在一起,还通过其社会关系联系在一起。尽管个人可能具有不同程度的连通性和接触患病他人的机会,但网络结构可能会影响疾病传播的动态.
SEPNS模型
SEPNS模型通过根据谣言的情感将感染状态分为积极感染和消极感染来扩展SEIR模型。
暴露节点确定了一个人相信错误信息并传播它的可能性。
根据传播的错误信息的情感,感染状态分为积极感染和消极感染。
但是,该模型未能解释错误信息的中性情感,也未能解释积极感染节点变为消极感染节点以及反之的可能性.
SEDIS模型
SEDIS模型是当前用于研究传染病传播的传统SEIR流行病模型的另一项发展。
SEDIS模型中添加了一个新的隔间,指定为怀疑者(D),以反映那些听过这个故事但尚未确信其真实性的人。
怀疑者隔间对于传播谣言至关重要,因为它决定了它们是真是假。
SEDIS模型的另一个组成部分是人类的选择倾向(也称为人们根据自己的偏好和偏见选择信任和传播哪些信息的现实)。基于个人的选择行为,提出了一个函数,该函数捕获了一个人从怀疑者隔间移动到感染者隔间的可能性。该模型强调了在分析社交网络中的信息流行病时,考虑人类选择本质的重要性。
从易感状态(S)到暴露状态(E)的转移率 (α):表示易感人群接触到谣言/虚假信息的速率;
从暴露状态(E)到怀疑者状态(D)的转移率 (β1):表示暴露于虚假信息的人群转变为怀疑信息真实性的速率;
从暴露状态(E)到感染状态(I)的转移率 (β2):表示暴露于虚假信息的人群转变为相信并传播信息的速率;
从怀疑者状态(D)到感染状态(I)的转移率 (γ):表示对信息真实性存疑的人群在持续接触后转变为相信并传播信息的速率;
从暴露状态(E)、怀疑者状态(D)和感染状态(I)回到易感状态(S)的转移率 (µ1, µ2, µ3):分别表示暴露人群、怀疑者和感染者因失去兴趣或验证信息后回到易感状态的速率;
SEDIS模型可以被称为社交网络的流行病模型,因为它将数字网络中的所有错误信息和虚假新闻视为一种疾病。该模型可以成为理解和限制虚假信息在社交网络中传播的有用工具,因为它提供了更现实和准确的谣言传播动态表示.
The SEDPNR model
SEDPNR模型是一种数学流行病模型,旨在模拟错误信息在在线数字网络(尤其是社交媒体平台)中的传播动态。该模型扩展了传统的流行病模型,通过考虑用户的情感和社会智能来更真实地反映人类行为。
以下是SEDPNR模型各组成部分的详细介绍:
模型的状态
易感者 (S):指在时间 t 容易受到错误信息影响的个体。可以理解为是尚未接触到相关虚假新闻或错误信息,或者即使接触到但仍保持怀疑态度的人群。个体有可能从“怀疑者”或“暴露”状态回到“易感”状态。
暴露者 (E):指已经接触到相关虚假新闻或错误信息的个体。处于暴露状态的个体,根据他们的社会和情感智力,可能会转变为“感染者”或“怀疑者”。如果个体对该信息缺乏兴趣,也可能从“暴露”状态返回到“易感”状态。接触到不实信息后,人们可能没有进行批判性评估或仔细关注,从而进入“暴露”状态。
怀疑者 (D):指那些听说了相关信息但尚未确信其真实性的个体。他们可能对信息的来源或真实性存在疑问。怀疑者状态是SEDPNR模型对传统流行病模型的一个重要扩展。个体在报纸、电视频道和事实核查网站的共同影响下,可能会质疑信息的真实性。个体可以选择处于怀疑者状态,并决定是否接受或拒绝谣言;
积极感染者 (P):指以积极的态度传播错误信息的个体;
消极感染者 (N):指以消极的态度传播错误信息的个体。
受限者 (R):指那些对传播信息失去兴趣的个体。他们可能是因为时间推移、意识到信息的虚假或其他原因而停止传播4。需要注意的是,个体只有在成为传播者之后才会进入受限状态;
状态转移
SEDPNR模型中的个体可以在不同的状态之间转移,模拟人们在社交网络中接触、评估和传播信息的过程。模型中不同状态之间的转移过程,与真实社交网络中的行为非常相似。
S 到 E (α):表示用户首次遇到错误信息。类似于在社交媒体上看到一个被分享的帖子。
E 到 D (γ):表示一些用户在最初接触后开始变得怀疑,并开始质疑信息的真实性。类似于社交媒体用户进行事实核查或寻求信息来源。
E 到 P/N (β1, β2):表示暴露于错误信息的用户以积极或消极的态度分享该信息。类似于人们在分享帖子的同时发表自己的评论。
D 到 P/N (β3, β5):表示怀疑者最终选择相信一方,并开始传播信息。类似于用户最初持怀疑态度,但后来被说服并开始分享信息。
P/N 到 R ( 1, 2):表示用户停止传播错误信息。可能是因为事实核查或平台干预。类似于用户删除帖子或改变立场。
模型假设
SEDPNR模型基于以下假设:
有限的注意力和处理能力:当人们遇到虚假信息时,他们可能无法批判性地评估或仔细关注,这使他们处于“暴露”状态。
认知偏差:怀疑者类别说明了由于先前的偏见或不完整的知识,人们可能相信或不信任该消息。
动态信念状态:该模型承认事实核查或观点转变的可能性,并允许人们根据情感接受或拒绝虚假信息。
行为改变:“受限”类别表明提高意识的举措或干预措施可以降低人们传播虚假信息的倾向;
数学描述
SEDPNR模型可以用一组微分方程来描述,这些方程描述了每个状态中个体数量随时间的变化。这些方程考虑了状态之间的转移率以及其他相关参数。
SEDPNR模型使用一组微分方程来描述每个状态(易感者、暴露者、怀疑者、积极感染者、消极感染者和受限者)中个体数量随时间的变化:
案例设定
•假设我们有一个小型社交网络,总人数为N,并且我们正在追踪一个特定虚假信息的传播。我们假设时间以天为单位。
状态变量
◦S(t):在t时刻处于易感状态的人数
◦E(t):在t时刻处于暴露状态的人数
◦D(t):在t时刻处于怀疑者状态的人数
◦P(t):在t时刻处于积极感染状态的人数
◦N(t):在t时刻处于消极感染状态的人数
◦R(t):在t时刻处于受限状态的人数
参数设定
α:易感者变为暴露者的转移率,例如α = 0.1,表示每天有10%的易感者接触到虚假信息。
◦β1:暴露者变为积极感染者的转移率,例如β1 = 0.05,表示每天有5%的暴露者积极传播虚假信息。
◦β2:暴露者变为消极感染者的转移率,例如β2 = 0.03,表示每天有3%的暴露者消极传播虚假信息。
◦γ:暴露者变为怀疑者的转移率,例如γ = 0.02,表示每天有2%的暴露者开始怀疑信息。
◦µ1:暴露者恢复为易感者的转移率,例如µ1 = 0.01,表示每天有1%的暴露者失去兴趣或验证信息后回到易感状态。
µ2:怀疑者恢复为易感者的转移率,例如µ2 = 0.01,表示每天有1%的怀疑者验证信息后回到易感状态。
◦r1:积极感染者变为受限者的转移率,例如r1 = 0.02,表示每天有2%的积极感染者停止传播。
◦r2:消极感染者变为受限者的转移率,例如r2 = 0.02,表示每天有2%的消极感染者停止传播。
微分方程
◦易感者:ds/dt = µ1*e + µ2*d − α*s
解释:易感者人数的变化率等于从暴露者和怀疑者恢复为易感者的人数减去变为暴露者的人数。
▪例如,如果e=100,d=50,s=1000,那么ds/dt = 0.01*100 + 0.01*50 - 0.1*1000 = 1 + 0.5 - 100 = -98.5。这意味着易感者人数每天减少98.5人。
暴露者:de/dt = α*s − (β1 + β2 + γ + µ1)*e
解释:暴露者人数的变化率等于从易感者变为暴露者的人数减去变为积极感染者、消极感染者、怀疑者和恢复为易感者的人数。
▪例如,如果s=1000,e=100,那么de/dt = 0.1*1000 - (0.05 + 0.03 + 0.02 + 0.01)*100 = 100 - 11 = 89。这意味着暴露者人数每天增加89人.
怀疑者:dd/dt = γ*e − (β3 + β4 + µ2)*d3
积极感染者:dp/dt = β1*e + β3*d − r1*p3
消极感染者:dn/dt = β2*e + β4*d − r2*n3
受限者:dr/dt = rr1*p + 2*n
数值计算
为了模拟这些状态随时间的变化,我们需要使用数值方法(例如欧拉方法或龙格-库塔方法)来求解这些微分方程。这些方法通过离散的时间步长来近似计算每个时间点的状态变量.
欧拉方法:例如,要计算下一天(t+1)的易感者人数,可以使用以下公式:
S(t+1) = S(t) + dt* (µ1*E(t) + µ2*D(t) − α*S(t))
模拟结果
通过重复计算每个时间步长的状态变量,我们可以得到每个状态中个体数量随时间变化的曲线。这些曲线可以帮助我们理解虚假信息传播的动态,并评估不同干预策略的效果;
模型的意义
SEDPNR模型旨在更准确地模拟错误信息在社交网络中的传播,并帮助制定有效的干预策略。该模型考虑了用户心理、社会影响和情感因素,从而能够更全面地理解错误信息传播的动态。通过对模型进行参数调整和仿真,可以预测不同干预措施的效果,并为决策者提供参考.
伦理考量
对错误信息传播的建模和研究涉及重要的伦理考量,例如隐私保护、数据安全和避免模型被滥用。研究人员有责任以符合伦理的方式使用模型,并避免将其用于恶意目的.
总而言之,SEDPNR模型是一种复杂而有用的工具,可以帮助我们理解和应对在线数字网络中错误信息的传播。通过考虑人类行为的复杂性,该模型为制定有效的干预策略提供了新的视角.
Properties of the model
"Properties of the model"(模型的属性)部分主要探讨了SEDPNR模型在数学上的特性,包括其解的存在性、基本再生数、模型的正性和有效性,以及模型的稳定性等。这一部分旨在验证模型是否能在实际环境中有效描述谣言传播的动态,并分析其长期行为.
解的存在性 (Existence of solution for the system)
◦重要性:验证模型是否有效且精确。
◦方法:通过雅可比矩阵 (Jacobian matrix) 来确定系统解的存在性。雅可比矩阵包含了向量值函数关于其输入变量的所有偏导数。
◦定理 1:对于SEDPNR系统 (S(t), E(t), D(t), P(t), N(t), R(t)),在时间 t 上总是存在一个解。
◦证明:通过证明导出的雅可比矩阵的元素本质上是连续的,从而得出函数 f 是一个连续可微的映射,解释了系统解的存在性.
在数学模型中,“解”“模型能否算出结果”。更准确地说,它指的是描述模型中各个变量随时间变化规律的函数是否存在。如果一个模型没有解,或者解不存在,那么这个模型就没有实际意义,因为我们无法用它来预测或分析任何现象。
案例背景:简化版社交网络
•假设有一个简化版的社交网络,里面有1000个人,正在传播一个关于健康的新闻(可能是谣言)。我们想用SEDPNR模型来预测这个消息会如何传播。SEDPNR模型把人群分成几个状态:
S (Susceptible, 易感者): 还没接触过新闻的人。
E (Exposed, 暴露者): 已经接触过新闻,但还没决定是否相信的人。
D (Doubter, 怀疑者): 对新闻持怀疑态度的人。
P (Positively Infected, 积极感染者): 积极相信并传播新闻的人。
N (Negatively Infected, 消极感染者): 不相信新闻,并且可能辟谣的人。
R (Restrained, 受限者): 已经对这个新闻失去兴趣,不再传播的人
问题:这个模型能算出结果吗?
“解的存在性”要回答的问题是:对于这个社交网络和健康新闻,SEDPNR模型是否能够给出每个状态(S、E、D、P、N、R)的人数随时间变化的明确的数学公式或曲线?换句话说,我们能否用这个模型预测未来每一天,每个状态分别有多少人?
雅可比矩阵:判断解是否存在的工具
•资料中提到,判断解是否存在需要用到一个叫做雅可比矩阵的数学工具.。可以简单地理解为,雅可比矩阵是一个包含模型中所有变量之间相互影响关系的表格。如果这个表格里面的所有数值都是“良好”的(比如,都是连续变化的,没有突然的跳跃),那么我们就可以证明这个模型是存在解的
定理 1 的意义
•定理 1 的内容是:对于SEDPNR系统,在任何时间点 t,都存在一个解。这意味着,只要我们合理地设置模型的初始状态(比如,一开始有多少人是易感者,多少人是暴露者),并且模型的参数(比如,传播速率)是合理的,那么SEDPNR模型就一定能够给出每个状态的人数随时间变化的预测结果。
案例结论:模型可用
•在这个案例中,如果我们用雅可比矩阵验证了SEDPNR模型满足解存在性的条件,那么我们就可以放心地使用这个模型来模拟健康新闻在社交网络中的传播,并且相信我们得到的预测结果是有数学依据的。
基本再生数 (Basic reproduction number)
◦定义:基本再生数 (R0) 表示在一个完全易感的网络中,单个感染者平均会引起的感染人数。用于评估疾病在人群中传播的潜力。
◦影响因素:用户的行为、网络结构以及谣言的特征都会影响 R0 的值。
◦应用:R0 对于确定疫情的严重程度和干预措施的有效性至关重要。如果 R0 小于 1,疫情最终会消退;如果 R0 大于 1,疾病更可能在人群中迅速传播,可能导致流行病。
◦计算:通过识别系统方程中的传播项和恢复项,构建下一代矩阵 F 和恢复率的对角矩阵 V,然后计算 的谱半径来得到 R0。该模型的R0是积极和消极感染隔间的传播率与恢复率之比的最大值.
核心概念:基本再生数 (R0)
•在流行病学模型中,基本再生数 (R0) 是一个关键指标,它表示在完全易感的人群中,一个感染者平均能够传染给多少人。简单来说,R0 越高,疫情传播的风险就越大。在SEDPNR模型中,R0 可以用来评估一条虚假信息在社交网络中传播的潜力
案例背景:社交网络中的“健康饮食”谣言
•延续之前关于简化版社交网络的案例,假设现在有一条关于“健康饮食”的虚假信息开始在网络上传播。这条信息声称“每天只吃水果可以排毒养颜”。我们想用SEDPNR模型来分析这条谣言的传播情况。人群仍然被分为以下几个状态:
S (Susceptible, 易感者): 还没接触过谣言的人。
E (Exposed, 暴露者): 已经接触过谣言,但还没决定是否相信的人。
D (Doubter, 怀疑者): 对谣言持怀疑态度的人。
P (Positively Infected, 积极感染者): 积极相信并传播谣言的人。
N (Negatively Infected, 消极感染者): 不相信谣言,并且可能辟谣的人。
R (Restrained, 受限者): 已经对这个谣言失去兴趣,不再传播的人。
R0 的意义:衡量谣言的“传染力”
•在这个案例中,R0 的意义是:如果一开始只有一个人 (P) 相信并传播“每天只吃水果可以排毒养颜”的谣言,那么这个人平均会说服多少人也开始相信并传播这个谣言?
◦如果 R0 < 1:这意味着平均下来,每个传播谣言的人只能让不到一个人相信。那么这条谣言会逐渐消失。
◦如果 R0 > 1:这意味着平均下来,每个传播谣言的人能让超过一个人相信。那么这条谣言会像病毒一样扩散开来,可能会引起恐慌或误导。
影响 R0 的因素
•根据资料,以下因素会影响 R0 的大小:
◦用户的行为:如果用户更容易相信谣言,或者更倾向于分享未经证实的信息,那么 R0 就会增加。
◦网络结构:如果社交网络中存在大量的“信息中心”(拥有大量粉丝或关注者的人),那么谣言更容易通过这些中心快速传播,导致 R0 增加。
◦谣言本身的特征:如果谣言内容耸人听闻、情感色彩强烈,或者与用户的固有偏见相符,那么用户更容易相信并传播,导致 R0 增加。
如何降低 R0,控制谣言传播
•理解了 R0 的意义之后,我们可以采取一些措施来降低 R0,从而控制谣言的传播:
◦提高用户的辨别能力:通过教育、宣传等方式,提高用户对虚假信息的警惕性,使其在接触到可疑信息时能够进行独立思考和判断。
◦减缓谣言的传播速度:社交平台可以采取一些技术手段,例如限制谣言的传播范围、对可疑信息进行标注等。
◦增加辟谣信息的传播:官方机构、媒体或专业人士可以及时发布辟谣信息,纠正错误观点,降低用户对谣言的信任度。
R0 的计算
•R0 的计算需要构建下一代矩阵 F 和恢复率的对角矩阵 V,然后计算 FV-1 的谱半径来得到 R0。这个计算过程比较复杂,但核心思想是分析谣言在不同状态之间传播的速率,以及用户从相信谣言到不相信谣言的转变速率。
R0计算案例
为了简化计算,我们假设:
◦只有暴露者 (E) 可以直接传播谣言,怀疑者 (D) 不直接传播。
◦只考虑积极感染者 (P) 和消极感染者 (N),忽略其他状态。
◦模型参数取值如下:
β1 = 0.2 (暴露者转化为积极感染者的速率)
β2 = 0.1 (暴露者转化为消极感染者的速率)
r1 = 0.1 (积极感染者转化为受限者的速率)
r2 = 0.05 (消极感染者转化为受限者的速率)
构建下一代矩阵 (F)
•下一代矩阵 F 描述了新的感染者如何产生。在这个简化模型中,只有暴露者 (E) 可以产生新的积极感染者 (P) 和消极感染者 (N)。因此,矩阵 F 可以表示为:
•在这个矩阵中:
第一行表示暴露者 (E) 如何产生新的积极感染者 (P)。由于只有暴露者可以直接转化为积极感染者,所以 (E, P) 对应的元素是 β1。
第二行表示暴露者 (E) 如何产生新的消极感染者 (N)。由于只有暴露者可以直接转化为消极感染者,所以 (E, N) 对应的元素是 β2。
其他元素为 0,表示其他状态不能直接产生新的感染者
构建恢复率的对角矩阵 (V)
恢复率矩阵 V 描述了感染者如何从感染状态中移除。在这个简化模型中,积极感染者 (P) 和消极感染者 (N) 会转化为受限者 (R)。因此,矩阵 V 可以表示为:
在这个矩阵中:
(P, P) 对应的元素是 r1,表示积极感染者转化为受限者的速率。
(N, N) 对应的元素是r2,表示消极感染者转化为受限者的速率。
其他元素为 0,表示感染者只能通过转化为受限者移除。
计算
表示下一代矩阵 F 与恢复率矩阵 V 的逆矩阵的乘积。首先,我们需要计算 V 的逆矩阵 V-1:
然后,计算
计算
特征值为 λ1 = 0 和 λ2 = 0. 因此, 谱半径 ρ(
在这个案例中,β1/r1 = 0.2 / 0.1 = 2, β2/r2 = 0.1 / 0.05 = 2. 因此,R0 = 2.
模型的正性和有效性 (Positivity and validity of the model)
重要性:确保模型与自然规律的兼容性。由于模型监测的是各类人群,因此必须证明所有系统参数都是非负的。
定理 2:如果 (s, e, d, p, n, r) ∈ R6 且 s(0) > 0, e(0) > 0, d(0) > 0, p(0) > 0, n(0) > 0 且 r(0) > 0,那么模型的所有解 s(t), e(t), d(t), p(t), n(t), r(t) 对于所有 t > 0 都是正的.
定理 3:如果 (S(0),E(0),D(0),P(0),N(0),R(0)) > 0,则系统解 S(t), E(t), D(t), P(t), N(t), R(t) 对于 t > 0 是非负的
证明:通过反证法证明,假设存在 t0 ∈ (0, t1) 使得 S(t), E(t), D(t), P(t), N(t), R(t) 中的任何一个是负的,则会导致矛盾,从而证明解的非负性.
核心概念:模型的正性和有效性
正性 (Positivity):指的是模型中所有变量的取值都大于等于零。在SEDPNR模型中,这意味着各个状态(S、E、D、P、N、R)的人数都不能是负数,因为现实世界中不可能存在负数的人。
有效性 (Validity):指的是模型在数学上和逻辑上是合理的,能够准确地描述现实世界中的现象。在SEDPNR模型中,这意味着模型的各个方程能够正确地反映人群在不同状态之间的流动规律。
案例背景:社交网络中的“食品安全”谣言
假设在一个有1000人的社交网络中,出现了一条关于某种“食品安全”的谣言,声称某种食品含有致癌物质。我们想用SEDPNR模型来分析这条谣言的传播情况。人群被分为以下几个状态:
S (Susceptible, 易感者):还没接触过谣言的人。
E (Exposed, 暴露者):已经接触过谣言,但还没决定是否相信的人。
D (Doubter, 怀疑者):对谣言持怀疑态度的人。
P (Positively Infected, 积极感染者):积极相信并传播谣言的人。
N (Negatively Infected, 消极感染者):不相信谣言,并且可能辟谣的人。
R (Restrained, 受限者):已经对这个谣言失去兴趣,不再传播的人。
正性的重要性:确保结果符合现实
如果SEDPNR模型不满足正性,那么在模拟过程中可能会出现以下情况:
某个状态的人数变成负数,例如 S(t) < 0,这意味着“有负数个还没接触过谣言的人”,这显然是不可能的。
模型给出的结果与实际情况不符,例如模型预测积极感染者的人数会超过总人口数,这也会导致模型失效。
因此,模型的正性是确保模型结果具有实际意义的前提。定理2和定理3就是用来证明SEDPNR模型满足正性的。定理2表明,如果初始状态各个状态人数为正,那么模型在任何时间点计算出的各个状态的人数也都是正的。定理3用反证法证明了SEDPNR模型各个状态人数非负.
有效性的重要性:确保模型能够准确描述现象
如果SEDPNR模型不满足有效性,那么模型可能无法准确地描述谣言在社交网络中的传播规律,例如:
模型假设“暴露者一定会转化为感染者”,但实际上有些人可能会直接变成怀疑者。
模型忽略了“人们可能会因为看到官方辟谣信息而改变观点”,导致模型预测的感染人数偏高。
因此,模型的有效性是确保模型能够准确预测和分析现象的前提。为了提高SEDPNR模型的有效性,我们需要:
仔细选择模型参数:根据实际情况调整模型参数,例如传播速率、恢复速率等,使模型更好地拟合真实数据。
考虑更多的影响因素:在模型中加入更多的影响因素,例如社交网络结构、用户信息特征等,使模型更加完善。
案例:验证模型的正性和有效性
设置初始状态:假设一开始有990个人是易感者,5个人是暴露者,3个人是怀疑者,1个人是积极感染者,1个人是消极感染者,没有人是受限者。即 S(0) = 990, E(0) = 5, D(0) = 3, P(0) = 1, N(0) = 1, R(0) = 0。
运行模型:使用SEDPNR模型进行模拟,观察各个状态的人数随时间变化的情况。
验证正性:确保在模拟过程中,所有状态的人数都大于等于零。如果出现负数,则说明模型不满足正性,需要进行调整。
验证有效性:将模型预测的结果与实际观测数据进行比较,例如通过调查问卷或社交媒体数据分析,了解实际的谣言传播情况。如果模型预测结果与实际情况相符,则说明模型具有一定的有效性。如果不符,则需要调整模型参数或加入更多的影响因素,重新进行验证。
模型的稳定性及谣言消亡或持续存在的条件 (Stability of the model and conditions under which the rumor dies or persists indefinitely)
线性化系统:通过在暴露人数为零的稳定状态附近线性化微分方程组来研究模型的稳定性
特征值分析:利用特征值 (eigenvalues) 来确定系统的稳定性。如果所有特征值都具有负实部,则系统是稳定的,谣言最终会消亡;如果至少一个特征值具有正实部,则谣言会无限期地持续存在,表明系统不稳定.
稳定条件:推导出谣言最终消亡的条件,即所有三个特征值均为负值.
核心概念:模型的稳定性
稳定性指的是,当系统(在本例中是谣言传播模型)受到轻微扰动后,其状态是否会回到平衡点。如果系统在受到扰动后能够回到平衡点,则称该系统是稳定的;反之,如果系统在受到扰动后偏离平衡点越来越远,则称该系统是不稳定的;
在SEDPNR模型中,稳定性意味着,在初始状态发生微小变化后,各个状态(S、E、D、P、N、R)的人数最终是否会趋于一个稳定的数值。
核心概念:谣言消亡或持续存在的条件
谣言消亡:指在一定时间后,积极感染者(P)和消极感染者(N)的数量都趋近于零,即谣言不再传播。
谣言持续存在:指积极感染者(P)和消极感染者(N)的数量维持在一个较高的水平,即谣言持续传播
案例背景:社交网络中的“健康秘诀”谣言
假设在一个有1000人的社交网络中,出现了一条关于“健康秘诀”的谣言,声称某种未经科学证实的偏方可以显著提升免疫力。我们想用SEDPNR模型来分析这条谣言的传播情况。人群被分为以下几个状态:
S (Susceptible, 易感者):还没接触过谣言的人。
E (Exposed, 暴露者):已经接触过谣言,但还没决定是否相信的人。
D (Doubter, 怀疑者):对谣言持怀疑态度的人。
P (Positively Infected, 积极感染者):积极相信并传播谣言的人。
N (Negatively Infected, 消极感染者):不相信谣言,并且可能辟谣的人。
R (Restrained, 受限者):已经对这个谣言失去兴趣,不再传播的人。
基本再生数 (R0)
基本再生数(R0)是判断谣言能否传播的关键指标。如果R0 < 1,表示平均每个感染者感染的人数少于1个,谣言最终会消亡。如果R0 > 1,表示平均每个感染者感染的人数多于1个,谣言可能会持续传播.
模型参数与谣言传播
传播速率(β1,β2,β3,β4):传播速率越高,谣言越容易从暴露者(E)或怀疑者(D)传播到积极感染者(P)和消极感染者(N),导致更多人相信和传播谣言;
恢复速率(γ1,γ2):恢复速率越高,积极感染者(P)和消极感染者(N)越容易转化为受限者(R),即停止传播谣言,从而抑制谣言的传播;
易感者转化为暴露者的速率(α):如果α 较高,意味着更多人会接触到谣言,从而增加谣言传播的可能性
怀疑者比例:如果社交网络中存在大量怀疑者(D),他们会质疑信息的真实性,从而减缓谣言的传播速度;
案例分析:谣言消亡的条件
假设参数设置:假设“健康秘诀”谣言的传播速率较低,β1 = 0.1,β2 = 0.05,而恢复速率较高,γ1 = 0.5,γ2 = 0.4。这意味着人们不太容易相信和传播谣言,而更容易对谣言失去兴趣。
计算R0:根据公式计算出R0 < 1。
模型预测:通过SEDPNR模型进行模拟,预测结果显示,在一段时间后,积极感染者(P)和消极感染者(N)的数量都趋近于零,而受限者(R)的数量逐渐增加。
结论:在这种情况下,由于传播速率较低,恢复速率较高,R0 < 1,因此谣言最终会消亡。
案例分析:谣言持续存在的条件
假设参数设置:假设“健康秘诀”谣言的传播速率较高,β1 = 0.8,β2 = 0.6,而恢复速率较低,γ1 = 0.1,γ2 = 0.05。这意味着人们很容易相信和传播谣言,而很难对谣言失去兴趣。
计算R0:根据公式计算出R0 > 1。
模型预测:通过SEDPNR模型进行模拟,预测结果显示,积极感染者(P)和消极感染者(N)的数量维持在一个较高的水平,而受限者(R)的数量增长缓慢。
结论:在这种情况下,由于传播速率较高,恢复速率较低,R0 > 1,因此谣言会持续存在。
干预措施的影响
提高恢复速率:通过官方辟谣、媒体宣传、专家解读等方式,提高人们对谣言的辨别能力,促使更多人从感染状态转化为受限状态,从而降低R0,促使谣言消亡。
降低传播速率:通过限制谣言信息的传播范围、封禁传播谣言的账号等方式,降低谣言的传播速率,从而降低R0,促使谣言消亡。
增加怀疑者比例:通过提高公众的科学素养、鼓励独立思考等方式,增加社交网络中怀疑者(D)的比例,从而减缓谣言的传播速度.
其他分析
误导信息和不信任的影响:模型可以扩展到包括与信息共享和信任相关的特征,以检验虚假信息和对公共卫生机构的不信任对谣言传播的影响。例如,可以通过调整转移概率来考虑虚假信息对谣言易感性的影响,或者创建一个新的状态来表示不信任公共卫生机构的人.
平衡点 (Equilibrium points):通过将微分方程组中所有变化率设置为零,然后求解得到的方程组来确定平衡点。平衡点代表系统中的稳定状态.
Lyapunov 稳定性:通过引入 Lyapunov 函数并证明其沿系统轨迹的单调性,来确定SEDNPR 模型的全局渐近稳定性.
总而言之,模型的属性部分通过数学分析,验证了SEDPNR模型的有效性和稳定性,并探讨了影响谣言传播的关键因素。这些分析为后续的模拟和干预策略的制定奠定了基础.
Ethical Considerations
隐私、透明度和数据保护:
所有的数据收集活动,包括调查和社交网络站点的文本挖掘,都必须严格遵守隐私法律。
用户的匿名性和知情同意应是首要考虑事项。
在模型的开发和应用中,确保透明度至关重要,这包括记录模型的假设、局限性和潜在的偏见。
模型预测应该是可解释的,让用户能够理解其输出结果背后的推理。
模型的潜在误用:
SEDPNR模型是一个理解错误信息传播的强大工具,但必须考虑该模型可能被误用的方式。
例如,该模型可能被用于识别和定位特定群体,并对其发起有针对性的错误信息宣传活动,从而加剧问题。
社会责任:
研究人员有责任为了社会利益而使用他们的研究成果。
SEDPNR模型应该被用于制定减少错误信息传播的策略,而不是用于放大它。
与政策制定者和社交媒体平台合作对于确保该模型的合乎道德的应用至关重要。
Analysis of the model
使用R语言进行分析
该论文使用R语言进行计算分析,R语言是一个开源语言,拥有活跃的开发者社区支持其发展。
基于算法1(SEDPNR模型算法),使用随机概率值对一个包含20万个体的样本群体进行了计算模拟。
模拟假设负面情绪的谣言比正面情绪的谣言传播得更广。
图3展示了基于数学定义和算法1的SEDPNR模型在100天内的模拟结果。
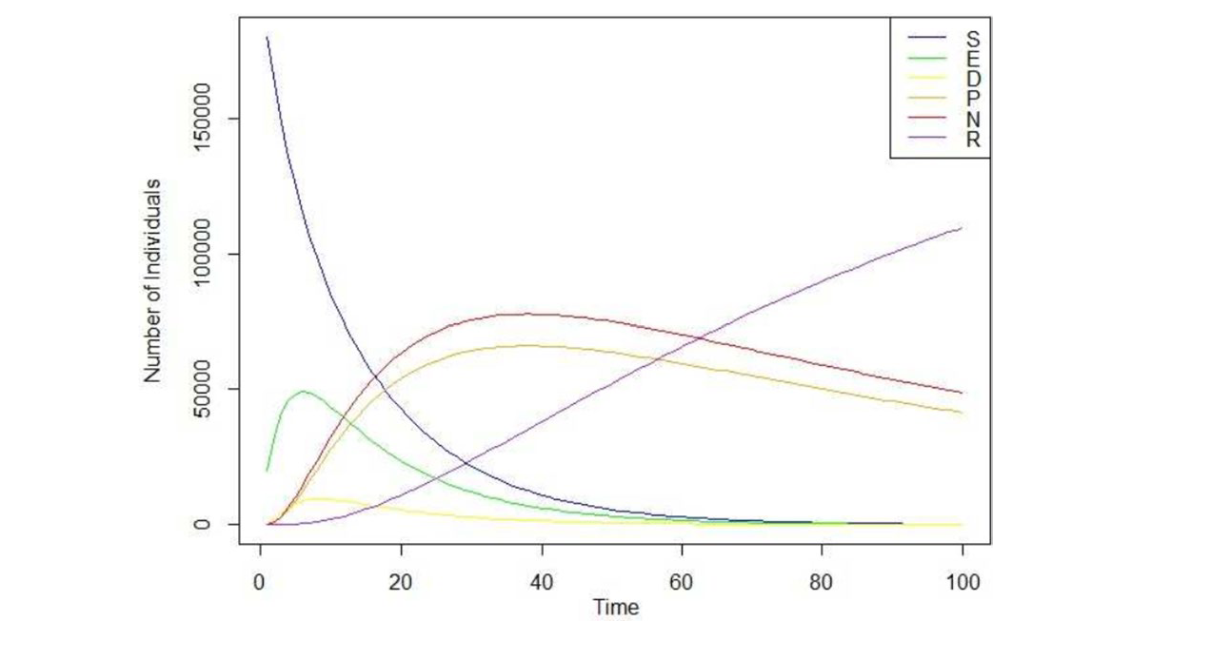
幂律性质的识别
从图3可以看出,易感人群和感染人群在图上呈现出幂律性质。
幂律分布表明网络中存在超级传播者和不活跃人群。
幂律描述了社交网络成员之间的连接是如何分布的。少数节点(通常是知名和有影响力的人)拥有大量的连接,而其余节点连接相对较少。
网络中连接的分布方式会影响谣言的传播。连接更多的节点可以作为超级传播者,将信息快速传播给大量受众。
真实世界数据分析
论文参考了以往的研究,这些研究使用SIR模型进行刚度分析,以预测特定国家社交网络中虚假新闻的传播。
使用互联网普及率指数(i)和人类发展指数(HDI)来评估全球社区的社会、经济和文化表现。
定义了恢复率(φ)感染率(ω),并通过公式与i和HDI相关联。
φ = i/10
ω = h/100
通常φ小于ω,因为传播虚假内容比强化真相更容易;
表1展示了美国、印度和尼日利亚这几个高、中、低HDI国家在2022年的φ和ω值:
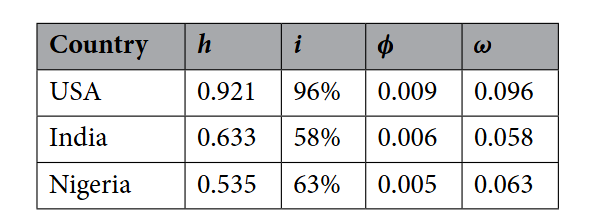
图4报告了每个国家易感人群和感染人群(包括积极感染节点和消极感染节点)的比例,假设每个国家社区规模为10万人,并假设初始状态下99.9%的人口为易感者,没有受限者。分析周期为500天。
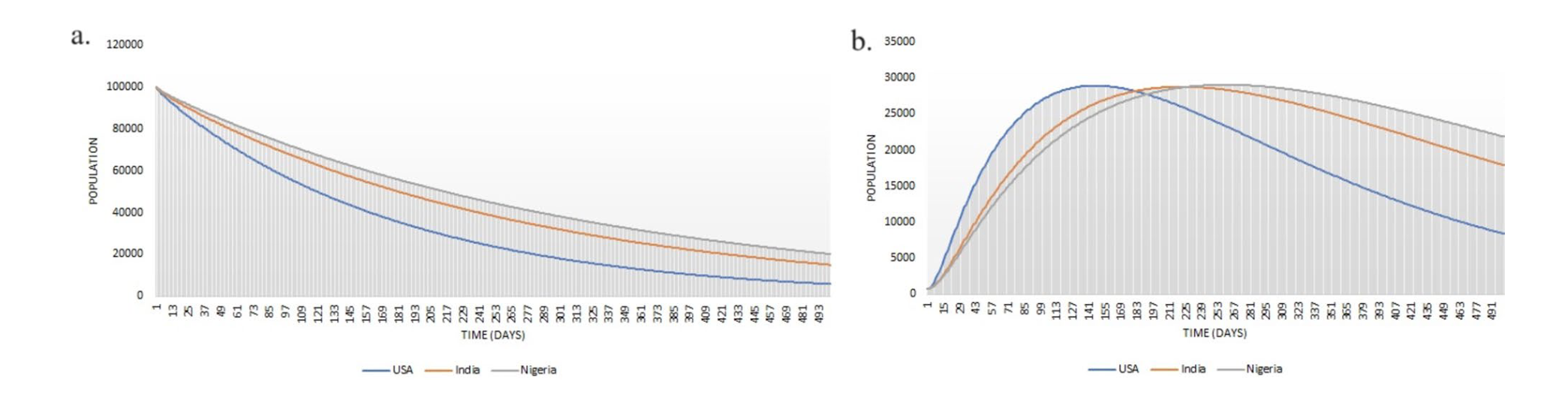
Susceptible (a) and infected population (b) with values of 2022 on 100,000 individuals.
对图4中错误信息趋势的分析表明,对于互联网普及率相对较高但HDI值较低的国家,迫切需要在数字网络中建立可持续且有效的干预机制,以压缩虚假新闻和错误信息。
案例研究:科钦(Kochi)火灾事件
图5展示了SEDPNR模型对印度喀拉拉邦科钦的Brahmapuram火灾事件期间感染率的拟合情况。
数据来自2023年3月1日至4月2日期间所有关于该事件的推文(基于主题标签和关键词)
X轴表示每日推文数量,Y轴表示事件的时间线.。
该图说明了四个关键指标:积极感染率(蓝线)、消极感染率(橙线)、总感染率(灰线)以及SEDPNR模型预测的预期感染率(黄线)
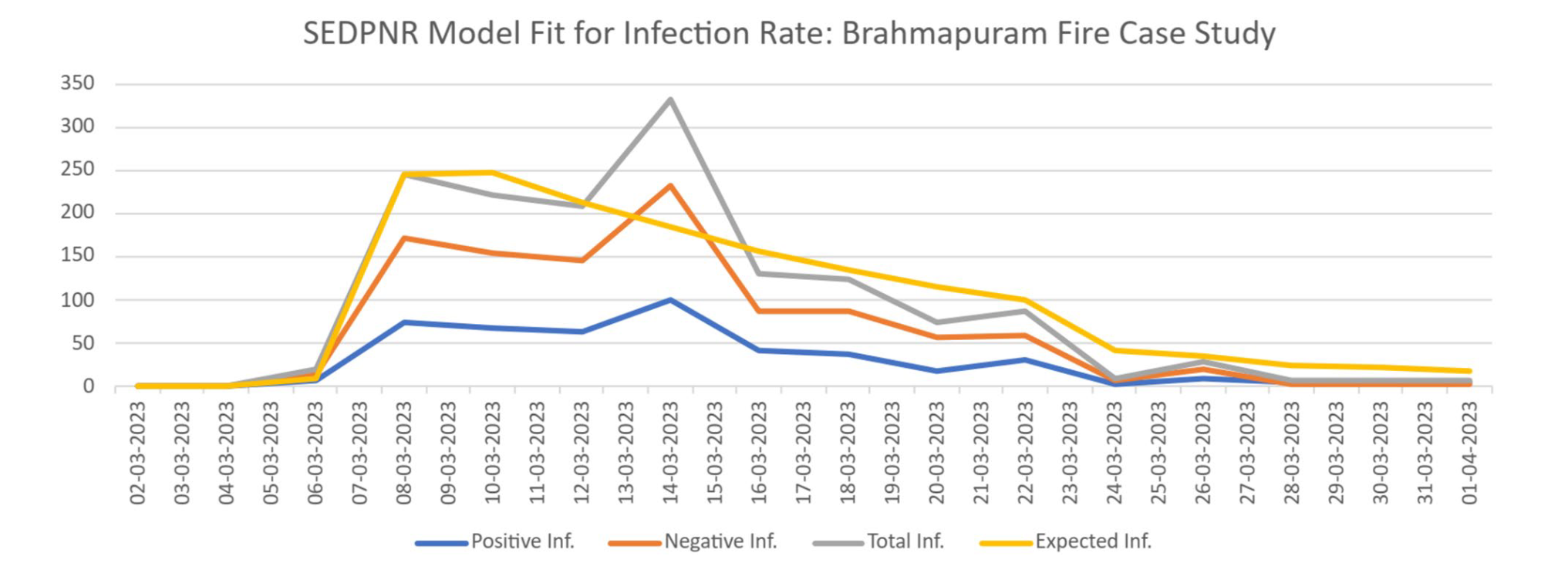
数据揭示,从3月7日至8日左右开始,推文活动突然激增,这与Brahmapuram垃圾处理厂发生火灾的时间相吻合7。最初的激增可能代表着火灾消息爆发时信息的快速传播。
在3月14日至15日观察到总感染率的显著峰值,这与该地点的二次火灾爆发相对应。
在整个事件中,负面情绪(橙线)通常超过正面情绪(蓝线),这可能反映了公众对火灾对环境和健康影响的担忧和批评。
峰值过后,所有类别的感染率都逐渐下降,表明公众兴趣减退,或者火灾情况可能得到了控制。
预期感染率(黄线)与总感染率(灰线)拟合得相当好,尤其是在捕捉整体趋势和显著波动方面。
但注意到一些差异,尤其是在3月14日至15日峰值附近,这可能归因于二次火灾爆发的意外性质。
该案例研究强调了SEDPNR模型在预测局部环境危机期间信息传播总体趋势方面的强大能力。
危机时期的情绪分析
研究表明,与危机前相比,危机期间或危机后,社交网络中的负面情绪显著增加。
在塔利班控制阿富汗期间进行的分析也证明了这一点。
图6展示了在2021年9月塔利班控制阿富汗时,提取的4000条带有#taliban标签的随机推文的情绪分析结果。观察到显著占主导地位的负面情绪。
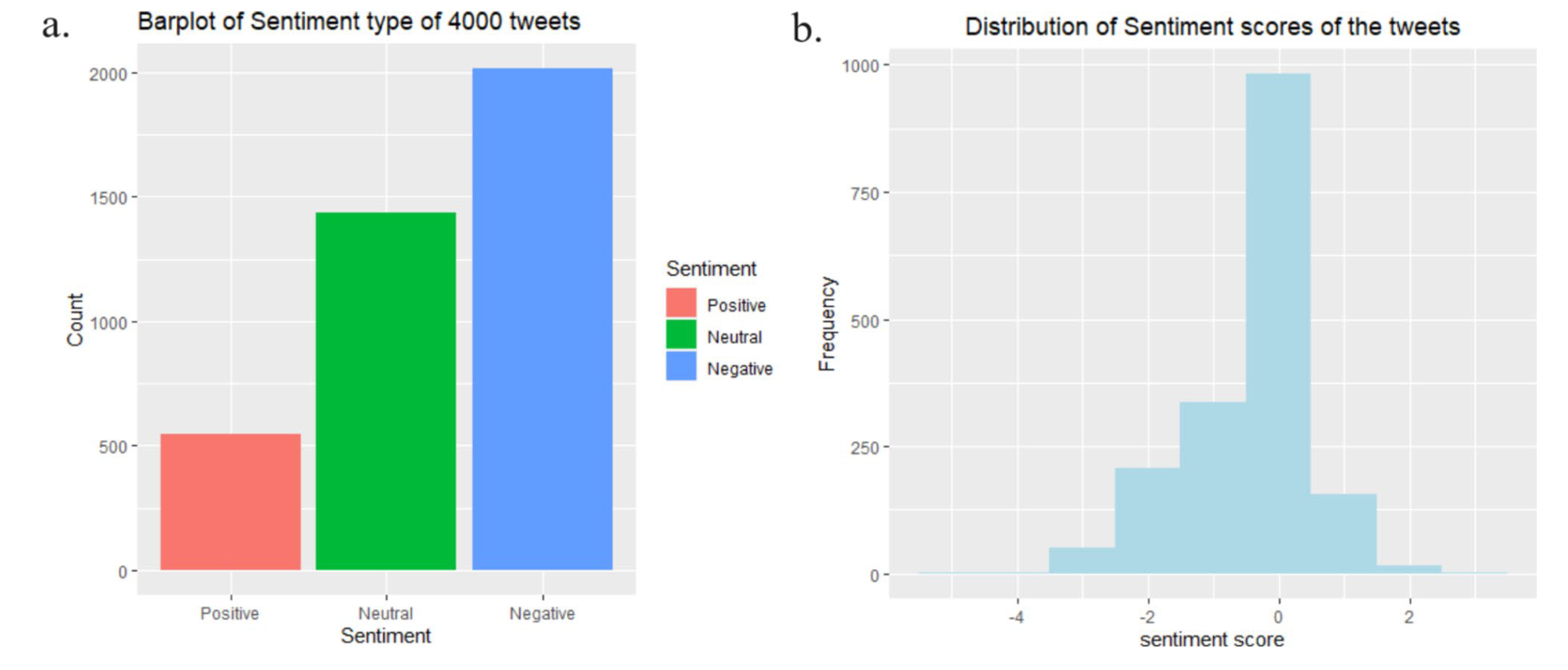
图6还显示了当巴基斯坦政府支持塔利班时,人们的反应情绪分析结果,他们表示已启动与塔利班的对话,以鼓励他们组建一个包容性政府。
即使这条消息带有积极/中性的语调,人们的反应也是消极的。这证明了在危机期间或当社区生活方式发生巨大变化时,负面情绪可能占主导地位。
Simulation results
模型参数的敏感性分析
该模型对控制信息流动的参数非常敏感。
α(个体接触到错误信息的速率) 稍微增加,都可能显著增加感染个体(Infected individuals)的数量,可能导致范围更大、速度更快的爆发;
例如,设置参数值为 α=0.1, γ=0.025, β1=0.05, β2 = 0.05, β3=0.05, β4=0.05, r1=0.035, r2 = 0.035, µ1 = 0.01, and µ2 = 0.1,初始状态 [S(0),E(0),D(0),P(0),N(0),R(0)] 时,总感染率的峰值为116,354(在第31步)
将 α 设置为更高的值(比如0.2)时,峰值感染率达到141,874(在第25步),表明感染率有所提高.
γ(成为怀疑者的速率) 和 β1, β2, β3, β4(成为感染者的速率) 的相对值至关重要。 如果γ接近感染率,则一个小的变化会显著影响怀疑者和感染者的数量。 相对于感染率,γ越高,爆发的可能性越小,因为会有更多的人变得易感.
正性和有界性
有界模型是指变量或解保持在有限范围内的模型。对参数的敏感性对于理解模型的行为和局限性至关重要。
更高的 α 值意味着错误信息传播得更快。 该模型对此参数非常敏感,α 的轻微增加会导致“积极感染”个体显著增加。 同样,更高的感染率值意味着更快的传播,反之亦然。 这意味着,在一个数据与社区利益相关联的社区中,错误信息可能传播得更快.
在模拟中,开发了两种情况进行分析。 两种模拟都从200,000的人口开始(表示为S(0) = 199,990)。
最初少量个体暴露(E(0) = 10)和怀疑(D(0) = 10),并且有相等数量的人倾向于对错误信息持有积极(P(0) = 5)或消极(N(0) = 5)的信念。 最初没有人被限制R(0) = 0。 更准确地说,可以说系统的初始状态为 [S(0),E(0),D(0),P(0),N(0),R(0)]T =[199, 990, 10, 10, 5, 5, 0]。 在第一种情况下,假设信息流动相对平衡。
这意味着人们接触到挑战错误信息的信息的速度与接触到错误信息来源的速度相似(由较低的 β 值表示:β1 = 0.075,β2 = 0.06, β3 = 0.075, β4 = 0.06
在第二种情况下,感染率重新设置为 β1 = 0.75, β2 = 0.6, β3 = 0.75 和 β4 = 0.6.
其余的系统参数和人口保持不变。 图7描述了在较低和增加的感染率下的模拟结果。 这些图表明所有子人口都是有界的,并且总人口为正。 在图7中,还可以观察到易感人群随着感染率的增加而迅速变为零值。 此外,“怀疑者”状态在一个感染率非常高的网络中变得不那么重要.
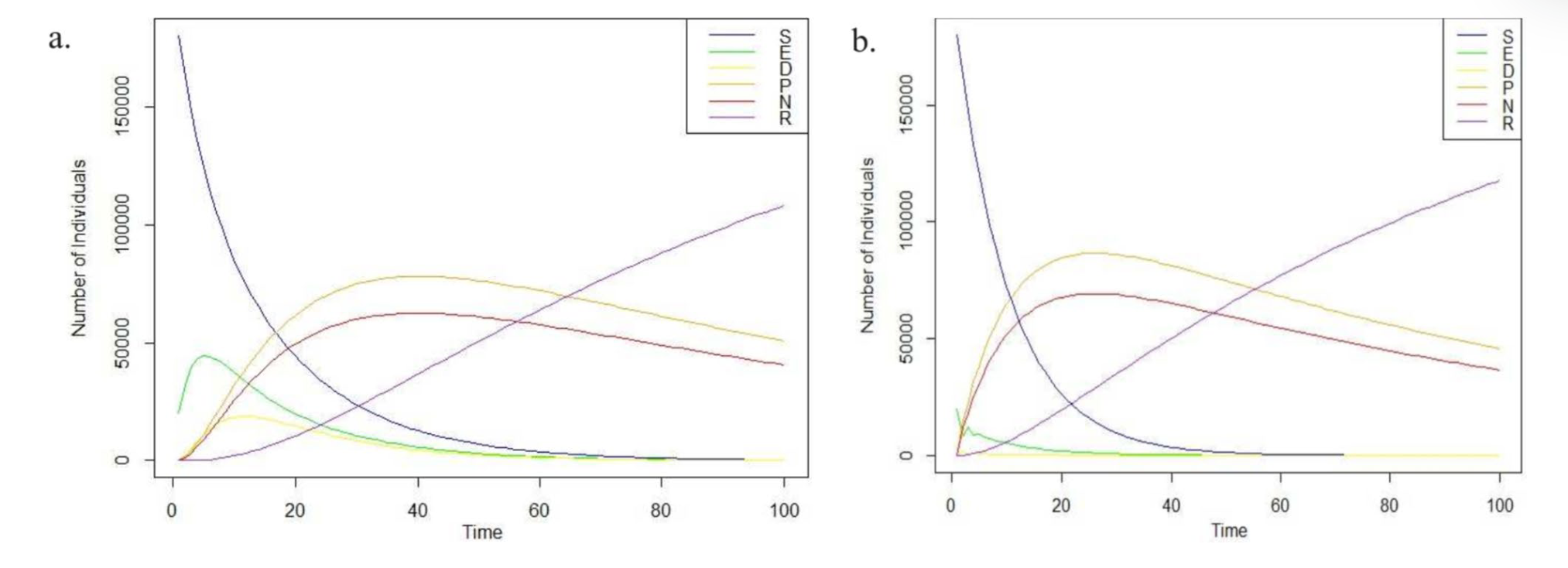
定理5 SEDPNR模型是有界的,并且该模型的总人口始终为正.
干预策略的评估
根据社交网络中错误信息传播的特点,通过增加对虚假新闻的筛选和切断感染源来控制错误信息和谣言是一种有效的技术。 像传染病一样隔离虚假新闻可以产生有益的结果。 隔离旨在防止虚假新闻暴露给其他人,并使内容远离弱势群体。 一旦实施隔离措施,系统模型参数将会减少.
在SEDPNR模型中评估干预策略具有重要意义。 通过在模型中复制它们的影响,可以更多地了解各种措施如何影响现实世界中虚假信息的传播。 这使社交媒体平台和政策制定者能够制定和执行更有效的计划,以应对虚假信息行动。 在SEDPNR模型中评估干预策略使我们能够超越简单地理解错误信息如何传播,从而积极探索减轻其影响的方法。 它为开发和测试可以对打击错误信息产生真正影响的策略提供了一个有价值的工具.

图8显示了使用SEDPNR模型进行的谣言传播,参数值为 α = 0.1, γ = 0.1, β1 = 0.5, β2 = 0.4, β3 = 0.5, β4 = 0.6, 1 = 0.01, 2 = 0.01, µ1 = 0.05, and µ2 = 0.05,初始状态设置为 [S(0),E(0),D(0),P(0),N(0),R(0)] = [199, 990, 10, 10, 5, 5, 0],在第一种情况下,假设没有采取任何干预措施。
在第二种情况下,对于相同的人口和传播速率,考虑从第10天开始持续30天的干预机制,这将感染率降低了25%。 从图中可以理解,如果不采取干预措施,错误信息会迅速传播,受影响人数会迅速达到峰值。 然而,一旦相关的政策制定者采取了必要的干预措施,将传播减少25%,传播就会大大减少。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









