







 本文介绍了一种名为Hide-and-Seek的弱监督学习方法,通过在训练时随机隐藏图像块,迫使网络关注对象的各个部分,提高了目标和行为定位的准确性。实验证明,该方法在不同网络和层上均有效。
本文介绍了一种名为Hide-and-Seek的弱监督学习方法,通过在训练时随机隐藏图像块,迫使网络关注对象的各个部分,提高了目标和行为定位的准确性。实验证明,该方法在不同网络和层上均有效。
Hide-and-Seek: Forcing a Network to be Meticulous for Weakly-supervised Object and Action Localization
作者贡献
问题:大多数网络只识别图像最具有鉴别力的部分
解决:改变输入图像,即在训练时隐藏图片部分块使得模型去图片剩余部分寻找相关对象部分。如下图所示:
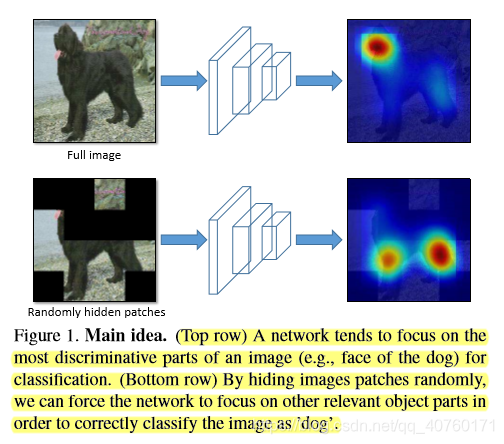
贡献:
- 为弱监督定位提出了Hide-and-Seek的思想。
- 证明了这个方法在不同网络和层上的适用性。
- 将方法拓展到弱监督时间行为定位。
方法
弱监督对象定位
给定一组只有分类标签的图片集集合。
目标:学习对象定位使其可以预测分类标签和感兴趣的对象边界框。
隐藏随机图片块
目的:在训练分类任务的网络是,展现对象不同的部分。
作用:保证对象中最有识别力的部分不是一直对网络是有效的,从而迫使它也关注对象的其他相关部分。
具体:给定一个训练图片I,大小为W×H×3。用一个固定大小的网格S×S×3划分图片,从而获得 (W×H)/(S×S) 个块。对于每个块,被隐藏的概率为
p
h
i
d
e
p_{hide}
phide 。
举例:如下图所示,图片大小为224×224×3,将其划分为16块,每块大小为56×56×3。每一块被隐藏的可能性
p
h
i
d
e
p_{hide}
phide=0.5 。于是获得了一个新的带有隐藏块的图片I’ ,并作为训练网络的输入。
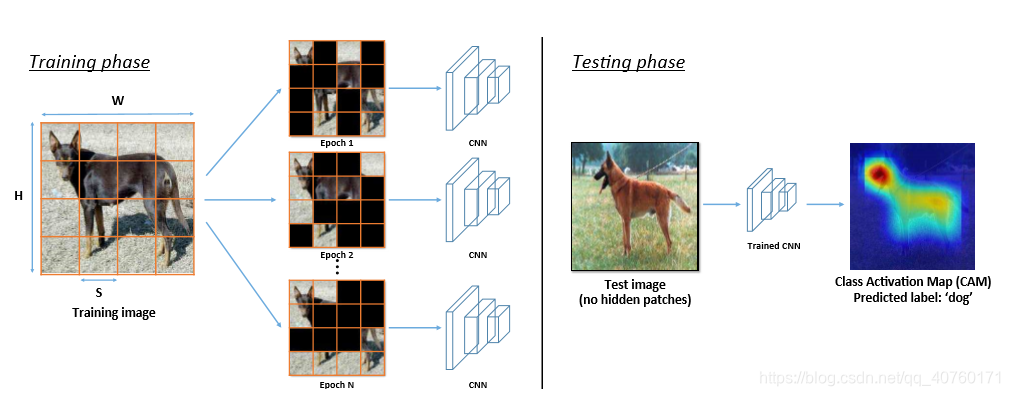
注:对于同一张图片,在每个训练epoch,随机隐藏一组不同的块。
设置隐藏像素值
问题:由于训练时隐藏块与测试时不隐藏块的差异,第一个卷积层的激活在训练和测试时会有不同的分布。要使训练好的网路能够很好地泛化新的测试数据,其激活的分布要大致相等。也就是说,对于神经网络中的任何一个单元,只要它连接到x个单元,并且输出的权值为w,它的分布
w
T
x
w^Tx
wTx在训练和测试期间要大致相同。然而,在文章的设置中,情况不一定是这样的,因为每个训练图像中的一些块将被隐藏,而每个测试图像中的块将不会被隐藏。
具体:
在文章的设置中,假设有一个卷积过滤器F,其内核大小为K×K。还有一个3维的权重W = {
w
1
,
w
2
,
.
.
.
,
w
k
×
k
w_1,w_2,...,w_{k×k}
w1,w2,...,wk×k},其应用在图片I’ 的一个RGB块X = {
x
1
,
x
2
,
.
.
.
,
x
k
×
k
x_1,x_2,...,x_{k×k}
x1,x2,...,xk×k}。向量v表示每个隐藏像素的RGB值。则有以下三种激活方式:
- F完全在可见的块中(如下图中的蓝色方块),其对应输出为 ∑ i = 1 k × k w i T x i \sum_{i=1}^{k\times k}w^T_ix_i ∑i=1k×kwiTxi
- F完全在隐藏的块中(如下图中的红色方块),其对应输出为 ∑ i = 1 k × k w i T v \sum_{i=1}^{k\times k}w^T_iv ∑i=1k×kwiTv
- F部分在隐藏的块中(如下图中的绿色方块),其对应输出为 ∑ m ∈ v i s i b l e w m T x m + ∑ n ∈ h i d d e n w n T v \sum_{m∈visible}w^T_mx_m + \sum_{n∈hidden}w^T_nv ∑m∈visiblewmTxm+∑n∈hiddenwnTv
在测试时,F永远在可见的块中,则输出为
∑
i
=
1
k
×
k
w
i
T
x
i
\sum_{i=1}^{k\times k}w^T_ix_i
∑i=1k×kwiTxi 这仅与第一种情况匹配。对于剩下两种情况,激活分布会与测试的不同。
解决:通过设置隐藏像素的RGB值v等于整个数据集上图像的平均RGB向量来解决这个问题,公式如下:
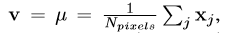
j表示整个训练集中所有的像素索引,
N
p
i
x
e
l
s
N_{pixels}
Npixels表示总像素数。
Object localization network architecture
隐藏块的方法可以独立于网络结构,并用在目标定位的CNN设计中。对于文章的实验,作者选择的网络参见论文1,其在卷积特征映射上执行全局平均池化(GAP),为代表给定类的判别区域的输入图像生成类激活映射(CAM)。这种方法已经在弱监督设置下为ILSVRC定位挑战展示了最先进的性能,现有的CNN架构如AlexNet和GoogLeNet可以很容易地修改来生成CAM。
为了生成图像的CAM,在最后一个卷积层之后执行全局平均池,并将结果交给一个分类层来预测图像的类概率。分类层中与类相关的权值代表了该类最后一个卷积层的特征映射的重要性。
形式上,表示F = {
F
1
,
F
2
,
.
.
,
F
M
F_1,F_2,..,F_M
F1,F2,..,FM}为最后一层卷积的M个特征映射,W为分类层的N个M个权矩阵,其中N为类的个数。然后,c类的CAM用于图像I,公式:
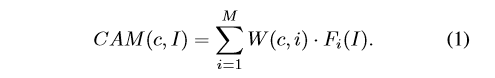
对于图像的CAM,使用参考论文1中提出的方法生成一个边界框。简单地说,首先对CAM进行阈值处理,生成一个二值前景/背景图,然后在前景像素之间查找连接组件。最后,将一个紧密的边界框安装到最大的连接组件上。
参考论文1: B. Zhou, A. Khosla, L. A., A. Oliva, and A. Torralba. Learning deep features for discriminative localization. In CVPR, 2016. 1, 2, 3, 4, 5, 6, 7, 8
Weakly-supervised action localization
给定一组未修剪的视频
V
s
e
t
V_{set}
Vset = {
V
1
,
V
2
,
…
,
V
N
V_1,V_2,…,V_N
V1,V2,…,VN} 和视频类标签,
目标:学习一个行为定位,它可以预测测试视频
V
t
e
s
t
V_{test}
Vtest的一个行为的标签,以及它的开始和结束时间。
问题:对于任何视频,网络将主要关注于有高辨别力的帧,以优化分类精度,而不是识别所有相关帧。受在图像中隐藏块的想法启发,建议在视频中隐藏帧以改进动作定位。
解决:在训练过程中,统一采样每个视频的视频总帧数。然后将
F
t
o
t
a
l
F_{total}
Ftotal帧划分为大小固定的连续段
F
s
e
g
m
e
n
t
F_{segment}
Fsegment。即,有
F
t
o
t
a
l
/
F
s
e
g
e
m
n
t
F_{total}/F_{segemnt}
Ftotal/Fsegemnt个片段。就像使用图像块一样,在将每个片段输入到深度动作定位器网络之前,使用概率隐藏每个片段。使用前一节中描述的过程生成类激活映射(CAM)。在本例中,我们的CAM是一个一维映射,表示行为类的有判别力的帧。在这个映射上应用阈值来获得行为类的开始和结束时间。
实验
数据集和评估指标
- 使用ILSVRC 2016来评估目标定位的准确性。
对于训练,使用了120万张带有类标签(1000个类别)的图像。验证集数据上与baseline进行比较。 - 使用三个评价指标来衡量性能:
1)Top-1定位精度(Top-1 Loc): 概率最高的预测类别与真实标签类相同的图像的一部分,并且该类别的预测边界框与真实标签框的IoU大于50%。
2)已知真实标签类定位精度(GT-known Loc):预测边界框与真实标签类的真实框IoU超过50%的图像片段。由于文章的方法主要是为了提高定位精度,所以用这个标准来测量与分类性能无关的定位精度。
3)使用了分类精度(Top1 Clas)来衡量Hide-and-Seek对图像分类性能的影响。 - 对于行为定位,使用了THUMOS 2014验证数据,它包含了101个动作类的1010个未修剪的视频。为分类任务训练所有未修剪的视频,然后评估20个具有时间注释的类的定位。每个视频可以包含一个类的多个实例。评估计算平均精度均值(mAP),并且如果其带真实标签的IoU>θ,则预测是正确的。θ分别取值0.1,0.2,0.3,0.4和0.5。由于关注的是网络的定位能力,假设知道视频的真实类标签。
实现细节
目标定位
- 为了学习目标定位,使用了在参考文献1中引入的修改过的AlexNet和GoogLeNet网络(AlexNet- GAP和GoogLeNet- GAP)。
1)AlexNet- GAP与AlexNet在pool5(带有stride 1)之前是相同的,之后添加两个新的conv层。对于增加的conv层,其有512个内核,内核大小为3×3,stride 1,pad 1。
2)GoogLeNet-GAP,在inception-4e之后的层被删除,并添加一个单一的conv层。对于增加的conv层,其有1024个内核,内核大小为3×3,stride 1,pad 1。
对于AlexNet-GAP和GoogLeNet-GAP,最后一个conv层的输出都是一个全局平均池(GAP)层,然后是一个用于分类的softmax层。 - AlexNet-GAP:从头开始训练网络55个epoch,BatchSize:128,lr:0.01,lr逐渐降低到0.0001。没有将conv过滤器分组在一起(它产生的统计上的Top-1 Loc精度与为两个AlexNet- gap分组的版本相同,但具有更好的图像分类性能)。
- GoogLeNet-GAP:从头开始训练网络40个epoch,BatchSize:128,lr:0.01,lr逐渐降低到0.0001。每个conv层后添加BN层
- 在训练和测试期间网络保持完全相同的。
- 为了获得二进制fg/bg map,分别选择CAM最大值的20%和30%作为AlexNet-GAP和GoogLeNet-GAP的阈值;通过对训练数据的定性分析,确定了阈值。
- 在测试中,平均10种裁剪(4个角加中心,以及他们的水平翻转),以获得类概率和定位图。
- 在对预先训练好的网络进行微调时,定位/分类性能也很相似。
行为定位
- 对于行为定位,使用在 Sports 1 million 上预先训练的模型计算C3D fc7 特征。
- 计算10feats/sec(每个特征计算超过16帧),并从视频中均匀采样2000个特征。
- 然后将视频分成20个等长的片段,每个片段包含 F s e g m e n t F_{segment} Fsegment = 100个feature。在训练中,我们使用 p h i d e p_{hide} phide = 0.5隐藏每个片段。
- 对于行为分类,将C3D特征作为输入输入到一个CNN,它有两个conv层,然后是全局最大池和软最大分类层。每个conv层有500个大小为1×1、stride 1的kernel。
- 对于任何隐藏帧,指定为数据集均值C3D特征。
- 对于阈值,选择CAM最大值的50%。阈值后的所有连续段都被认为是被预测。
目标定位定量结果
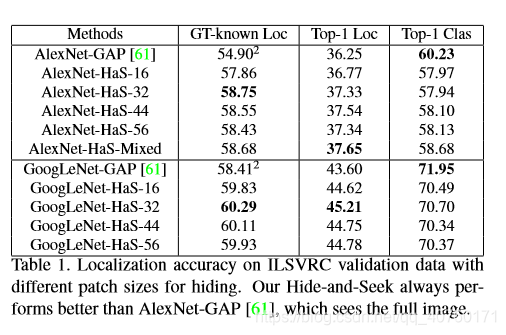
- 首先分析了ILSVRC验证数据的目标定位精度。下表显示了使用Top-1 Loc和GT-known Loc评估指标的结果。AlexNet-GAP是baseline,其作者的方法是AlexNet-HaS -N,其中大小为N×N的patch在训练过程中以0.5的概率隐藏。
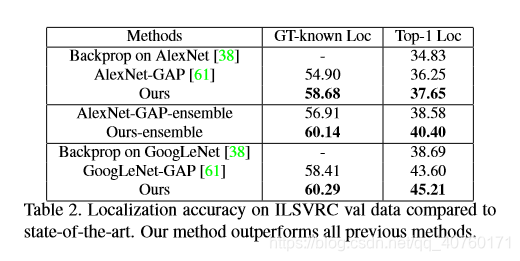
- 与先进技术比较
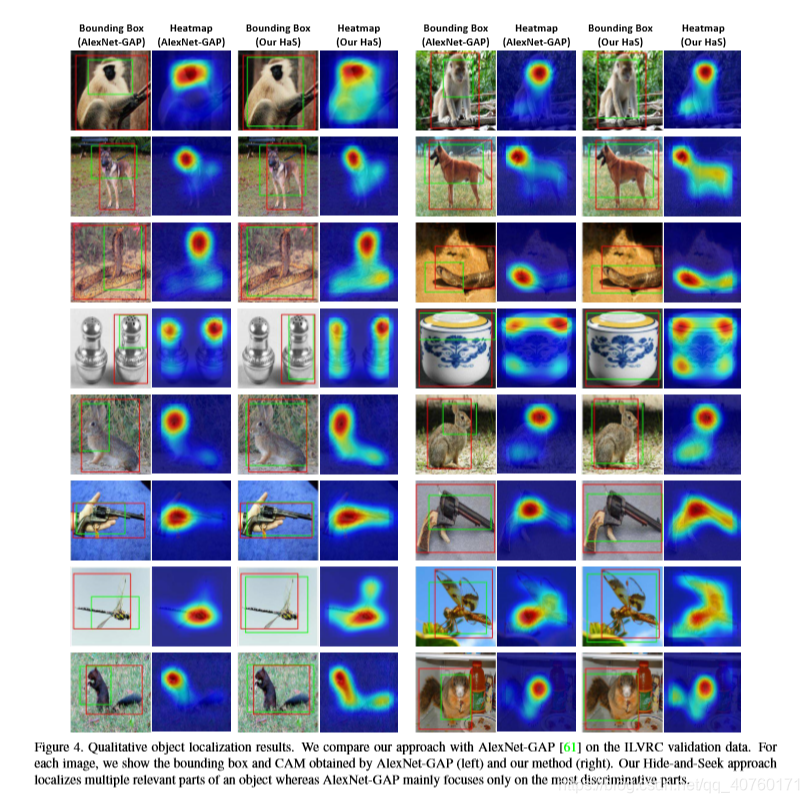
目标定位的定性结果
将通过AlexNet-HaS方法得到的类激活图(CAM)和边界框与通过AlexNet-GAP得到的类激活图和边界框进行了可视化,如下图
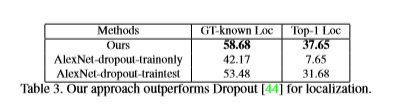
进一步分析
- 方法胜过dropout
- 全局平均池化 VS 全局最大池化
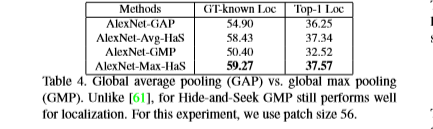
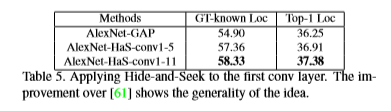
- Hide-and-Seek应用于第一层卷积
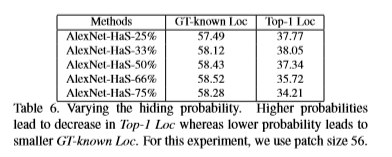
- 隐藏概率比较
- 行为定位结果



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









