







一篇文章看懂协程(从入门到放弃
1、基本概念
协程是可以暂停和恢复的函数。
协程相关概念太多,什么有栈协程、无栈协程、对称协程、非对称协程,单纯复述这些定义没有意义。这里先从实现暂停和恢复入手。
2、有栈协程
先来点基础概念打基础。
栈
栈作为常用数据结构的一种,特性就不重复了。
这里主要说在linux进程地址空间布局的结构和作用。在程序运行过程中,栈保存了一个函数调用所需要维护的信息,被称为堆栈帧,一般包括以下几个内容:
1、函数的返回地址和参数
2、临时变量:包括函数的非静态局部变量及编译器自动生成的其它临时变量
3、保存的上下文:包括在函数调用前后需要保存不变的寄存器的值
有栈协程其实就是自己维护一个运行函数的栈空间,防止在暂停时被其他数据写入污染。基本实现可以依赖<ucontext.h>头文件
ucontext上下文
我们会用到这个库提供的四个函数
getcontext & setcontext
#include <stdio.h>
#include <ucontext.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
ucontext_t context;
//获取当前程序上下文
getcontext(&context);
puts("Hello world");
sleep(1);
//将程序切换至context指向的上下文处
setcontext(&context);
return 0;
}
这个程序会无限循环输出hello world,因为在getcontext获取程序(在main函数中)此刻的状态,下一步就是执行puts,sleep之后setcontext后就是将main函数重置到执行getcontext时的状态。
ucontext_t
typedef struct ucontext {
struct ucontext *uc_link;
sigset_t uc_sigmask;
stack_t uc_stack;
mcontext_t uc_mcontext;
...
} ucontext_t;
makecontext
#include <iostream>
#include <ucontext.h>
int main()
{
using std::cout; using std::endl;
ucontext_t ctx;
char stack[1209];
auto func = [] { cout<<"hello world"<<endl; };
getcontext(&ctx);
ctx.uc_stack.ss_sp = stack;
ctx.uc_stack.ss_size = 1209;
makecontext(&ctx,func,0);
cout<<"test"<<endl;
setcontext(&ctx);
cout<<"test 1"<<endl;
return 0;
}
这段程序会先输出test,然后输出hello world后退出。(栈空间不够时会Segmentation fault (core dumped))
因为在makecontext把ctx的上下文设置成了func的函数入口,后面的参数都是传给func函数的。
makecontext 和 setcontext 的设计初衷并不是为了在当前线程的栈上直接运行一个新函数,而是允许在另一个用户定义的栈上运行新函数。这里需要开发者给新函数分配一个可以使用的栈空间。
swapcontext
makecontext(&co->ctx,(void (*)(void))task_run,1,S);
swapcontext(&S->_main_ctx,&co->ctx);
S->_main_ctx是一个未初始化的ucontext_t结构体,而co->ctx已经被makecontext设置成了执行task_run函数时的上下文。makecontext函数用于修改一个已存在的ucontext_t结构体,使其包含一个新的栈和函数入口点,以便在后续使用swapcontext或setcontext时能够跳转到那个新的函数执行。
当调用swapcontext(&S->_main_ctx,&co->ctx);时,会发生以下事情:
1、swapcontext会首先保存当前线程的上下文(CPU寄存器状态、栈指针等)到S->main_ctx中。因为S->main_ctx是未初始化的,这一步实际上会覆盖其未初始化的状态,用当前线程的上下文信息来填充它。
2、接着,swapcontext会加载co->ctx中保存的上下文,并将程序的控制流跳转到task_run函数,从该函数所在的栈顶开始执行。
swapcontext不是交换两个ucontext_t结构体实例的状态,而是使用它们来保存和恢复线程的执行上下文。例子中,S->main_ctx用于保存当前线程的上下文(相当于getcontext),而co->ctx则用于恢复并执行task_run函数。
S->main_ctx会被填充当前线程的上下文信息,而co->ctx则保持不变,并用于跳转到task_run函数执行。
执行完task_run函数后,如果你想要恢复回swapcontext调用之前的状态(即保存在S->main_ctx中的状态),你需要再次调用setcontext或swapcontext,并传递S->main_ctx作为参数。这样,程序的控制流就会返回到swapcontext调用之后的位置,继续执行后续的代码。
共享栈的coroutine
前面说过每个函数都运行在栈上,为了节省资源就有了一种共享栈的设计,申请一片足够的栈空间用来运行任务,在阻塞需要yield让出资源的时候 在堆上申请空间保存该函数任务的栈内存数据,下次恢复执行的时候再将保存的数据复制到栈空间上继续执行。云风的coroutine和腾讯开源的libco都是共享栈设计。
下面给出一个简单实现:
#include <ucontext.h>
#include <cstring>
#include <vector>
#include <iostream>
#define STACK_SIZE 1024*1024
#define DEFAULT_COROUTINE 32
struct Schedule;
struct coroutine;
using func_t = void (*)(Schedule*,void*);
enum class STATUS{
COROUTINE_DEAD = 0,
COROUTINE_READY,
COROUTINE_RUNNING,
COROUTINE_SUSPEND,
};
struct Schedule
{
char s_stack[STACK_SIZE];
ucontext_t _main_ctx;
int co_num = 0;
int co_max = DEFAULT_COROUTINE;
int co_running = -1;
std::vector<coroutine*> co_list;
Schedule():co_list(DEFAULT_COROUTINE,nullptr){}
};
struct coroutine
{
func_t func;
void *data = nullptr;
ucontext_t ctx;
Schedule *schedule = nullptr;
ptrdiff_t stack_size = 0;
ptrdiff_t stack_cap = 0;
STATUS status = STATUS::COROUTINE_READY;
char *stack = nullptr;
};
struct coroutine* co_new(Schedule* S, func_t func,void *data)
{
coroutine *co = new coroutine;
co->func = func;
co->data = data;
co->schedule = S;
return co;
}
void co_delete(coroutine *co)
{
delete co->stack;
delete co;
}
Schedule* schedule_create(void)
{
Schedule *S = new Schedule;
return S;
}
void schedule_delete(Schedule *S)
{
for(int i = 0;i < S->co_max;++i)
{
if(S->co_list[i] != nullptr)
co_delete(S->co_list[i]);
}
delete S;
}
int co_create(Schedule *S, func_t func, void *data)
{
coroutine *co = co_new(S, func, data);
if(S->co_num >= S->co_max)
{
S->co_max += DEFAULT_COROUTINE;
S->co_list.reserve(S->co_max);
}
for(int i = 0;i < S->co_max;++i)
{
int id = (i+S->co_num) % S->co_max;
if(S->co_list[id] == nullptr)
{
S->co_num++;
S->co_list[id] = co;
return id;
}
}
return -1;
}
void task_run(Schedule *S)
{
int id = S->co_running;
coroutine *co = S->co_list[id];
co->func(S,co->data);
co_delete(co);
S->co_list[id] = nullptr;
S->co_num--;
S->co_running = -1;
}
void co_resume(Schedule *S, int id)
{
coroutine *co = S->co_list[id];
if(co == nullptr)
return;
if(co->status == STATUS::COROUTINE_READY)
{
getcontext(&co->ctx);
co->ctx.uc_stack.ss_sp = S->s_stack;
co->ctx.uc_stack.ss_size = STACK_SIZE;
co->ctx.uc_link = &S->_main_ctx;
S->co_running = id;
co->status = STATUS::COROUTINE_RUNNING;
makecontext(&co->ctx,(void (*)(void))task_run,1,S);
swapcontext(&S->_main_ctx,&co->ctx);
return;
}
if(co->status == STATUS::COROUTINE_SUSPEND)
{
memcpy(S->s_stack + STACK_SIZE - co->stack_size,co->stack,co->stack_size);
S->co_running = id;
co->status = STATUS::COROUTINE_RUNNING;
swapcontext(&S->_main_ctx,&co->ctx);
return;
}
}
void save_stack(coroutine *co, char *top)
{
char dummy=0;
if(co->stack_cap < top - &dummy)
{
free(co->stack);
co->stack_cap = top - &dummy;
co->stack = (char*)malloc(co->stack_cap);
}
co->stack_size = top - &dummy;
memcpy(co->stack,&dummy,co->stack_size);
}
void coro_yield(Schedule *S)
{
int id = S->co_running;
coroutine *co = S->co_list[id];
save_stack(co,S->s_stack + STACK_SIZE);
co->status = STATUS::COROUTINE_SUSPEND;
S->co_running = -1;
swapcontext(&co->ctx,&S->_main_ctx);
return;
}
STATUS co_status(Schedule *S, int id)
{
if(S->co_list[id] == nullptr)
return STATUS::COROUTINE_DEAD;
return S->co_list[id]->status;
}
int co_running(Schedule *S)
{
return S->co_running;
}
上下文切换的相关操作和原理前面已经说过,所以这段代码没什么需要啰嗦的。
需要注意的就是save_stack几个变量的关系
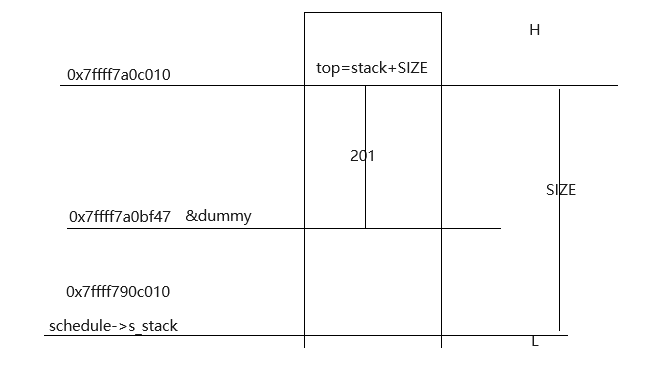
栈是从高位到低位用的,top=stack+SIZE是栈的最高位但是为栈底,这个函数运行是从top往低位使用栈空间的,dummy是刚定义的变量,应该在栈顶,top-&dummy就是使用的栈空间大小,而从dummy到stack就是没有用到的栈部分。
共享栈就是任务运行都在stack这个空间SIZE大小的栈上,切换的时候保存自己当前运行的数据,然后把下一个任务的数据加载进来切换上下文。
独立栈
共享栈切换要频繁的memcpy栈数据,退出保存一次,切换加载一次,执行效率会有损耗。所以我更偏向非共享栈的协程设计,即每个协程任务都有自己独立的运行栈,不用每次切换都繁琐的计算大小和memcpy。当然这种设计也有缺陷,协程栈的大小不固定,只能预分配一定的空间,如果空间小了就会段错误,如果空间大了就浪费。要程序能正常运行肯定会有部分浪费,在传递任务的时候标记任务大小便可以创建栈时尽量减少浪费。
而且因为系统的栈空间有限,如果每个协程都有自己独立的栈就很容易用完栈空间,限制了协程数量,所以要解决这个问题有两种方案可以选择:
1、从堆上或其他区域分配内存来模拟栈。
2、调整系统栈大小或使用分段栈动态增长栈空间。
bthread采用的就是mmap分配内存模拟栈来使用的。
#include <sys/mman.h>
#include <unistd.h>
#include <iostream>
int main() {
const size_t stackSize = 1024 * 1024; // 1MB 栈大小
// 使用 mmap 分配内存,这里的 PROT_READ | PROT_WRITE 表示内存区域可读写,
// MAP_PRIVATE 表示这是一个私有的、可写时复制的映射,
// MAP_ANON 表示不关联到任何文件,MAP_STACK 表示这块内存将用作栈。
void* stackMemory = mmap(nullptr, stackSize, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANON | MAP_STACK, -1, 0);
if (stackMemory == MAP_FAILED) {
std::cerr << "Failed to allocate stack memory." << std::endl;
return 1;
}
// 你可以在这里设置栈顶指针,并初始化你的协程环境。
// 例如,你可以将栈顶设置为分配的内存的顶部。
char* stackTop = (char*)stackMemory + stackSize;
// TODO: 在此处初始化协程上下文,设置栈顶和程序计数器(PC)等。
// 当协程结束时,不要忘记释放内存。
munmap(stackMemory, stackSize);
return 0;
}
这样就有足够的内存给协程栈运行了,协程函数的暂停和恢复看起来也更容易理解。
举个例子:
就像同时做两套试卷,共享栈就相当于只有一张草稿纸,做题只能把计算过程写在草稿纸上一步步算下去,从A卷切换到B卷时,要把进度写到A卷,然后把草稿纸擦干净,再把B卷必要数据写到草稿纸上计算,切换到A也是要把进度写到B卷 擦干净草稿纸 从A卷誊抄数据继续计算。
独立栈就是AB有各自对应的草稿纸,不会被对方的数据覆盖,因此切换的时候可以直接对着之前计算结果继续执行,不需要将结果记录在对应试卷和誊抄之前计算的数据到草稿的这两步。
这里提两点bthread的设计
1、未完成的任务会把task_id重新加入执行队列,worker(调度器)取到任务的时候就继续之前进度执行
2、任务只有在切换执行前一步才分配空间,在第一次加入队列的时候并没有自己的栈。
总的来说有栈协程很容易理解,就是将函数放到自己控制的内存空间上执行,中间加了标记点用以暂停和恢复,网上那些多轻量级线程或者用户态线程的说法对于有栈协程很形象贴切。相对而言 无栈协程理解难度就上了一个层次,无栈协程需要编译器语言级别的支持,c++20新增了这方面的特性和关键字。
3、无栈协程
共享栈的协程将任务执行进度保存在自己申请的一片堆内存里,需要的时候就memcpy到执行栈空间里。
独立栈的协程不需要额外保存执行进度,它的执行空间只有自己用,执行流回到这片空间就能继续原本的进度。
无栈协程则不需要关心运行栈空间,但是需要一个协程帧frame保存运行状态(任务进度)。协程帧主要保存参数和局部变量的值,在让出执行权的时候能保存运行状态和执行流节点。
这里先以一个结构体来实现保存函数执行状态和变量值
#include <iostream>
using namespace std;
struct farme{
int a,b,c;
int status=0;
};
int resume(farme &f)
{
switch(f.status)
{
case 0:
f.status = 1;
goto s0;
case 1:
f.status = 2;
goto s1;
case 2:
f.status = 3;
goto s2;
case 3:
//f.status = 3;
goto s3;
s0:
f.a = f.b = 1;
return f.a;
s1:
return f.b;
s2:
while(true)
{
f.c = f.a + f.b;
return f.c;
s3:
f.a = f.b;
f.b = f.c;
}
}
return 0;
}
int main()
{
farme f;
for(int i=0;i<10;i++)
{
int x = resume(f);
cout<<x<<endl;
}
return 0;
}
这段代码里status变量用来保存运行状态决定下次进入resume函数的执行位置逻辑,abc也是在结构体的成员变量在生命周期里也是一直保存的。
无栈协程的协程帧就类似这个例子中的farme结构体,保存了协程的进度状态信息,保证挂起后能正确恢复。协程帧与promise_type结构体共同控制协程的行为,c++20定义协程任务的时候必须关联一个固定名称为promise_type的结构体,promise_type对象在协程创建时构建并存在于协程帧中。
struct promise_type {
std::optional<T> value;
Generator<T> get_return_object() //协程的返回对象
{
return {std::coroutine_handle<promise_type>::from_promise(*this)};
}
std::suspend_always initial_suspend() //协程开始时的行为
{
return {};
}
std::suspend_always final_suspend() noexcept
{//协程结束时的动作
return {};
}
void unhandled_exception() //处理协程中未捕获的异常
{
std::terminate();
}
std::suspend_always yield_value(T value)
{
this->value = value;
return {};
}
void return_void() {}
};
c++20的协程主要分两类
Generator(生成器):
是一种特殊的函数,设计用于在需要时逐个生成值。
使用co_yield关键字来产生(yield)值,并在每次产生值后暂停执行,直到下一次被恢复。
适用于编写按需生成值的逻辑,如迭代器或数据流。
Awaitable(可等待对象):
表示一个可以异步等待的操作或结果。
使用co_await关键字来暂停当前协程的执行,直到所等待的异步操作完成。
适用于编写异步代码,处理需要等待的I/O操作、延迟计算等。
这两类实现本质上也是用途上的区别,也体现在关键字使用上
Generator通常于co_yield一起使用,执行到co_yield时,会挂起协程并返回一个值,恢复后继续到co_yield后执行。主要关注于生存值的序列和逻辑,可适用generator函数生成斐波那契数列等场景。
Awaitable通常和co_await一起使用,主要用于异步操作。awaitable对象表示一个异步操作会在将来某个时间点完成,co_await挂起协程后,直到异步操作完成后恢复,并且返回异步操作的结果。适用于网络请求、文件io等需要等待的场景。
#include <coroutine>
#include <iostream>
#include <optional>
// 定义一个生成器,它将产生整数序列
template <typename T>
struct Generator {
struct promise_type {
std::optional<T> value;
Generator<T> get_return_object() {
return { std::coroutine_handle<promise_type>::from_promise(*this) };
}
std::suspend_always initial_suspend() {
return {};
}
std::suspend_always final_suspend() noexcept {
return {};
}
void unhandled_exception() {
std::terminate();
}
std::suspend_always yield_value(T value) {
this->value = value;
return {};
}
void return_void() {}
};
std::coroutine_handle<promise_type> handle;
Generator(std::coroutine_handle<promise_type> handle) : handle(handle) {}
~Generator() {
if (handle) {
handle.destroy();
}
}
bool next(T& value) {
if (!handle || handle.done()) {
return false;
}
handle.resume();
if (handle.promise().value) {
value = handle.promise().value.value();
handle.promise().value.reset();
return true;
}
return false;
}
};
// 使用生成器的协程函数
Generator<int> countUpTo(int n) {
for (int i = 0; i < n; ++i) {
co_yield i; // 产生下一个值
}
}
int main() {
Generator<int> gen = countUpTo(5); // 创建一个生成器,产生0到4的整数
int value;
while (gen.next(value)) { // 循环获取生成器产生的值
std::cout << "Generated value: " << value << std::endl;
}
return 0;
}
直接看这个程序的执行流
Generator gen = countUpTo(5);
调用countUpTo,实例化Generator< int >。分配必要的内存来存储协程的状态,创建一个与这个协程关联的 promise_type 对象。promise_type 是协程框架的一部分,它管理着协程的生命周期,包括挂起、恢复和销毁。
countUpTo 函数通过调用其 promise_type 的 get_return_object 方法来获取一个表示该协程的句柄(在这个例子中是 Generator< int > 类型的对象)。这个句柄允许外部代码控制协程的执行,比如恢复挂起的协程或检查协程是否已经完成。
协程句柄赋值给gen变量
在这一步中,因为initial_suspend()设置的返回值是std::suspend_always ,countUpTo 函数的函数体并未开始执行(除了与协程初始化相关的部分)。协程的实际执行会在稍后通过调用 gen.next(value) 并进而调用 handle.resume() 时开始。
gen.next(value)
bool next(T& value) {
if (!handle || handle.done()) {
return false;
}
handle.resume();
if (handle.promise().value) {
value = handle.promise().value.value();
handle.promise().value.reset();
return true;
}
return false;
}
检查协程状态
handle.resume();恢复协程
协程执行到co_yield i会挂起,并将值存储在promise对象的value中,执行流回到resume的调用方
引用的value被赋值promise的value值
handle.promise().value.reset();调用 std::optional 类型的 reset() 方法。这个方法将 optional 对象重置为不包含值的状态,即使其变为“空”状态。在这个上下文中,它用于在每次从生成器中取出值之后清空 value,以便为下一次 yield_value 做准备。虽然不清空value,大多数情况下都程序都能正常运行,但是像if (handle.promise().value)这种判断就会失效,为了避免这些情况导致可能存在的bug,还是建议规范执行。
当协程执行完成后
for循环条件不满足
协程执行完成
执行流到void return_void(){},
回到generator协程 生成器
执行流到std::suspend_always final_suspend() noexcept
返回resume调用方
#include <coroutine>
#include <iostream>
#include <thread>
#include <chrono>
#include <future>
// 自定义的Awaiter类型
struct MyAwaiter {
bool await_ready() {
// 如果操作已经完成,返回true;否则返回false
return false; // 假设总是异步
}
void await_suspend(std::coroutine_handle<> h) {
// 模拟异步操作,例如网络请求或文件I/O
try
{
std::thread([h] {
std::this_thread::sleep_for(std::chrono::seconds(1));
h.resume(); // 恢复协程的执行
std::cout << "thread" << std::endl;
}).detach();
}
catch (const std::exception& e) {
std::cout << "Exception: " << e.what() << std::endl;
}
}
void await_resume() {
// 当异步操作完成时调用的代码
std::cout << "await_resume" << std::endl;
}
};
// 协程函数返回类型
struct MyFuture {
//std::shared_ptr<std::promise<void>> promise = std::make_shared<std::promise<void>>();
//std::future<void> future = promise->get_future();
std::future<void> future;
// 构造函数,接受promise的shared_ptr来初始化future
//void setPromise() {
// promise->set_value(); // 设置promise的值,表示异步操作完成
//}
//MyFuture(std::shared_ptr<std::promise<void>> p) : promise(p), future(p->get_future()) {}
MyFuture() {}
struct promise_type {
std::promise<void> promise;
auto get_return_object() {
//auto p = std::make_shared<std::promise<void>>();
//promise = p;
//return MyFuture(p); // 使用关联的promise来构造MyFuture
MyFuture fut;
fut.future = promise.get_future();
return fut;
}
std::suspend_never initial_suspend() { return {}; }
std::suspend_never final_suspend() noexcept { return {}; }
void return_void()
{
std::cout << "return_void" << std::endl;
promise.set_value(); // 设置promise的值,表示异步操作完成
}
void unhandled_exception() { std::terminate(); }
};
};
// 协程函数
MyFuture async_operation() {
co_await MyAwaiter{};
std::cout << "Async operation completed!" << std::endl;
co_return; // 使用 co_return 来表示协程的完成
}
int main()
{
auto fut = async_operation();
std::cout << "Main thread" << std::endl;
//std::this_thread::sleep_for(std::chrono::seconds(5));
fut.future.get(); // 等待异步操作完成
std::cout << "Main thread" << std::endl;
return 0;
}
随便凑了个可用的Awaitable
fut.future.get();会阻塞等待,需要协程结束时return_void中promise.set_value()。
4、总结
c++的协程理论上很高效,但是对开发者不算友好,需要一个先进的库做这些支持,不然自己开发负担太大。一般会用协程把网络io这些阻塞封装成异步任务,再配合io_uring的异步读写提交后切换其他任务操作,io完成后通知调度器恢复协程,获取io结果后再进行后续处理。
有栈协程还好有几个很方便的库了,像brpc的bthread模块,直接封装得同pthread创建线程一样使用。无栈协程的支持标准还是太新了,目前接触的有几个开源的库都是大佬在大学期间编写的,boost作为准标准库应该有支持,但是没看到大家讨论哪个好用。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









