







Action Recognition from Single Timestamp Supervision in Untrimmed Videos
作者贡献
- 提出了一种从单个时间戳初始化的采样分布,以选择相关的帧来训练行为识别分类。(因为时间戳的粗糙定位和每个行为有不同的时长,所以最初的抽样分布可能与实际情况不完全相符,如下图第一行)
- 提出了一种在训练中利用分类响应来更新采样分布参数的方法,以便采样更多相关的帧和增强分类,如下图第二行。
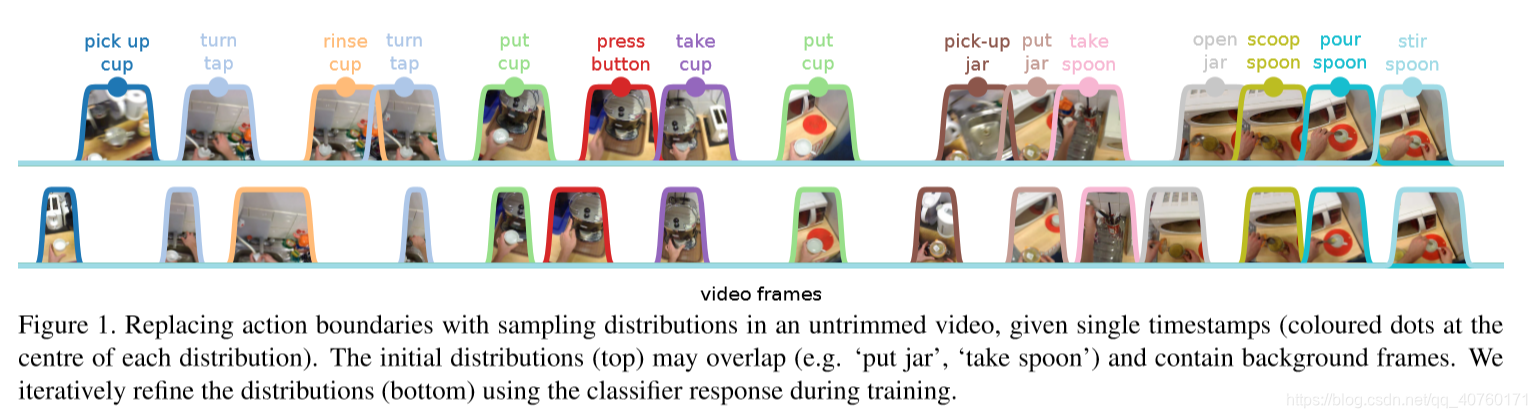
从单个时间戳监督中识别
数据:为细粒行为识别任务提供一个包含多个不同行为的未修剪视频的集合。
任务:训练一个分类器
f
(
x
)
=
y
f(x) = y
f(x)=y,即一帧(或者一组帧)
x
x
x作为输入以从可视化内容
x
x
x中识别类别
y
y
y
差别:典型的监督方法的注释提供了行为的开始/结束时间,为未修剪的视频提供时间边界。而本文实验为每个行为实例提供一个单一的时间戳来代替这些注释。
难点:如下图所示, b)中只有大致对齐的单个时间戳可用时,不清楚哪些帧可以用来训练分类器。在靠近行为时,与单个时间戳对应的帧可以表示背景或另一个行为。此外,行动的范围是未知的。
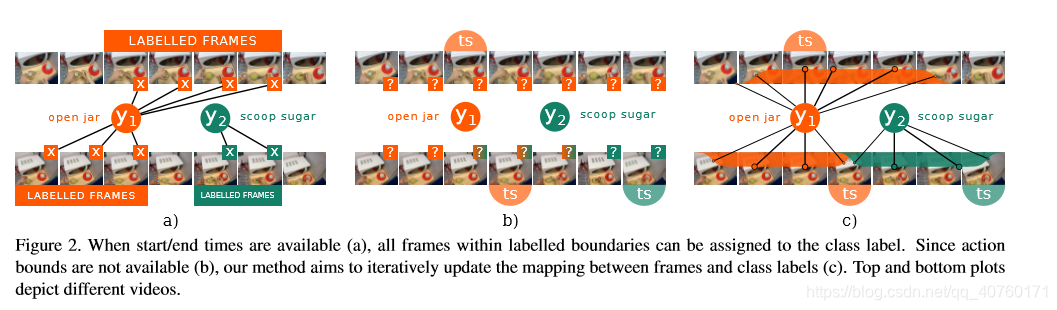
采样分布
总:建议用一个采样分布来代替不可用的动作界限,这个抽样分布可以用来选择帧来训练分类器。为简单起见,我们假设这里的分类器是基于框架的,并将单个框架作为输入。我们稍后放松这个假设。
- 采样分布应类似于强分类器的输出,即对于包含动作的连续帧得高分(类似于plateaus一样平滑??),其他位置的响应则较低。
- 此函数的另一个理想属性是可微性,因此可以学习或调整它。
- 高斯概率密度函数(pdf):通常用于概率模型,但是它并没有一个plateaus响应,相反,它围绕峰值,并从峰值不断地下降。
门函数(给定一个阈值,在阈值内为1,否则为0):能展现一个明显的plateaus,但是不可微。
解决: 提出了一个函数来对采样分布的概率密度建模,公式如下:
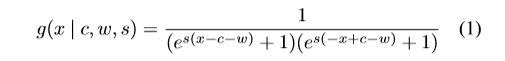
其中,c模拟plateaus的中心,w和s分别模拟它的宽度(2w)和坡的抖度。函数的范围是[0, 1]。
初始化模型
-
定义:
a i v a^v_i aiv:一个未修剪的视频v中的第 i i i个单一时间戳。
y i v y^v_i yiv:一个未修剪的视频v中的第 i i i个单一时间戳对应的类标签。
其中, i i i∈{ 1... N v 1...N_v 1...Nv}, v v v∈{ 1... M 1...M 1...M}
对于每个 a i v a^v_i aiv,初始化一个以时间戳为中心的采样分布,默认参数是 w w w和 s s s。
使用 β i v = ( c i v , w i v , s i v ) β^v_i = (c^v_i, w^v_i, s^v_i) βiv=(civ,wiv,siv)表示对应采样分布的参数,其中 c i v = a i v c^v_i = a^v_i civ=aiv。
使用 G ( β i v ) G(β^v_i) G(βiv)表示相应的抽样分布, 使用 G ( β i v ) G(β^v_i) G(βiv)来采样训练帧用于表示类 y i v y^v_i yiv。
注:由于某些时间戳非常接近,初始化的plateaus可能会有相当大的重叠(如图1,顶部)。可以通过减少plateaus。但是并不知道每个行为的时间范围,这个做法可能会导致失去一些重要的帧。因此允许重叠,并设置 w w w和 s s s让所有行为都有机会从相同的帧数中学习。 -
一些采样的帧可能是背景帧或者与其他的行为类别关联。为了减少噪音,给所有从基于分类响应的未修剪的视频中采样的帧排序,并选择置信度最高的帧。公式如下:
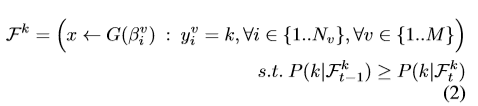
(取分布中对应的类为 k k k的所有采样帧,按照它们的softmax分数排序)其中 P ( k ∣ x ) P(k|x) P(k∣x)表示帧 x x x对于 k k k类的softmax分数。 -
对于每个类别 k k k,选择分数最高的 T T T个帧进行训练:
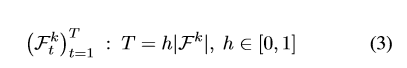
使用这种方法,选择分类器置信度最高的帧,也就是选择最相关的帧。
注意,公式3对所有视频的帧进行了排序,因此与一个视频中行为重复的次数无关。 使用这种策略,可以向分类器提供更少的噪声样本,但仍然可能丢失初始稳定状态之外的相关帧。 -
在对基本模型进行了训练之后,我们对采样分布进行了更新,目的是为了纠正错位的plateaus,以便能够提供更多相关的帧。
更新分布参数
假设最初的plateaus与行动是合理一致的。在这样的假设下,迭代地更新采样分布参数,在更相关的帧上重塑和移动初始化的plateaus ,以增强分类器。执行步骤:
- 从softmax分数中生成更新建议(proposals)
- 对建议进行排名,以选择提供最可靠更新的参数。
Finding Update Proposals
对于每个采样分布
G
(
β
i
v
)
G(β^v_i)
G(βiv)根据给定类别
k
=
y
i
v
k = y^v_i
k=yiv的softmax分数,更新建议。
- 将公式1中的pdf值与softmax在多个位置和时间尺度上的得分进行了拟合。这是通过在softmax得分上设置阈值τ∈[0,1],并找到softmax得分高于τ的连续帧的所有连通分量。
- 对于每个连通分量,拟合pdf,并将生成的拟合参数视为更新采样分布的一个候选。由于τ是变量,所以可以产生多个不同尺度下建议。如下图所示
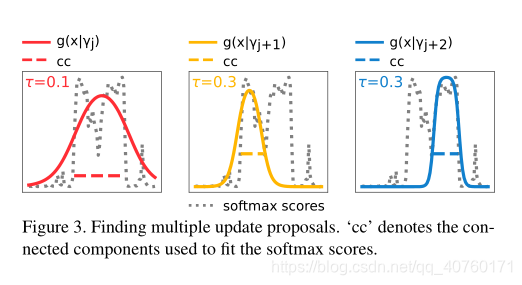
-
γ
j
v
=
(
c
j
v
,
w
j
v
,
s
j
v
)
γ^v_j = (c^v_j, w^v_j, s^v_j)
γjv=(cjv,wjv,sjv)表示每个更新建议
因此, β i v β^v_i βiv的更新建议集如下:
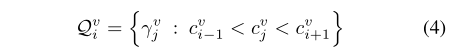
Selecting the Update Proposals
- 首先通过如下方式对给定的plateau函数
g
(
β
i
v
)
g(β^v_i)
g(βiv)求平均值来定义得分
ρ
ρ
ρ。
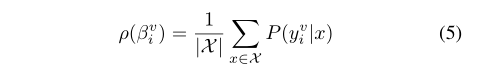
其中, χ χ χ = { x : g ( β i v ) > 0.5 x: g(β^v_i) > 0.5 x:g(βiv)>0.5} - 为每个建议
γ
j
v
∈
Q
i
v
γ^v_j ∈ Q^v_i
γjv∈Qiv定义置信度Ψ:
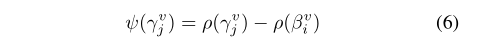
- 抛弃那些置信度低的更新建议,为每个
β
i
v
β^v_i
βiv选择置信度最高的建议:
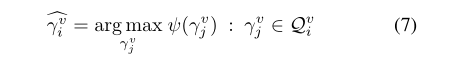
Updating Proposals
只更新置信度分数高的建议。
- 根据他们的置信度排序所有选择的更新建议的顺序。
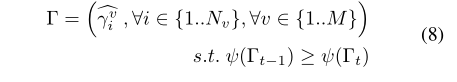
- 选择分数最高的R个建议:
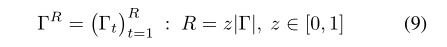
- 更新相应的采样分布:
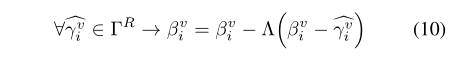
其中, Λ Λ Λ = { λ c , λ w , λ s λ_c, λ_w, λ_s λc,λw,λs}是控制更新速度的超参数。
注:对不同的变量(c, w, s)使用不同的更新速率, w i v , s i v w^v_i,s^v_i wiv,siv更新公式相似:
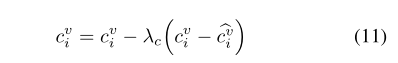
- 更新提案直到聚合。这很容易通过观察所选提案的平均置信度接近0来评估。
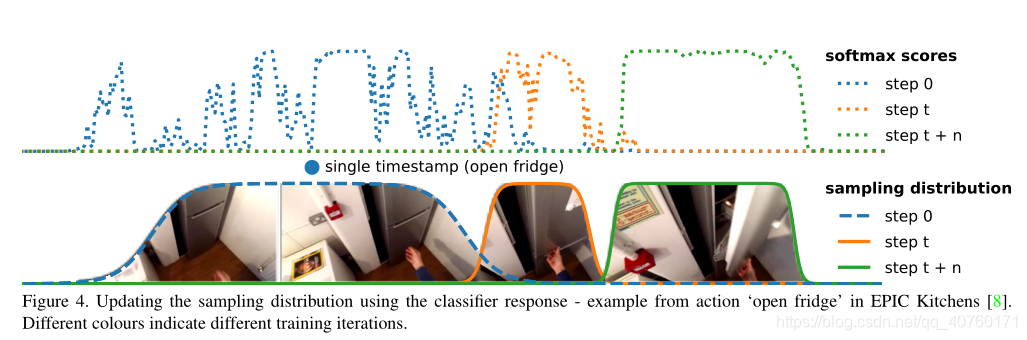
如下图,显示了一个“开冰箱”类的更新采样分布。标记的时间戳和相应的初始采样分布(蓝色点线和蓝色虚线)与行为没有很好地对齐,它们都位于实际发生动作之前。 经过几次迭代后,分类器将对位于初始plateau区域之外的帧(橙色点线,顶部)进行了置信度更高的预测。 最终的采样分布(纯绿色,底部)与打开冰箱的对象的帧成功对齐。
实验
数据集
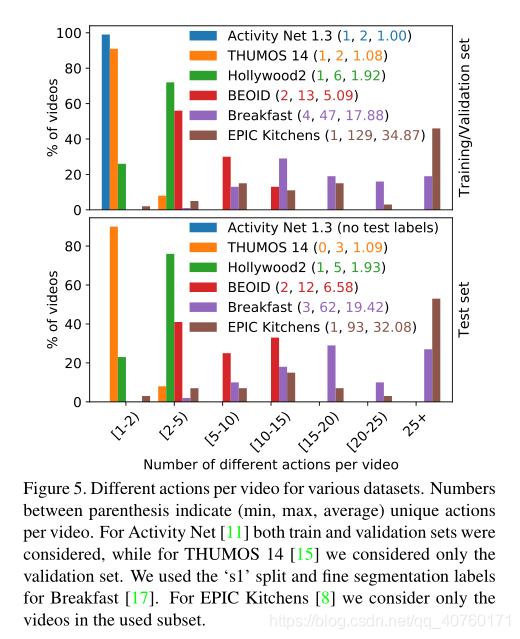
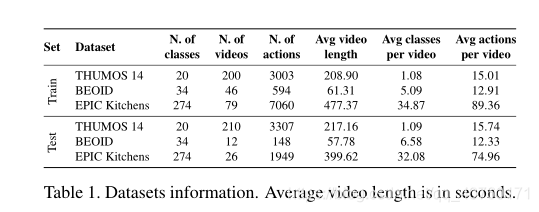
如上图所示,根据训练(顶部)和测试(底部)集中每个视频的不同动作数量,比较了用于行为识别和定位的各种通用数据集。该图显示了这些数据集的范围。
数据集:THUMOS’14,BEOID 和EPIC Kitchens
- THUMOS’14:使用在时间上被标记为20类的视频子集。
BEOID:将未修剪的视频按80-20%的比例随机分割以进行训练和测试。
EPIC Kitchens:使用数据集的子集选择参与者P03,P04,P08和P22。总共13.5小时的镜头时长,该子集占整个数据集的25%。 - 表1汇总了所选数据集的各种统计信息。尽管考虑了整个数据集的一个子集,但EPIC Kitchens仍然是最具挑战性的,因为它的视频很长,包含许多不同的动作。此外,EPIC-Kitchens提供了新颖的旁白注释。
实现细节
- 使用预先训练BN-Inception。
- 使用堆栈大小为5的TV-L1光流图像。
训练:
- 每个样本采样5个帧行为实例,并使用平均共识。
- 与使用开始/结束动作时间进行的全面时间监督相比,栈是在大小相等的片段中随机抽样的。
- 为了更快地进行评估,从裁剪后的测试视频中均匀采样了10帧,并使用中心裁剪获取平均分作为最终预测。
- 使用批次大小为256,固定学习率等于0.0001,dropout = 0.7且无权重衰减的Adam Optimiser。
所有数据集:
- 使用w = 45帧(1.5 seconds at 30 fps)和s = 0.75初始化采样分布。
- 训练基本模型500epoches,以确保足够的初始化,然后再训练500个epoch更新运行该方法的采样分布。
- 最初的500个epoches足以使测试错误在更新开始之前在所有实验中收敛。在通过 cur-riculum learning训练基本模型之后,逐渐增加h(请参见公式3),直到达到h = 1,这对应于使用所有采样帧。
- 使用固定的z = 0.25来选择前R个更新建议(请参见公式9)。改变h来控制训练帧中的噪声,并保持z固定。 z的增加主要是加快分布参数的更新,类似于更改方法的学习率。
- 为了产生更新建议,使用τ∈{0.1,0.2,…,1}并丢弃少于15帧的连接分量。
- 为所有数据集设置更新参数(λc,λw,λs)=(0.5,0.25,0.25),每20个epoches更新一次采样分布。
单一时间戳
EPIC Kitchens数据集采用了两个阶段的注释方式:参与者首先通过音频现场叙事对视频进行叙事,以生成所执行动作的大致时间位置,然后使用众包来细化动作边界。我们将叙述开始时间戳记用作训练的单个时间戳。这些时间戳来自旁白音轨,相对于视频中发生的动作而言,显示出具有挑战性的偏移量: 55.8%的旁白时间戳未包含在相应的带标签的边界中。对于超出范围的时间戳,到标记边界的最大,平均和标准偏差距离分别为11.2、1.4和1.6秒。据我们所知,本文首次尝试仅使用旁白时间戳在EPIC Kitchens上进行细粒度的行为识别训练。
THUMOS 14和BEOID没有单个时间戳注释。我们从可用的标签模拟粗略的单个时间戳,从均匀分布[
σ
i
−
1
s
e
c
,
ε
i
+
1
s
e
x
σ_i − 1sec ,ε_i+1sex
σi−1sec,εi+1sex]中绘制每个
a
i
a_i
ai,其中
σ
i
σ_i
σi和
ε
i
ε_i
εi表示行为i标记的开始和结束时间。这大致模拟了EPIC Kitchens的实时评论注释方法。将这组注释称为TS。
还对所有三个数据集使用另一组单个时间戳,其中每个
a
i
a_i
ai使用均值
(
σ
i
+
ε
i
)
/
2
(σ_i+ε_i)/2
(σi+εi)/2和标准偏差1秒的正态分布进行采样。这假定注释者在被要求仅提供一个时间戳时可能选择一个靠近动作中间的点。我们将第二个点集称为TS in GT。
结果
评估指标:top-1 accuracy
- 首先使用 curriculum learning(CL)评估TS时间戳,以训练h∈{0.25,0.50,0.75}的基本模型运行实验,以及使用所有采样帧进行训练(h = 1)。
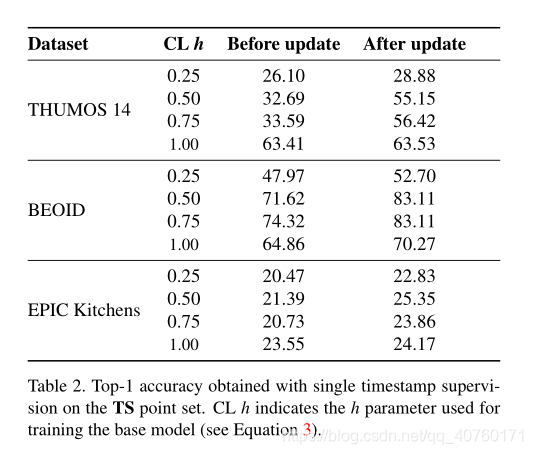
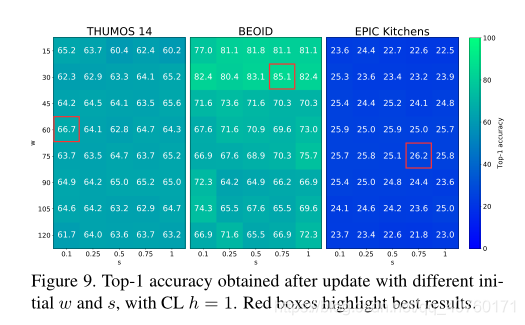
如表所示,对于所有数据集和所有h值,更新后获得的结果始终优于更新前获得的结果。对于BEOID和EPIC,CL策略减少了训练基本模型时的噪点帧数量,即h = 0.50时可获得最佳结果。但是,在THUMOS 14上,基本模型的CL方法效果较差,当在训练中使用所有帧时,将获得最佳性能。 - 在图7中对上述进行了进一步分析,该图说明了在更新之前被标记为行为边界(仅用于绘图)包围的选定帧和废弃帧的百分比。

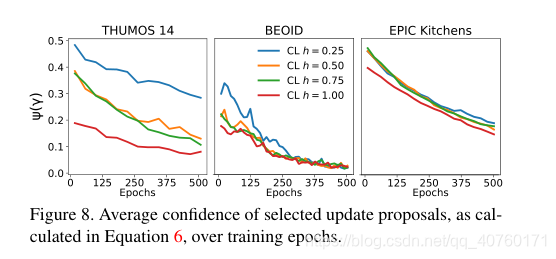
- 在图8中,通过在训练时期内绘制所选更新建议的平均置信度来评估更新收敛。在所有情况下,平均置信度稳步下降,表明分类器的收敛性。
- 我们在图6中说明了每个数据集中的一些示例,这些示例显示了采样分布的迭代更新。这些示例是根据TS点集上CL h = 0.50获得的结果绘制的。
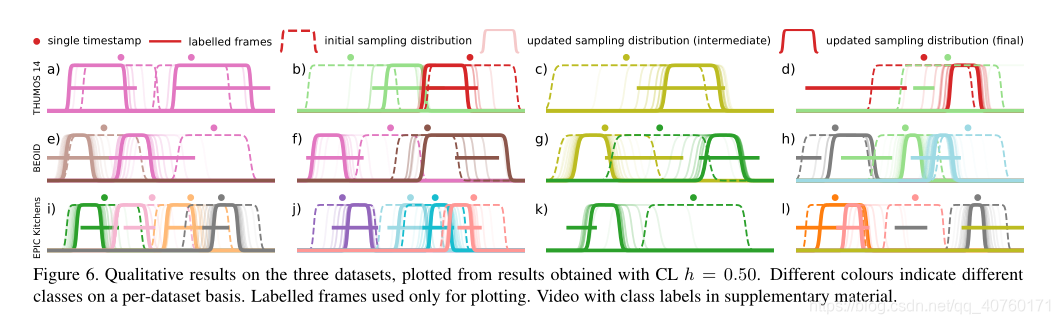
即使初始plateaus与其他不相关的行为(子图e,g,i,j)重合,或者初始plateaus包含很多背景(子图b,c,e,f),更新方法也能够成功地优化采样分布。 ,k)。在子图g(浅绿色高原)和h(灰色高原)中,初始plateaus被推到相关框架的外面。在这两种情况下,训练示例的数量很少(8和5个实例),单个时间戳记几乎总是位于动作之外。在子情节1中,粉红色和灰色的初始plateaus相对于相应的动作发生了偏移,反映了EPIC Kitchens在使用旁白时间戳时所带来的挑战。尽管更新方法设法恢复了粉红plateaus的正确位置,但灰色plateaus并未收敛到相关帧。
参数初始化
通过网格搜索评估初始参数w和s对采样分布的影响。 图9比较了使用不同的(w,s)组合更新后获得的top-1精度,使用CL h = 1.00。
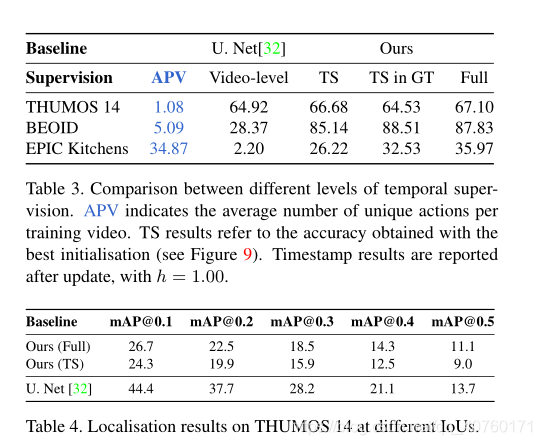
与全监督水平比较














 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









