







文章目录
MySQL数据库DQL操作
基本知识
- DQL(数据库查询语言):用于查询数据库数据
- select
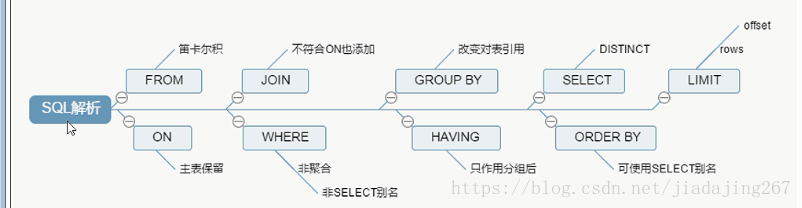
语法
SELECT <ALL | DISTINCT> -- 是否去重
{* | [table.field1[as alias1][,table.field2[as alias2]][,...]]} -- 设置最终结果显示d
FROM table_name [as table_alias]
[left | right | inner join table_name2] -- 联合查询
[WHERE ...] -- 指定结果需满足的条件
[GROUP BY ...] -- 指定结果按照哪几个字段来分组
[HAVING] -- 过滤分组的记录必须满足的次要条件
[ORDER BY ...] -- 指定查询记录按一个或多个条件排序
[LIMIT {[offset,]row_count | row_countOFFSET offset}];
-- 指定查询的记录从哪条至哪条
-- 在这里[]代表可选的
SQL执行顺序
数据库的列(表达式)
select version() -- 查询系统版本(函数)
select 10*3-1 as 计算机结果 -- 用来计算(表达式)
select @@auto_increament_increament -- 查询自增的步长(变量)
数据库中的表达式:文本值、列、NULL、函数,计算表达式、系统变量
Where条件字句
- 作用:检索数据中符合条件的值
逻辑运算符
| 运算符 | 含义 |
|---|---|
| A and B && | 逻辑与 |
| A or B || | 逻辑或 |
| not A=1 ! | 逻辑非 |
模糊查询:比运算符
| 运算符 | 含义 |
|---|---|
| A is null | 如果A为NULL,结果为真 |
| A is not null | |
| A between xx and xx | A在xx 和 xx 之间 |
| A like ‘xxx’ | A和 xxx匹配 |
| A in (xx,xxx) | A被包含在(xx,xxx)里面 |
匹配原则:正则匹配
%:匹配任意个字符
_:只匹配一个字符
联表查询Join
-- 示例
slelect A.num,B.name
from A <left | inner | right> join B A.num = B.num
Left join:显示左边所有的数据,即使B种没有匹配的对应值也会显示;而B种数据在A种没有匹配的就不会显示
Right join:和上面说法相反
Inner join:只会显示A、B均有匹配的值,所以不会出现未匹配的数据
自连接
自己的表和自己的表连接,核心:一张表拆成两张一样的表
将表多次命别名,相当于两个表进行操作
分页和排序
排序
根据指定字段排列行数据
-
升序ASC:
order by [列名] -- 默认升序 -
降序DESC
order by [列名] desc -- 降序排列
分页
-- 示例:每页只显示五条数据
select ...
order by xx
limit 1,5 -- (n - 1)*pageSize
-- 【pageSize:页面大小;n:当前页;(n-1)*pageSize:数据起始位置;数据总数/pageSize=当前页数】
格式
limit [查询起始下标],[往下显示的行数]
--------
limit 2,5 -- 从第2行数据开始(不包括第2行),往下显示5个数据
所以,如果我们要实现分页的效果,实际上是处理起始数据的行数选择,根据公式( n - 1)*pageSize 来确定起始数据。
即,如果想显示第2页数据,(2-1)*5=5,所以起始数据填 5,数据显示从第6行 - 第10行
瀑布流:一般图片才会采用
根据进度条的位置,不断加载数据
子查询和嵌套查询
where (这个值是计算出来的)
本质:在where语句中嵌套一个查询
-- 示例 查询选修了数据库-1的学生
select * from student
where studentNo = (
select studentNo from subject
where subject = '数据库-1'
)
-- 也可以联表查询
使用子查询,要注意where 里面的子查询返回的列要等于结果。
所以一般来说,子查询只返回一列结果
Group by
根据某个字段分组统计
- 可以结合聚合函数统计各组数据
- 分组筛选的条件不能用
where,要用having来筛选各组















 8142
8142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









