







Self-Erasing Network for Integral Object Attention
作者贡献
问题:随着训练迭代,对抗性擦除可能会导致注意区域逐渐扩展到非目标的区域。
解决:提出了Self-Erasing NetWork。
Self-Erasing Network
思想
对于给定的初始attention map,将图片在空间上分成三个区域,即内在的“attention zone”,外在的“background zone”和中间的“potential zone”。通过引入背景先验,目标是将attention network 驱动到一个自擦除状态,这样可观察区域就可以限制在非背景区域,避免已经接近完美状态的attention 区域的持续扩散。为了实现这一目标,需要解决以下两个问题:(1)只给出图像级标签,如何定义和获取背景区域。(2)如何将自我擦除思想引入attention network。
背景先验
δ
h
δ_h
δh和
δ
l
δ_l
δl:阈值(
δ
h
>
δ
l
δ_h > δ_l
δh>δl)
- 对于给定的初始attention map(
M
A
M_A
MA),将
M
A
M_A
MA中值小于
δ
l
δ_l
δl的作为background zone:
T A , ( i , j ) = − 1 T_{A,(i,j)} = -1 TA,(i,j)=−1 if M A , ( i , j ) ≤ δ l M_{A,(i,j)} ≤ δ_l MA,(i,j)≤δl - 将
M
A
M_A
MA中值大于于
δ
h
δ_h
δh的作为attention zone:
T A , ( i , j ) = 0 T_{A,(i,j)} = 0 TA,(i,j)=0 if M A , ( i , j ) ≥ δ h M_{A,(i,j)} ≥ δ_h MA,(i,j)≥δh - T A , ( i , j ) = 1 T_{A,(i,j)} = 1 TA,(i,j)=1 if otherwise
Self-Erasing Network

网络的架构由三个分支组成,分别表示为
S
A
S_A
SA,
S
B
S_B
SB,
S
C
S_C
SC,如上图所示。
- S A S_A SA:确定一个初始attention
- S B S_B SB和 S C S_C SC都插入了C-ReLU层
self-erasing 策略1
对于
S
A
S_A
SA产生的
M
A
M_A
MA,得到三元掩码
T
A
T_A
TA,将
T
A
T_A
TA送入
S
B
S_B
SB的C_ReLU层,公式如下:
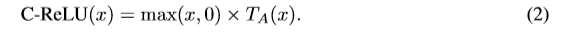
优点:使background zone不被发现,并确保potential zone的潜在性
self-erasing 策略2
通过将background zone设为1,其他区域设为0将
T
A
T_A
TA转为一个二进制到的掩码,将其输入
S
C
S_C
SC的C_ReLU层
损失函数
L
=
L
S
A
+
L
S
B
+
L
S
C
L=L_{S_A}+L_{S_B}+L_{S_C}
L=LSA+LSB+LSC
对于所有分支,使用交叉熵损失将多标签分类问题视为M个独立的二分类问题,其中M是语义类别的数目。因此,对于给定的语义标签y,如果n∈y则
S
A
S_A
SA和
S
B
S_B
SB的语义标签
l
n
=
1
l_n=1
ln=1,否则
l
n
=
0
l_n=0
ln=0。
S
C
S_C
SC的标签向量为0。
获得最后的attention maps
- 在测试期间,不使用 S C S_C SC支流。由 S A S_A SA产生 M A M_A MA, S B S_B SB产生 M B M_B MB,进行归一化到[0, 1]产生 M ^ A \widehat{M}_A M A和 M ^ B \widehat{M}_B M B,然后或者融合attention map( M F M_F MF)其中, M F , i = m a x ( M ^ A , i , M ^ B , i ) M_{F,i}=max(\widehat{M}_{A,i}, \widehat{M}_{B,i}) MF,i=max(M A,i,M B,i)。
- 将图像水平翻转,根据上述得到另一个融合attention map( M H M_H MH)
- 计算最后的attention map, M f i n a l , i = m a x ( M F , i , M H , i ) M_{final,i}=max(M_{F,i},M_{H,i}) Mfinal,i=max(MF,i,MH,i)
弱监督语义分割

为了测试attention network的质量,将生成的attention map应用到最近流行的弱监督语义分割任务中。具体来说,给定一个输入图像I,首先简单地对其显著性映射进行归一化,得到D,取值范围为[0,1]。设y是I的图像级别标签集合,从{1,2,…,M}中取值,其中M是语义类的数量。
A
c
A_c
Ac是与标签 c∈y相关联的attention map之一,可以根据算法1计算 “proxy ground-truth” 。然后,利用下面的调和均值函数来计算像素Ii属于c类的概率。
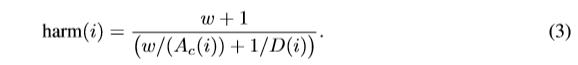
实验
实现细节
数据集和评估指标:在PASCAL VOC 2012图像分割基准上评估方法,该基准包含20个语义类和背景类。在训练集上对模型进行attention和分割任务的训练。使用平均相交-过并集(mIoU)作为评价指标。
网络设置:
- 基本模型:VGGNe,丢弃最后三个全连接层,将三个具有512通道和内核大小为3的卷积层连接到主干上。然后,使用一个20通道卷积层和一个全局平均池化层来预测每个类别的概率。
- 批量大小设置为16,重量衰减为0.0002,学习率为0.001,经过15,000次迭代后除以10。
- 总共进行了25,000次迭代。
- 为了增加数据,使用论文( Deep residual learning for image recognition)的策略。
- S B S_B SB中的阈值 δ h δ_h δh和 δ l δ_l δl设置为最大值的0.7和0.05。
- S C S_C SC中的阈值 ( δ h + δ l ) / 2 (δ_h +δ_l) / 2 (δh+δl)/2。
- 对于分割任务,为了与其他工作进行比较,采用标准的Deeplab-LargeFOV架构作为分割网络,其基础是在ImageNet数据集上预训练的VGGNet[32]。
- 还尝试了ResNet版本,Deeplab-LargeFOV体系结构,并报告了两个版本的结果。
- 网络和条件随机域(CRFs)超参数与( Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs)相同。
Self-Erasing的角色
质量:如下图

PASCAL VOC 2012定量结果:如下表

与先进的比较:如下表
















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









