







参考:https://zhuanlan.zhihu.com/p/86331508
http://www.cnblogs.com/welhzh/p/6607581.html
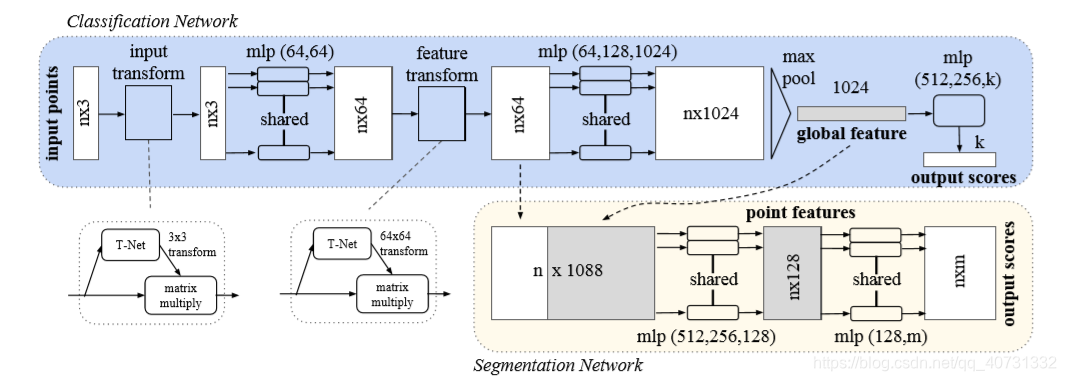
本文的重点在于解析被广泛应用的shared mlp(被广泛用于解决点云的无序性)。它的本质是用[1,1]大小的卷积核去卷积,减少了大量的参数。
在model/pointnet_seg.py/get_model()函数中我们可以发现下列代码:
其中输入为Batch_size x 点数 x 3(点云坐标),输出为Batch_size x 点数 x 50(分类)
具体被用来做shared MLP的是函数tf_util.conv2d() ,PointNet中的具体函数如下:
net = tf_util.conv2d(input_image, 64, [1,3],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv1', bn_decay=bn_decay)在tf_util.py中我们可以找到PointNet中使用的conv2d()函数,对应到tf.nn.conv2d的调用则如下:
def conv2d(inputs,
num_output_channels,
kernel_size,
scope,
stride=[1, 1],
padding='SAME',
use_xavier=True,
stddev=1e-3,
weight_decay=0.0,
activation_fn=tf.nn.relu,
bn=False,
bn_decay=None,
is_training=None):
kernel_h, kernel_w = kernel_size
num_in_channels = inputs.get_shape()[-1].value
kernel_shape = [kernel_h, kernel_w,
num_in_channels, num_output_channels]
kernel = _variable_with_weight_decay('weights',
shape=kernel_shape,
use_xavier=use_xavier,
stddev=stddev,
wd=weight_decay)
stride_h, stride_w = stride
outputs = tf.nn.conv2d(inputs, kernel,
[1, stride_h, stride_w, 1],
padding=padding)其中比较重要的参数有:num_output_channels = 64,kernel_size = [1, 3],stride = [1, 1]。对应到tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)函数。
(1)输入数据为[Batch_size, 点数, 3, 1];
(2)卷积核大小为[1, 3, 1, 64],具体含义为卷积核的高度为1,宽度为3,图像通道数为1,卷积核数为64,即64个1x3的卷积核;
(3)步长为[1, 1]
最后的输出是[Batch_size, 点数, 1, 64]。结合参考[1]可以理解为,每个[1,3]的卷积核依次对点进行卷积得到[点数,1,1],即新生成一个通道;所有的卷积核卷积完后生成64个通道。
因此再下一次的卷积输入[Batch_size, 点数, 1, 64]为的卷积核为[1,1,64,64],每个[1,1]的卷积核将64个通道的卷积结果求和并通过激活函数后输出,对应的输出为[Batch_size, 点数,64]。
因此使用大小为1的卷积核卷积,输出的维度受限于卷积核的个数,即通道数。
通过使用这种方法,大大的减少了参数的使用,例如将[3,2500]的点云升维为[64,2500],对全连接网络需要至少3 x 2500 x 64 x2500个参数,而使用这种方法仅用了3x64个参数(64个[1,3]卷积核),这也是对应到MLP中共享参数的原因。
# PointNet完整的网络实现如下:
def get_model(point_cloud, is_training, bn_decay=None):
""" Classification PointNet, input is BxNx3, output BxNx50 """
batch_size = point_cloud.get_shape()[0].value
num_point = point_cloud.get_shape()[1].value
end_points = {}
with tf.variable_scope('transform_net1') as sc:
transform = input_transform_net(point_cloud, is_training, bn_decay, K=3)
point_cloud_transformed = tf.matmul(point_cloud, transform)
input_image = tf.expand_dims(point_cloud_transformed, -1)
net = tf_util.conv2d(input_image, 64, [1,3],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv1', bn_decay=bn_decay)
net = tf_util.conv2d(net, 64, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv2', bn_decay=bn_decay)
with tf.variable_scope('transform_net2') as sc:
transform = feature_transform_net(net, is_training, bn_decay, K=64)
end_points['transform'] = transform
net_transformed = tf.matmul(tf.squeeze(net, axis=[2]), transform)
point_feat = tf.expand_dims(net_transformed, [2])
print(point_feat)
net = tf_util.conv2d(point_feat, 64, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv3', bn_decay=bn_decay)
net = tf_util.conv2d(net, 128, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv4', bn_decay=bn_decay)
net = tf_util.conv2d(net, 1024, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv5', bn_decay=bn_decay)
global_feat = tf_util.max_pool2d(net, [num_point,1],
padding='VALID', scope='maxpool')
print(global_feat)
global_feat_expand = tf.tile(global_feat, [1, num_point, 1, 1])
concat_feat = tf.concat(3, [point_feat, global_feat_expand])
print(concat_feat)
net = tf_util.conv2d(concat_feat, 512, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv6', bn_decay=bn_decay)
net = tf_util.conv2d(net, 256, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv7', bn_decay=bn_decay)
net = tf_util.conv2d(net, 128, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv8', bn_decay=bn_decay)
net = tf_util.conv2d(net, 128, [1,1],
padding='VALID', stride=[1,1],
bn=True, is_training=is_training,
scope='conv9', bn_decay=bn_decay)
net = tf_util.conv2d(net, 50, [1,1],
padding='VALID', stride=[1,1], activation_fn=None,
scope='conv10')
net = tf.squeeze(net, [2]) # BxNxC
return net, end_points


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









