









On Chip Bus —— 片上总线,AHB/AXI 无专利费

APB——早期
AHB——带宽要求不高的地方,MCU:cortex——M0/1/3/4——cpu出来使用AHB总线
AXI——带宽要求高的地方,Arm: A系列CPU,图像处理264等、CNN加速器、平板等
AXI总线——有一些定义好的模块/协议,对效率重要,使用时需要支持这些协议/模块



目录
5.4 AHB BURST PHASE 突发相位 — phase翻译为阶段!
0.前言
bus、ddr control、cache —— 大量应用数据需要ddr缓冲!大量数据都是从ddr中取出的 cache——加速
ddr 、 cache十分重要——因此需要了解其特性,让bus能够很好的配合!
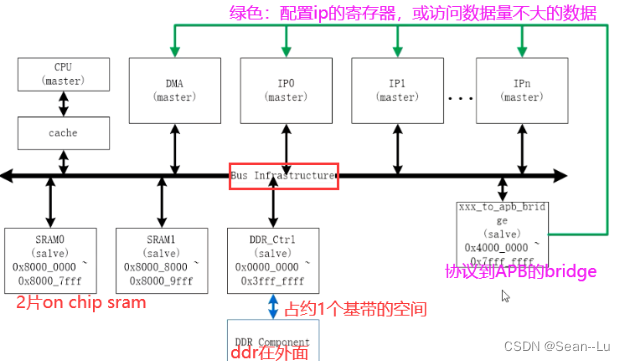
为什么需要芯片内部需要BUS连接?
1.标准化:统一标准/统一协议,接口协议不同会导致各个模块间无法连接
2.简化硬件设计
3.系统扩展性好:简化了功能增减,如增加一个master,修改总线即可
4.简化了系统结构:整个系统结构清晰,连线少
5.便于故障诊断和维护
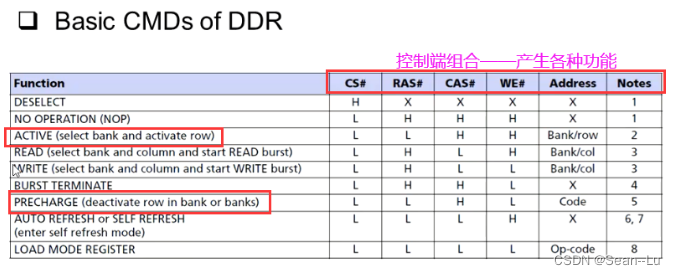
1.DDR行为介绍
1.1行为介绍
0.一次ddr访问需要发两次地址
1.在一个时间点看过去一次只能有一个bank的row打开——一次只能打开一个row(如row3)——需要访问别的row(如row8)——需要先pre charge掉row3,然后过一段时间发 bank0,row8,active指令访问row8
2.但是,有8个bank,每个bank是可以开一个row的,如 bank0-row8 同时还能打开 其他bank的一个row——如bank1-row100等等

refresh就是给DDR里面的电容重新上电,因为ddr掉电就会失去信息。
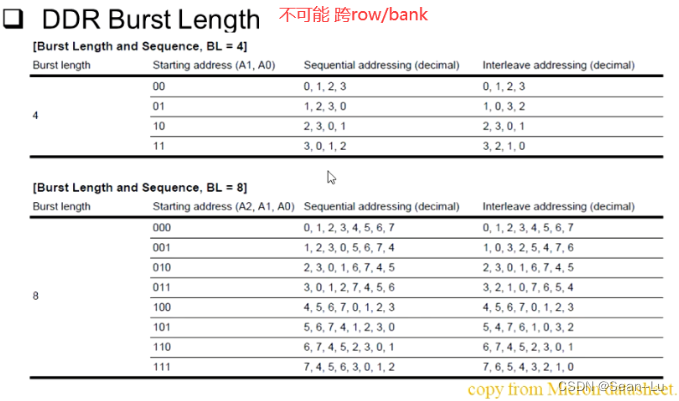
1.2 burst length
基本没有存储单个数据的操作,一般都是burst(比如L4 和 L8)——或者Teminal

1.3DDR的读/写波形
疑问:DDR的时钟频率那么快有啥用?act指令发出,需要花多个周期才能返回8个数据。然后又要precharge,act,存到下一个row——那真正用的不过30%的有效周期!?
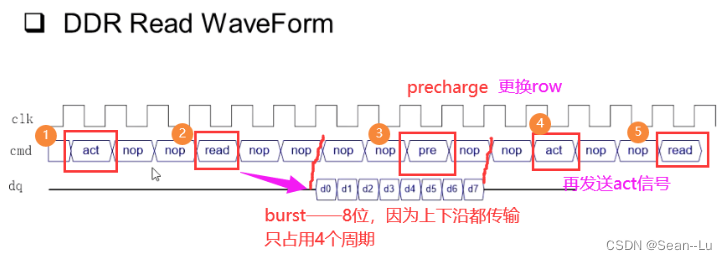
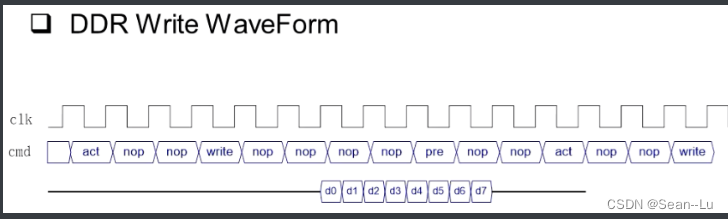
答:8个bank的指令是可以掺和在一起的!—— bank interleave
8组指令重叠起来,D - Q就很紧凑了。——指令是串行的
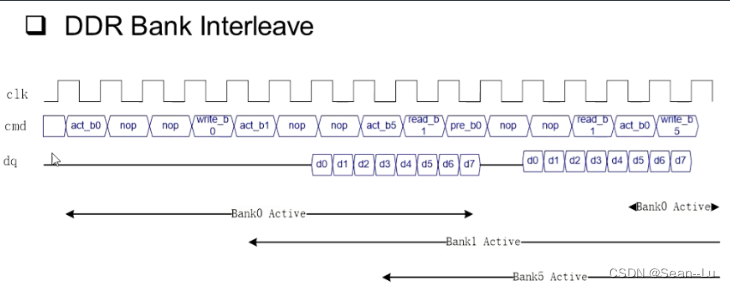
因此ddr对同一个bank不能连续发指令——需要隔几个周期——掺和在一起的指令 效率大概在50% - 80%之间
2.Cache
2.1Cache的位置与功能
有可能会hit——集中——降低cpu的访问、减少延时等等
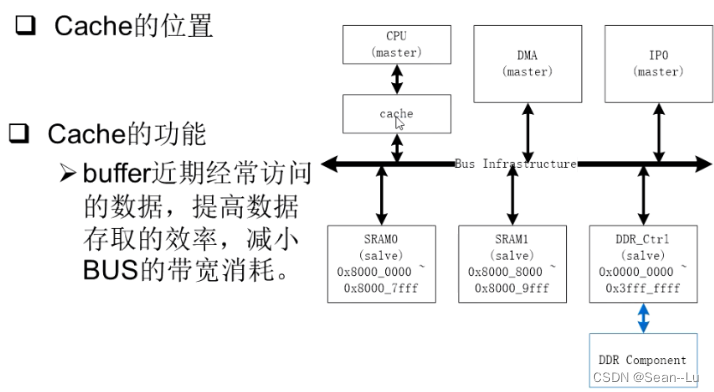
2.2 Cache的工作行为

为什么hit了,还需要write through?——因为这个数据很有可能是多个master共用的地址——不能抹除掉这个数据

invalidate——从微信,换到QQ,那之前的cache就没用了

2.3cache硬件原理
cache—主存映射地址(书P117 P122)
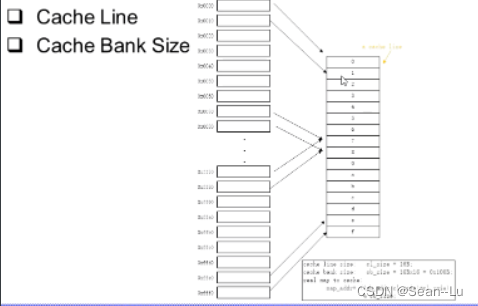
2way 当一个程序在一个小范围内跳时——2way hit能更多 现在一般至少 4way

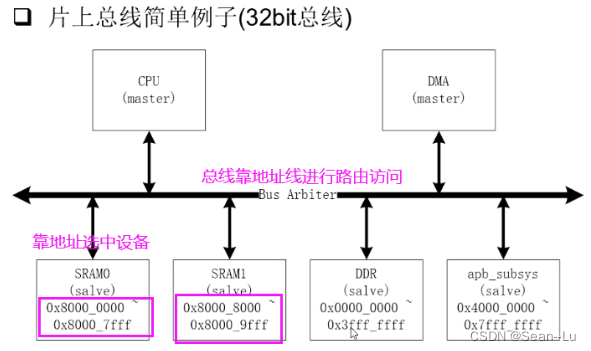
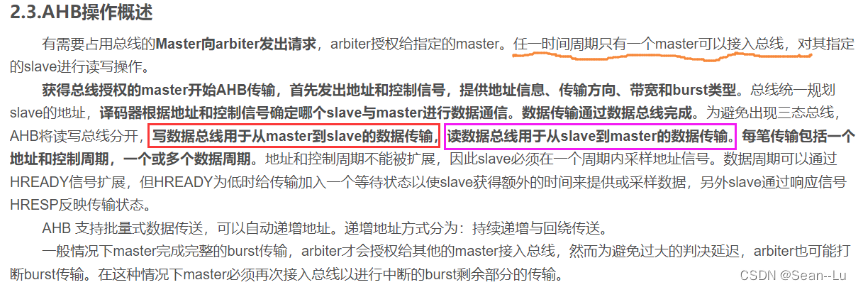
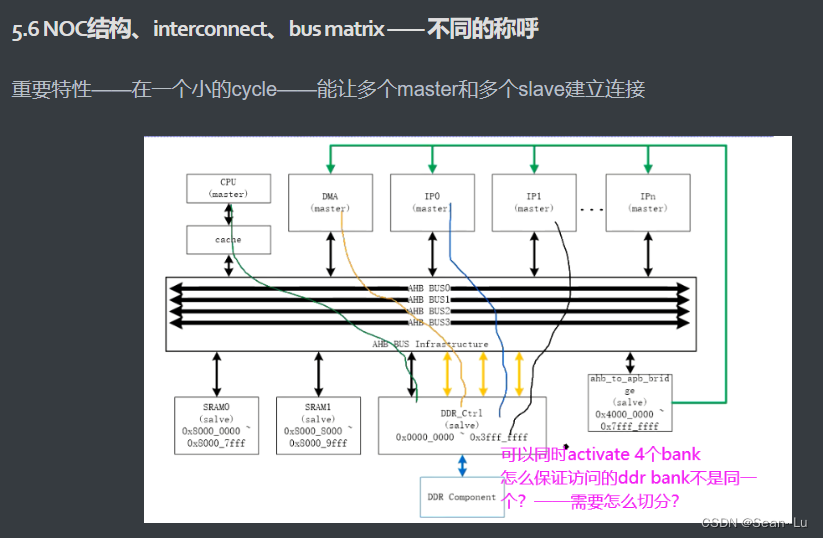
3.片上总线数据传输原理
3.1基础知识


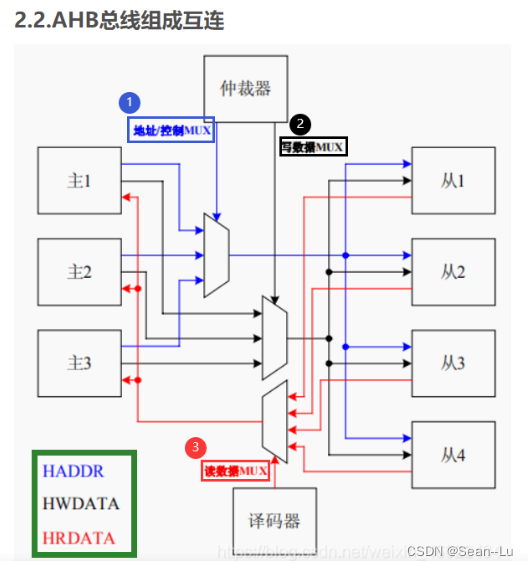
BUS Arbiter 仲裁器中——可以理解为存了一个路由表
3.2程序和BUS数据传输的关系(程序-硬件 的映射关系)
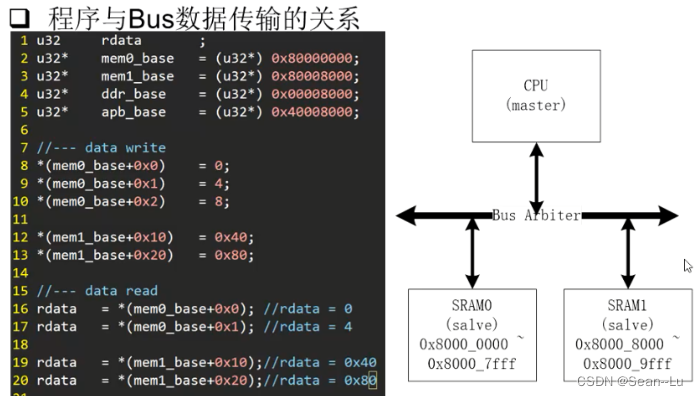
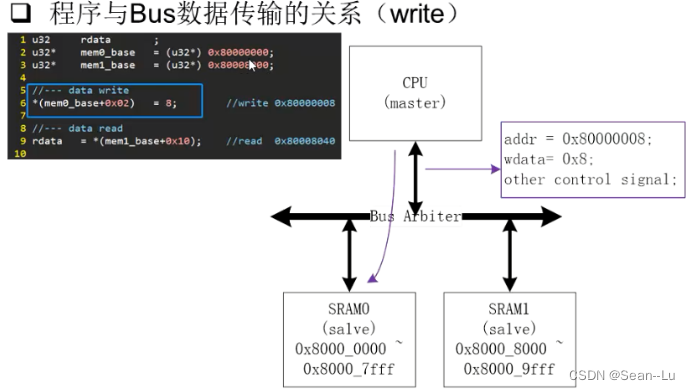
1.写
SRAM定义为8000_0000~8000_7fff,C语言的代码为:*(mem0_base + 0x02)= 8; 地址加2,然后写入一个数据8。
那么对应CPU就会在总线上发出地址:80000008,wdata 也是 0x8,还有一些其他的总线控制信息。 然后Bus Arbiter会找到响应的从机,将这些指令+数据 传输给 SRAM0
mem0_base = 80000000,为什么*(mem0_base + 0x02)出来的地址是80000008 ? 因为C语言的指针+2 —— 根据数据定义U32,+2 就是8个字节(+1个word 就是4个字节)
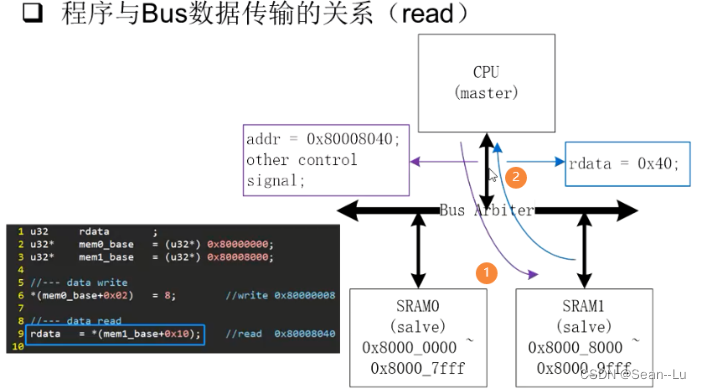
2.读
对于DMA也是一样——通过DMA的配置寄存器——配置DMA的source和目的地址destination address,当启动DMA请求的时候——DMA会在总线上将地址以及source都发出去——BUS arbiter同理会去查它的路由表——就可以选中对用的slave
3.在一个ip或slave内部,如何做?

4.Bus Arbiter的地址路由
大地址选择slave——用地址的高位
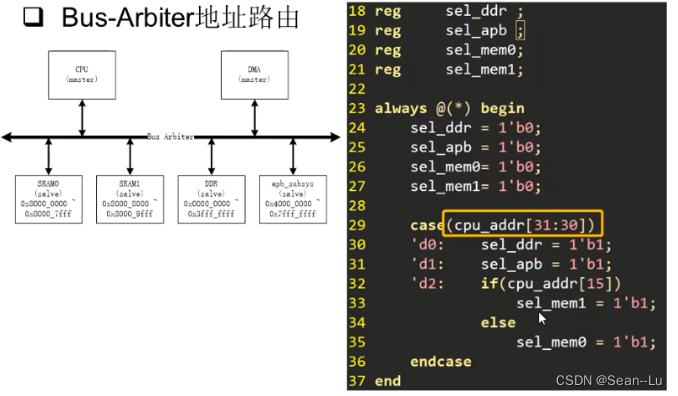
总结:一般用大地址用高位做译码——一般在slave的内部用地址的低位——选择内部的空间
问:如果CPU访问不存在的slave地址,会怎么样?
答:看arbiter的处理方式—可能返回bus error给CPU,最安全的做法,robust的系统——最好的做法。 或者写一个default——给一个数据黑洞——写进去,读出来固定0啥的——不太好,使用的人不清楚底层的情况。

4.APB总线介绍
4.1不带等待状态的写/读操作
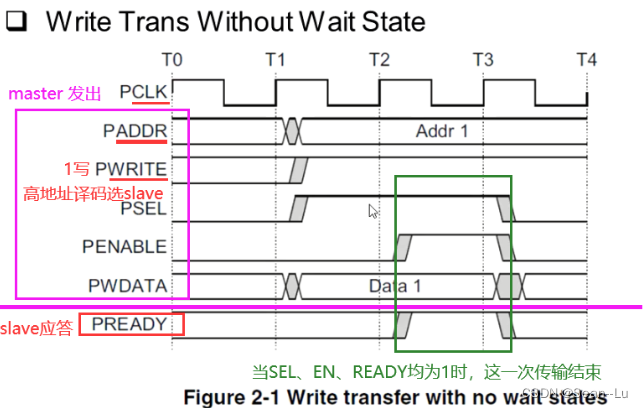
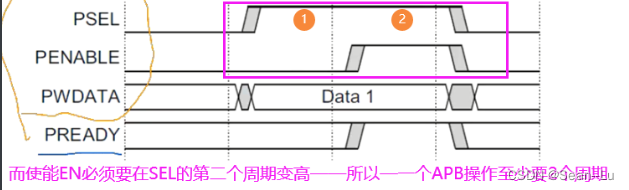
一个APB的操作至少要两个周期
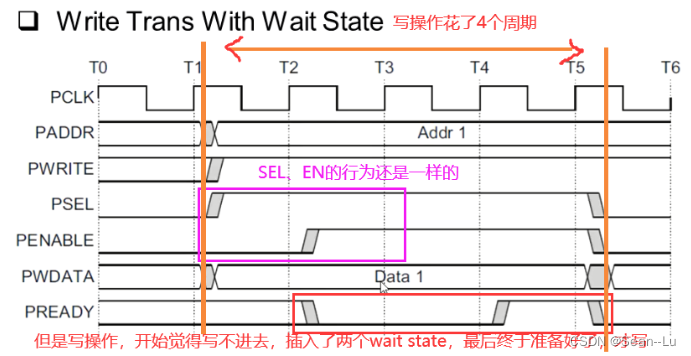
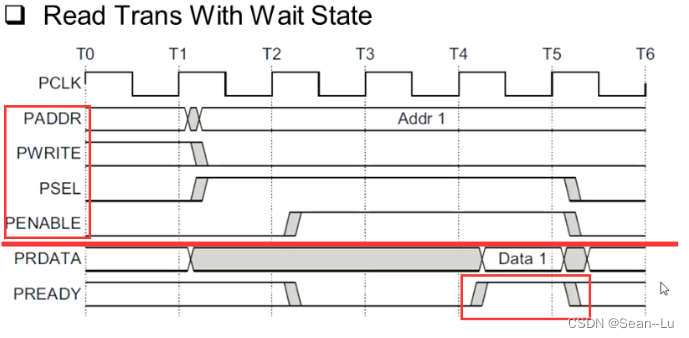
4.1带等待状态的写/读操作
写
规定:SELect有效的时候,address和write要有效,enable必须是在sel下一个周期才有效。然后从机salve可以插入很多的waite state,直到sel、enable、ready为1的时候,这次传输结束。
读
因为slave不能像下面这样直接能够读出数据
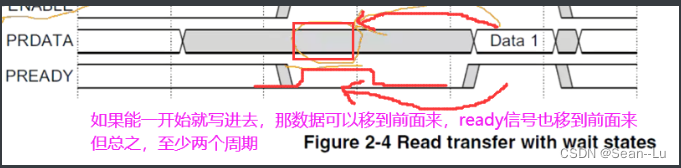
所以从机也是需要等待和准备,(上面是主机、下面是从机),PSEL PENABLE PREADY同时为1,读1bit数据结束。
定协议时就认为是个慢速协议——效率最多也就50%,就认为访问的慢速设备。
5.AHB总线介绍
5.1总线介绍
学到HREADY的理解那里卡住了——回顾:http://t.csdn.cn/gsGKE



视频笔记:
一个AHB的master,其所有的数据线基本分三组(除clk resn)。
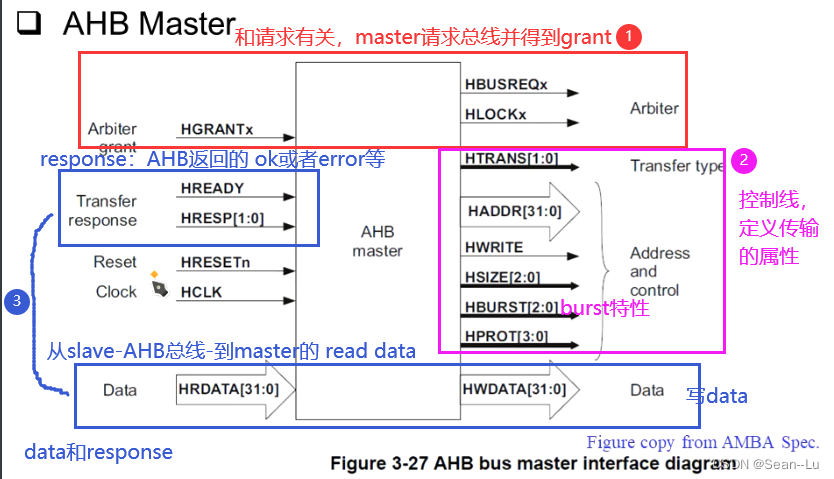
AHB slave
假设master3号发送burst,数据不够,那SPLITx【3】拉高——进行split操作。 HMASTER是4位——16个master——HSPLITx也是16位——对用16个主机的split
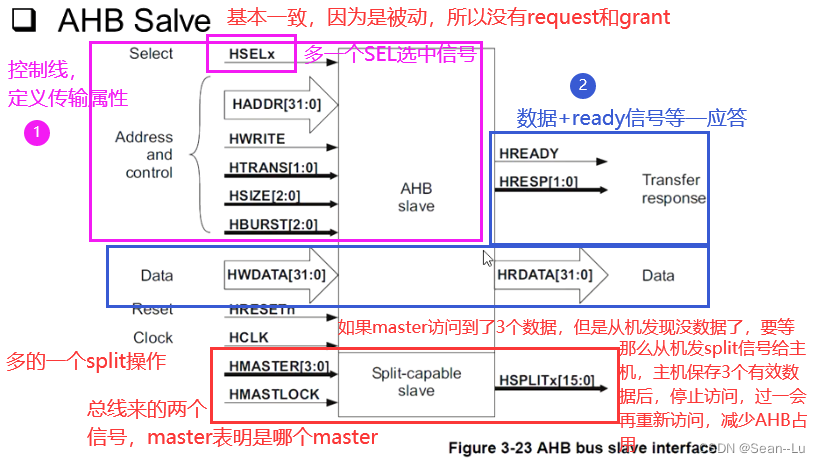
5.2AHB数据传输波形
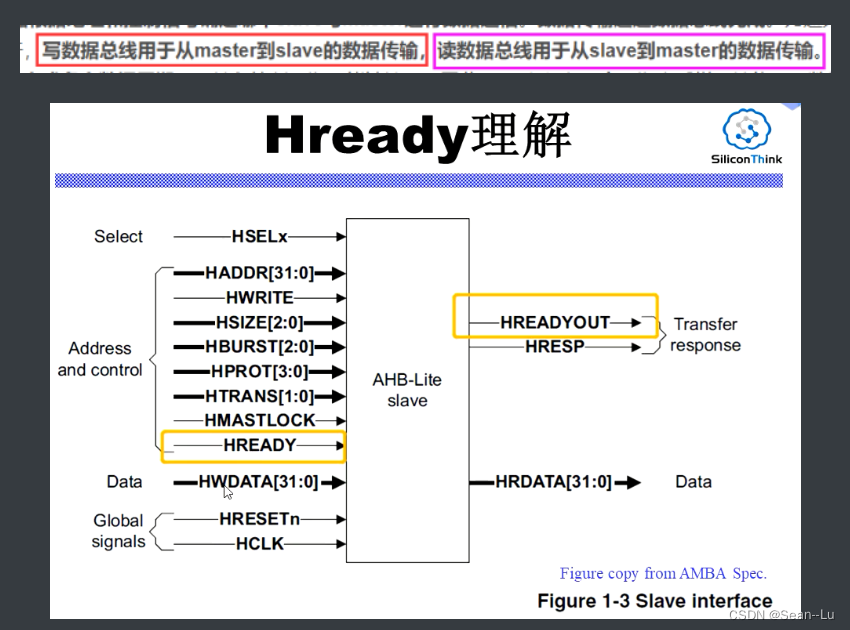
写是从主机发出信号——将数据写入从机 读也是是从主机发出信号——在从机中读出数据——slave需要hready信号说明准备好了数据?
5.3AHB的信号!!——HTRANS、HBURST等
HTRANS详解
①NONsequential、SEQUENTIAL:burst16,第一个永远是 nonsequential,后面接15个sequential
②IDLE:salve被选中——即AHB slave 把 grant信号给回了AHP master——但AHB master并没有主动请求访问数据,没有request——但grant来了,这个时候master就占有了总线——通常MASTER也没有应对这种自己没请求但是来了grant情况的功能——master自己也不想传数据,但master也得驱动整个模块的信号线——那就驱动信号线把HTRANS拉成IDLE信号——MASTER的独白:我不想传、我也没法request,但是grant给了我,总线被我占用了,那我就发IDLE
有可能master没有default的功能——可以做一个default master——当总线上 CPU 和 dma都没有请求占用AHB总线时——AHB master 将grant信号给到总线内部的default master——然后default master就一直发IDLE信号——即总线永远来当default master
或者总线把使用权在IDEL状态下时——绑定到某个master 如 CPU/DMA 总体而言——default master设置在 AHP MASTER 内部,兼容性更好,是最好的方案!
③BUSY:MASTER在发送数据的时候发现自己没有数据了——就发BUSY信号——等待后面的数据到了再发出去,发SEQUENTIAL操作,再把后面的数据传完
SLAVE靠HREADY来拖住总线传过来的数据——MASTER靠BUSY拖长总线的数据传输周期!


HSIZE编码
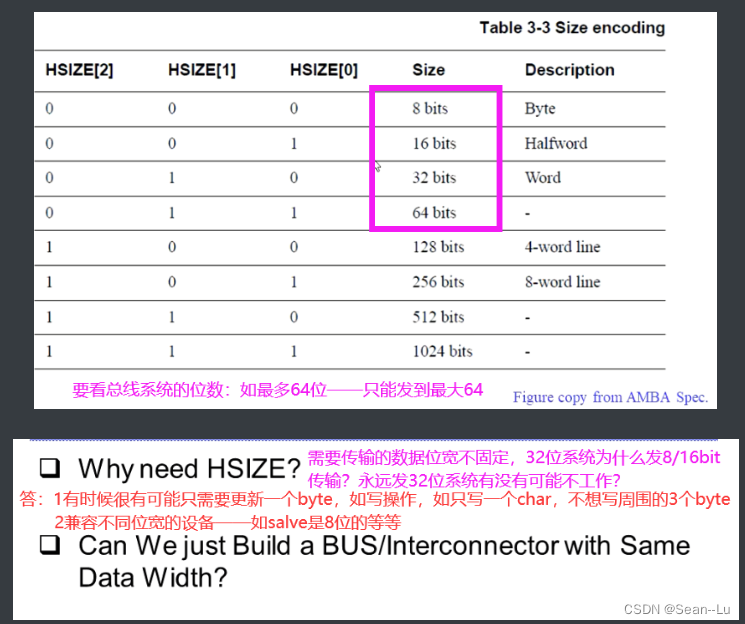
400M下那里错了,不是说256bit的AHB的HSIZE,是说——因为ddr3在不同的频率下——要用完它的资源需要的数据位宽不同——所以Hsize有多种的需求——适应不同的设备——即验证上图中的第二点!

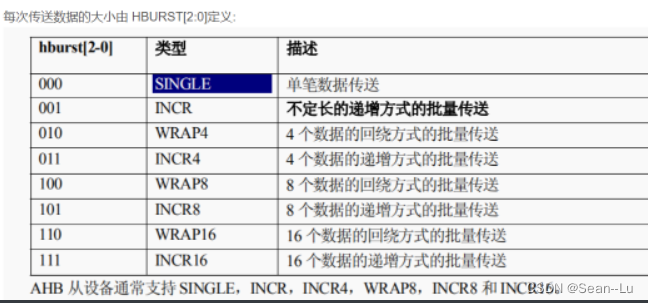
HBRUST
incrementing:从base地址一直上涨:4-8-... BURST——一次必须写入/读出 burst 定义的数据个数

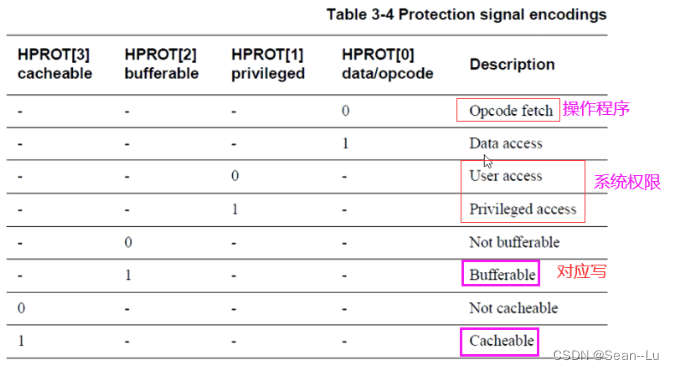
HPORT
bufferable——写——可以在bus中先缓存地址/数据——然后给回复master 已经准备好了 ready——然后master就直接发数据了——所以这里的ready信号并不是slave发送的 存在的问题:当终端回了error的时候——不太容易能发回到MASTER——稳健系统通常需要设置中断信号——存储信号并发给CPU!

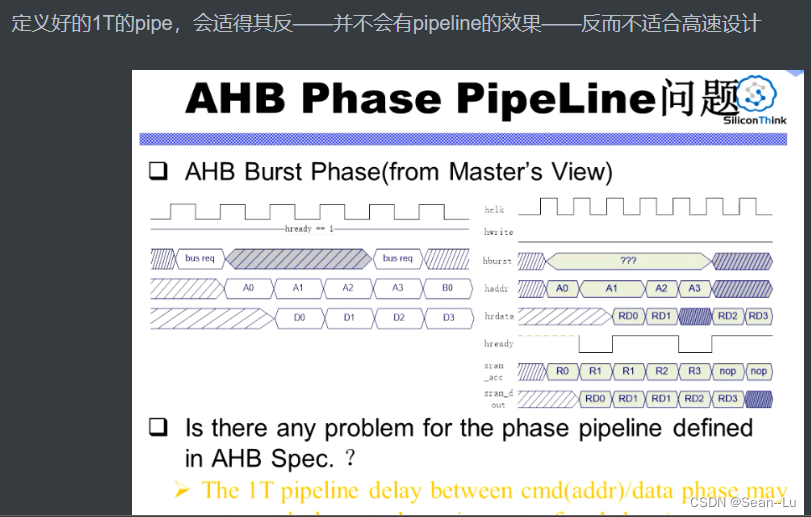
5.4 AHB BURST PHASE 突发相位 — phase翻译为阶段!
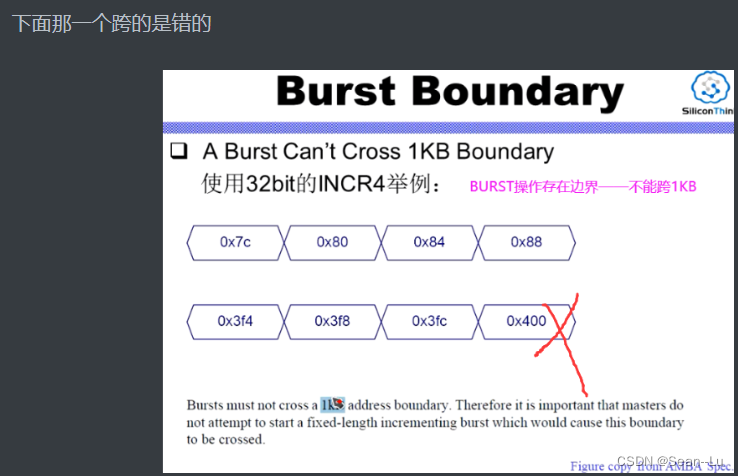
所以如果是incrementing的不定长模式,总线不知道master A要发多少个周期,就无法做到如图中的无缝切换,肯定会有周期的浪费——比如等到IDLE信号后——才开始切换——效率下降 所以不定长的慎用——虽然随便可以传几个数据——但对AHB不友好——效率下降

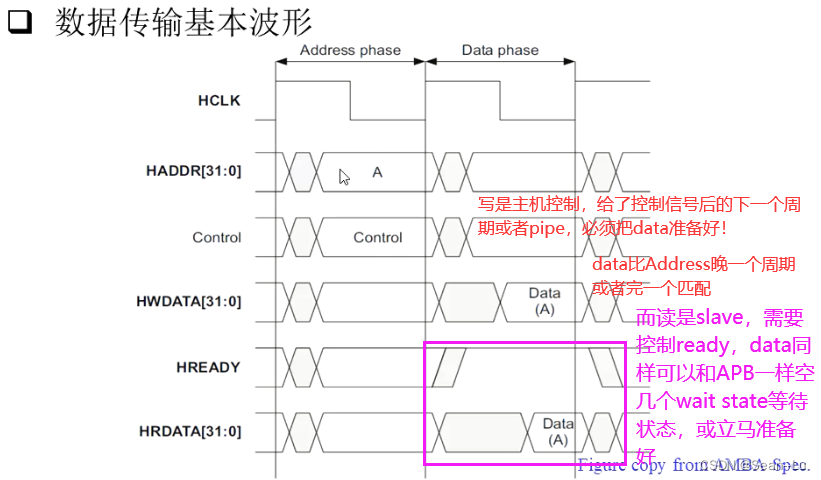
5.5AHB BUS Waveform 波形信号
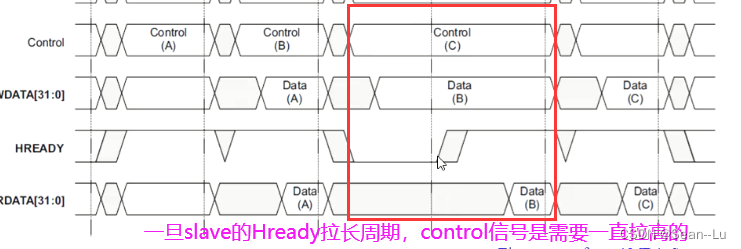
如果是写的波形——图中的HRDATA就不看;如果是读的波形——HWDATA就不用看。 slave的hready信号拉长周期,control 和 data 信号都得保持!
AHB协议的一个重点!——AHB协议的缺陷
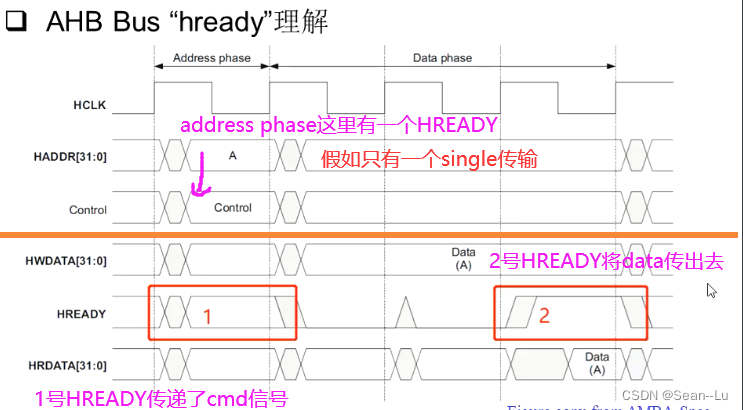
疑问:对与一个AHB,我只做一个single的传输,为什么要会两个HREADY?通常都是一个slave对应一个HREADY——如收一个数据就一个周期的HREADY,收4个数据就收4个周期的HREADY——为什么会出现两个HREADY?
答:HREADY其实是data对齐的!
对于2的HREADY——肯定是Address A 选中的 slave2回的 hready——对应数据DATA(A) 对于1——HREADY对应的是上一个地址选中的某个slave——对应数据(图中没有画出来)
那下面这里就反映了AHB协议的一个缺陷!
红框中——HREADY信号有效、此时的slave是B、此时的cmd是NONSEQ——意味着当NONSEQ信号发送到slave B的时候,HREADY信号还是slave A发出来的——从机B根本无法拒绝NONSEQ的控制信号,必须得收!——因为此时是A发出的HREADY
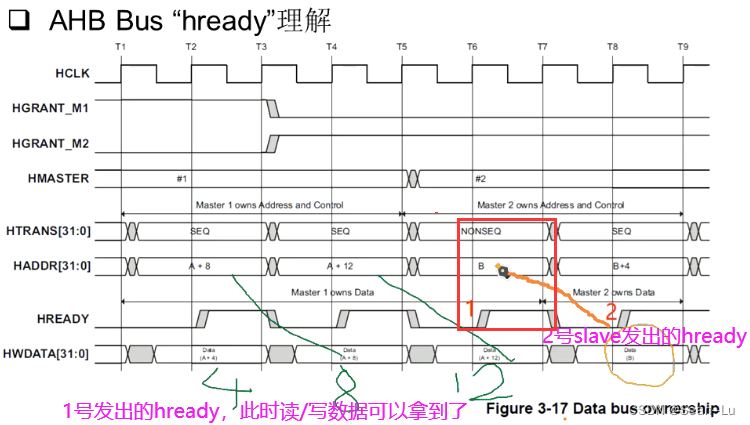
所以B用了A的HREADY抓了cmd信号,B它是无法控制的!到后面因为是自己回HREADY——就可以拒绝是否收某些控制信号对应的数据了。 问:如果SLAVE B在红框处——没有抓到第一个HREADY信号怎么办? 答:bug!这是必须遵守的协议!——用上一个slave的HREADY抓自己slave的第一个的cmd!


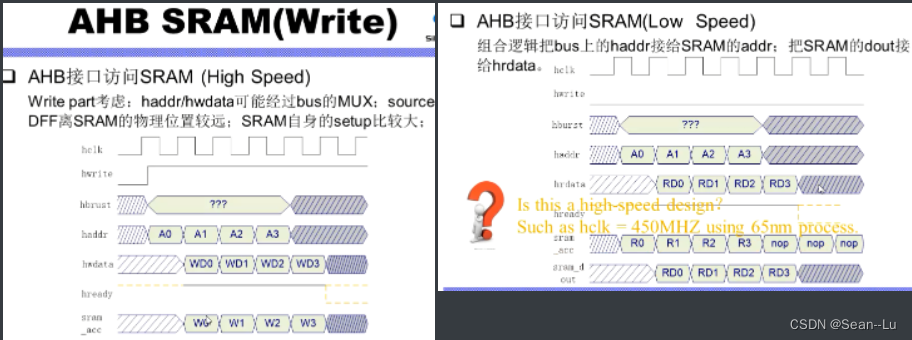
AHB地址线和读写数据刚好错开一个时钟周期——用于访问SRAM是不是刚好符合一个流水线设计? 这个设计并不是好的——并不是一个高速设计!——原因有3点...
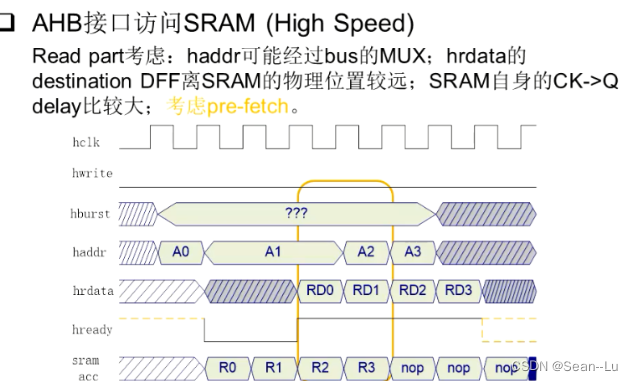

















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











