







 本文提出一种自监督学习方法,用于分离地方特征与外观特征,解决了视觉定位识别任务中因外观变化导致的问题。通过两个编码器及对抗性训练,确保地方特征不受时段、天气等影响,可用于不同环境下的图像匹配。
本文提出一种自监督学习方法,用于分离地方特征与外观特征,解决了视觉定位识别任务中因外观变化导致的问题。通过两个编码器及对抗性训练,确保地方特征不受时段、天气等影响,可用于不同环境下的图像匹配。
Abstract & Introduction
Visual place recognition: 给不同环境下的一系列图片,找到一对相同位置图片的联系。特征提取是这个任务的关键,因为appearance是改变的,需要找到不变的特征。
本文提出分离domain-unrelated feature(place feature)和domain-related feature(appearance feature),其中domain-unrelated feature去place recognition,这里的domain可以是不同时段、天气和季节。具体来说,本文通过两个encoders(autoencoder structure)来分离两者。为了确保place features仅包含domain-unrelated content,本文使用adversarial training。本文还有一个很大的特色在:self-supervised,不需要人为对齐数据。最后place feature被用作place recognition的descriptor。总的来说,贡献如下:
- 自监督特征学习方法,用于分离place和appearance features。
- 在不增加模型复杂度的基础上,本文提出的框架使用多个领域进行训练。
- 在MNIST的toy case study用于验证假设。在两个开源数据集上测试,效果不错。
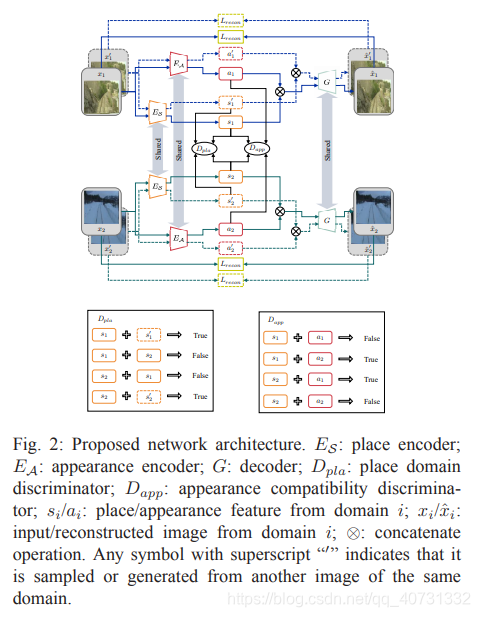
Adversarial Feature Disentanglement for place reconition
A. Reconstruction Loss
encoders和decoder用于重建原始输入图片,并使用L2距离来评估重建质量。
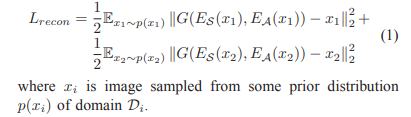
B. Place Domain Discriminator
对于同一地点不同领域的图片,Dpla要输出1,而不同地点无论领域是否相同,Dpla要输出0。
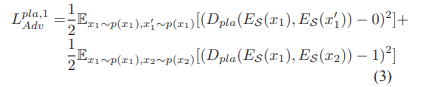
C. Appearance Compatibility Discriminiator
仅用place domain discriminator是不够的,因为EA可能带有位置信息,这样既可用si和ai来重建原始图片,同时Dpla又影响不到。然而,place和appearance features不是独立的。因此使用Dapp去测量两者是否独立。
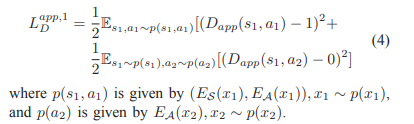
如果place和appearance features没有分离开,则s1=Es(x1),a1=EA(x1)是不独立的。
D. Extension: Multiple Domains Case
在训练的每一iteration,从N个domain中,随机挑选两个做
E. Implementation and Traning
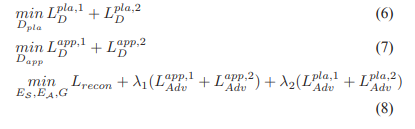
网络结构:Encoders和decoder和discriminators都是卷积网络,autoencoder时bottleneck结构appearance feature是nA维向量。对于discriminators,(si, sj)concatenated一起送入discriminators,然后降维到一维输出。
Place Recognition:使用Es的输出place feature作为descriptors
![]()
Experimental Results
A. Toy Case
用MNIST来验证假设。用t-SNE来可视化place和apperacnce特征,结果显示place feature规则,而appearance feature随机分布。

其中,zero-appearance image是将appearance feature设置为0,结果显示,所有decoded images有相同的颜色。translated image是左上角的place feature和右上角的appearance feature的结合。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









