






official repo: https://github.com/NVlabs/tiny-cuda-nn
该包可以显著提高NeRF训练速度,是Instant-NGP、Threestudio和NeRFstudio等框架中,必须使用的。
1. 命令行安装
最便捷的安装方式,如果安装失败考虑本地编译。
pip install ninja git+https://github.com/NVlabs/tiny-cuda-nn/#subdirectory=bindings/torch2. 本地编译
2.1 git下载
git clone --recursive https://github.com/nvlabs/tiny-cuda-nn该命令中的recursive,是用于下载tiny-cuda-nn中的两个依赖包:cutlass和fmt。
如果服务器上recursive下载失败,考虑本地下载zip包,上传至服务器并解压。但注意:此时两个依赖包是需要自己下载的:
cd tiny-cuda-nn/dependencies
git clone https://github.com/NVIDIA/cutlass.git
git clone https://github.com/fmtlib/fmt.git2.2 本地编译
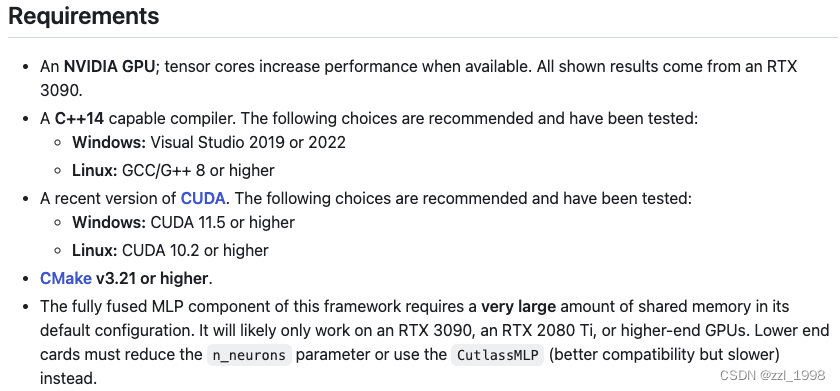
一定是确保GCC、CUDA、CMake版本符合:
cd bindings/torch
python setup.py install其中,如果GCC版本过老,同时没有root权限,可以考虑:
# 下载源码包并解压
wget https://mirrors.cloud.tencent.com/gnu/gcc/gcc-11.2.0/gcc-11.2.0.tar.gz
tar -zxvf gcc-11.2.0.tar.gz
# 下载依赖及配置文件
cd gcc-11.2.0
./contrib/download_prerequisites
# 配置,prefix指向存储路径
mkdir build
cd build/
../configure --prefix=/path/to/install/gcc --enable-checking=release --enable-languages=c,c++ --disable-multilib
# 编译,后面的速度用来提速,与CPU相关
make -j 64
# 安装
make install
将新版gcc路径添加至~/.bashrc,如果能正确输出gcc版本,则安装成功。
vim ~/.bashrc
# 添加以下内容
export PATH="/path/to/gcc-11.2.0/bin:$PATH"
export LD_LIBRARY_PATH="/path/to/gcc-11.2.0/lib64:$LD_LIBRARY_PATH"
# 添加后,执行下列命令
source ~/.bashrc
gcc -v
















 889
889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









