






https://zhuanlan.zhihu.com/p/33345791
https://zhuanlan.zhihu.com/p/52510471
什么是local 和 non-local ?
Local这个词主要是针对感受野(receptive field)来说的。以卷积操作为例,它的感受野大小就是卷积核大小,而我们一般都选用3*3,5*5之类的卷积核,它们只考虑局部区域,因此都是local的运算。同理,池化(Pooling)也是。
non-local指的就是感受野可以很大,而不是一个局部领域。全连接就是non-local的,而且是global的。但是全连接带来了大量的参数,给优化带来困难。这也是深度学习(主要指卷积神经网络)近年来流行的原因,考虑局部区域参数大大减少了,能够训得动。
local缺点
convolutional 和 recurrent操作在某一时刻只能处理一个局部区域,想要捕捉long-range dependencies(此处range可理解为time、distance),就只能重复地执行上述操作,通过数据逐步传递信号。这样会导致:1.计算量大 2.优化困难,需要小心处理 3.难以构建multihop dependency model(多跳依赖模型)。会使得网络失去对全局信息的整合能力
为什么使用non-local?
核心思想是在计算每个像素位置输出时候,不再只和邻域计算,而是和图像中所有位置计算相关性,然后将相关性作为一个权重表征其他位置和当前待计算位置的相似度。可以简单认为采用了一个和原图一样大的kernel进行卷积计算。
有些任务可能需要原图上更多的信息,比如attention。如果在某些层能够引入全局的信息,就能很好地解决local操作无法看清全局的情况,为后面的层带去更丰富的信息
提出非局部模块来捕捉long-range依赖。该方法灵感来自于传统CV中non-local means 方法,计算所有位置上特征的的加权和来作为对应位置的响应。这组位置可以是空间、时间或者时空坐标上的,这也就意味着这种泛化的非局部操作可以应用于图片、序列和视频问题。
不管是cv还是NLP任务,都需要捕获长范围依赖。在时序任务中,RNN操作是一种主要的捕获长范围依赖手段,而在CNN中是通过堆叠多个卷积模块来形成大感受野。目前的卷积和循环算子都是在空间和时间上的局部操作,长范围依赖捕获是通过重复堆叠,并且反向传播得到,存在3个不足:
(1) 捕获长范围依赖的效率太低;
(2) 由于网络很深,需要小心的设计模块和梯度;
(3) 当需要在比较远位置之间来回传递消息时,这是局部操作是困难的.
故作者基于图片滤波领域的非局部均值滤波操作思想,提出了一个泛化、简单、可直接嵌入到当前网络的非局部操作算子,可以捕获时间(一维时序信号)、空间(图片)和时空(视频序列)的长范围依赖。
优点:
- 与累进的 recurrent and convolutional操作正好相反,non-local操作不考虑时空距离,而是通过直接计算两个位置间的交互来捕捉long-range依赖(细节:long-range交互出现在远距离、长时间间隔的像素块间,该方法的基本工作单元"non-local块"可以以前馈方式直接捕捉这些时空依赖);
- non-local操作高效,只需少量几层就能实现很好的效果(细节:non-local neural networks比现有的2D和3D convolutional networks的视频分类精度高,同时与3D convolutional networks相比开销更少。它只使用RGB图,没有使用光流、多尺度测试等手段);
- non-local操作维持变量输入原先的大小,因此能方便地与其他操作相结合(细节:在 Mask R-CNN的基础上应用non-local block,可以在增加极少开销的情况下提高精度。该模块在图片和视频问题中都很实用,可以在设计深度神经网络时将其视作一个基础模块)。
为了能够当作一个组件接入到以前的神经网络中,作者设计的non-local操作的输出跟原图大小一致
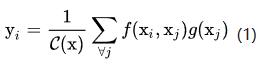
输入是x,输出是y,i和j分别代表输入的某个空间位置,x_i是一个向量,维数跟x的channel数一样,f是一个计算任意两点相似关系的函数,g是一个映射函数,将一个点映射成一个向量,可以看成是计算一个点的特征。也就是说,为了计算输出层的一个点,需要将输入的每个点都考虑一遍,而且考虑的方式很像attention:输出的某个点在原图上的attention,而mask则是相似性给出。
“非局部”行为由所有位置都参与计算实现。从对比中可以看出,convolutional操作在局部区域(如i−1≤j≤i+1)对输入加权求和,recurrent在时间点i处的操作仅仅基于当前和过去的一小段时间(如j = i or i − 1)。


以图像为例,为了简化问题,作者简单地设置g函数为一个1*1的卷积。相似性度量函数f的选择有多种:
![]() 对两个位置进行点乘,然后通过指数映射,放大差异。
对两个位置进行点乘,然后通过指数映射,放大差异。
前面的gaussian形式是直接在当前空间计算,而(2)更加通用,在嵌入空间中计算高斯距离






为了能让non-local操作作为一个组件,可以直接插入任意的神经网络中,作者把non-local设计成residual block的形式,让non-local操作去学x的residual:

上面构造成了残差形式。上面的做法的好处是可以随意嵌入到任何一个预训练好的网络中,因为只要设置W_z初始化为0,那么就没有任何影响,然后在迁移学习中学习新的权重。这样就不会因为引入了新的模块而导致预训练权重无法使用。
如果在尺寸很大的输入上应用non-local layer,也是计算量很大的。后者的解决方案是,只在高阶语义层中引入non-local layer。还可以通过对embedding![]() 的结果加pooling层来进一步地减少计算量。
的结果加pooling层来进一步地减少计算量。
注意到f的计算可以化为矩阵运算,我们实际上可以将整个non-local化为矩阵乘法运算+卷积运算。如下图所示,其中oc为output_channels,卷积操作的输出filter数量。


数据流是这样的:输入x的维度是T*H*W*1024,然后分别用数量为512,尺寸为1*1*1的卷积核进行卷积得到3条支路的输出,维度都是T*H*W*512,然后经过flat和trans操作得到THW*512、512*THW和THW*512的输出,前两条支路的两个输出进行矩阵乘法得到THW*THW的输出,经过softmax处理后再和第三条支路的输出做矩阵乘法得到THW*512维度的输出,将该输出reshape成T*H*W*512维度的输出后经过卷积核数量为1024,尺寸为1*1*1的卷积层并和原来的T*H*W*1024做element-wise sum得到最后的输出结果,这个element-wise sum就是ResNet网络中的residual connection。
为了提高non local block的计算效率,作者还从两个角度做了优化:1、θ、φ和g操作的卷积核数量设定为输入feature map通道数的一半(Figure2中512对1024)。2、对φ和g输出采取pooling方式进行抽样,这样φ和g输出的feature map的size就减小为原来的一半。这二者在代码中都有体现。
从公布的代码来看,non local并不是对网络的每个block都引入,思考下原因可能是:non local机制的设计初衷就是为了获取全局信息,而原来的卷积操作是为了获取局部信息,二者相辅相成才能有好的效果。


def NonLocalBlock(input, subsample=True):
"""
@Non-local Neural Networks
Non-local Block
"""
_, height, width, channel = input.get_shape().as_list() # (B, H, W, C)
theta = tf.layers.conv2d(input, channel // 2, 1) # (B, H, W, C // 2)
theta = tf.reshape(theta, [-1, height*width, channel // 2]) # (B, H*W, C // 2)
phi = tf.layers.conv2d(input, channel // 2, 1) # (B, H, W, C // 2)
if subsample:
phi = tf.layers.max_pooling2d(phi, 2, 2) # (B, H / 2, W / 2, C // 2)
phi = tf.reshape(phi, [-1, height * width // 4, channel // 2]) # (B, H * W / 4, C // 2)
else:
phi = tf.reshape(phi, [-1, height * width, channel // 2]) # (B, H*W, C // 2)
phi = tf.transpose(phi, [0, 2, 1]) # (B, C // 2, H*W)
f = tf.matmul(theta, phi) # (B, H*W, H*W)
f = tf.nn.softmax(f) # (B, H*W, H*W)
g = tf.layers.conv2d(input, channel // 2, 1) # (B, H, W, C // 2)
if subsample:
g = tf.layers.max_pooling2d(g, 2, 2) # (B, H / 2, W / 2, C // 2)
g = tf.reshape(g, [-1, height * width // 4, channel // 2]) # (B, H*W, C // 2)
else:
g = tf.reshape(g, [-1, height * width, channel // 2]) # (B, H*W, C // 2)
y = tf.matmul(f, g) # (B, H*W, C // 2)
y = tf.reshape(y, [-1, height, width, channel // 2]) # (B, H, W, C // 2)
y = tf.layers.conv2d(y, channel, 1) # (B, H, W, C)
y = tf.add(input, y) # (B, W, H, C)
return y在tensorflow和pytorch中,batch matrix multiplication可以用matmul函数实现。在keras中,可以用batch_dot函数或者dot layer实现。
https://github.com/titu1994/keras-non-local-nets
https://github.com/AlexHex7/Non-local_pytorch

随着non-local数量的增加,可以带来性能的持续提升
其背后的思想其实是自注意力机制的泛化表达,准确来说本文只提到了位置注意力机制(要计算位置和位置之间的相关性,办法非常多)。
个人认为:如果这些自注意模块的计算开销优化的很小,那么应该会成为CNN的基础模块。既然位置和位置直接的相关性那么重要,那我是不是可以认为graph CNN才是未来?因为图卷积网络是基于像素点和像素点之间建模,两者之间的权重是学习到的,性能肯定比这种自监督方式更好,后面我会写文章分析。
本文设计的模块依然存在以下的不足:
(1) 只涉及到了位置注意力模块,而没有涉及常用的通道注意力机制
(2) 可以看出如果特征图较大,那么两个(batch,hxw,512)矩阵乘是非常耗内存和计算量的,也就是说当输入特征图很大存在效率底下问题,虽然有其他办法解决例如缩放尺度,但是这样会损失信息,不是最佳处理办法。
















 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









