







Temporal Structure Mining for Weakly Supervised Action Detection
作者贡献
提出了时间结构挖掘(TSM)方法
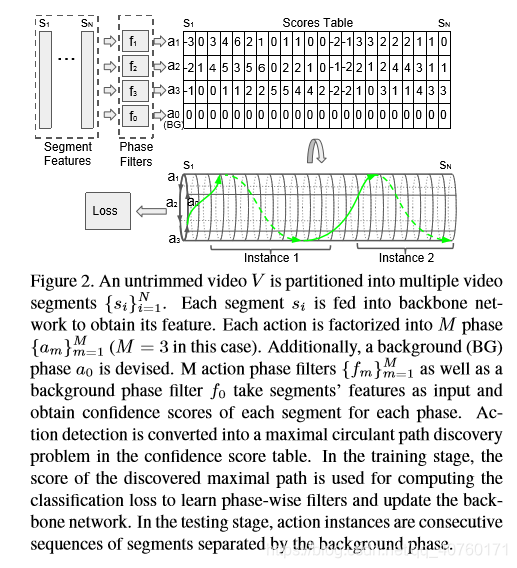
图2显示了提出的时间结构挖掘(TSM)方法的体系结构。如图所示,一个未修剪的视频被分割成多个段,这些段的特征来自于主干网络。阶段滤波器以分段级特征作为输入,生成阶段级置信分表。将动作检测转化为在分数表中寻找最大循环路径,利用最大循环路径的分数计算分类损失。梯度是根据更新TSM的损失推导出来的。
与SMS比较
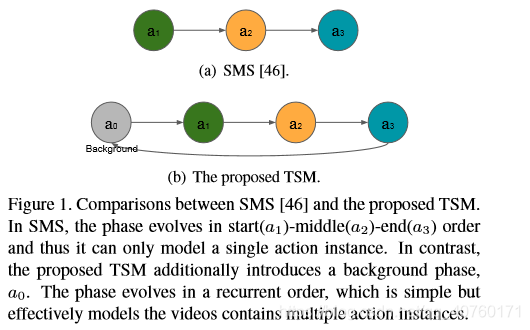
- TSM引入了一个额外的背景阶段来对背景建模,它在一个未修剪的视频中分离多个动作实例。简单但有效地解决了包含多个动作实例的视频中的动作检测问题。
- 在SMS中,阶段按照开始(a0)-中间(a1)-结束(a2)顺序发展。因此,它只能对单个操作实例建模。相比之下,TSM则是按照一个循环的顺序发展,并有效地对包含多个动作实例的视频进行建模。
方法
定义
- 对于给定的视频 V V V,分解成 N N N个短片段 [ S 1 , S 2 , . . . , S N ] [S_1,S_2,...,S_N] [S1,S2,...,SN]。
- 一个类别有 M M M个行为阶段{ a j a_j aj} j = 1 M ^M_{j=1} j=1M,同时背景表示为 a 0 a_0 a0。
- x i = g ( s i , W ) : x_i=g(s_i,W): xi=g(si,W):片段 s 1 s_1 s1从主干网络中获得特征, W W W包含主干网络的参数
-
v
c
,
i
j
v^j_{c,i}
vc,ij是
s
i
s_i
si中
c
c
c类的第
j
j
j阶段
a
j
a_j
aj的置信度分数:
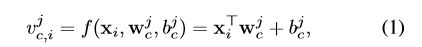
使用 v c , j j v^j_{c,j} vc,jj构建置信度分数表(如下图所示):
- 定义 ( i , p i ) (i,p_i) (i,pi): i i i是片段索引, p i p_i pi是阶段索引, p i ∈ [ 0 , M ] p_i ∈ [0,M] pi∈[0,M]。
- 定义 [ ( 1 , p 1 ) , . . . , ( N , p N ) ] [(1,p_1),...,(N,p_N)] [(1,p1),...,(N,pN)]:作为置信度分数表的路径。
- 定义 P c = [ p 1 , . . . , p N ] P_c=[p_1,...,p_N] Pc=[p1,...,pN] :为类别c的路径。
时间结构挖掘
- 路径约束:
给定在阶段 p i p_i pi中的片段 s i s_i si,下一个片段 s i + 1 s_i+1 si+1的阶段 p i + 1 p_i+1 pi+1只有两个选择:1)与 s i s_i si保持相同的阶段,2)演化到下一个阶段:
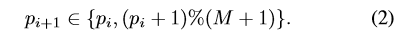
这种周期性的演化机制有效地处理包含多个动作实例的视频。 - 计算路径分数
F
c
(
P
C
)
F_c(P_C)
Fc(PC):
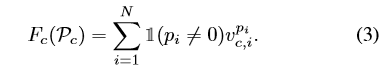
I ( p i ≠ 0 ) Ι(p_i ≠0) I(pi=0)是一个用于忽略背景阶段的指示器。由于背景分数不用于计算路径分数,所以设置 v c , i 0 = 0 v^0_{c,i}=0 vc,i0=0,即:
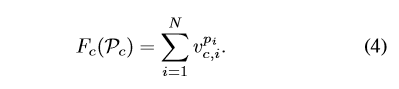
- 通过路径约束,挖掘最大路径分数:
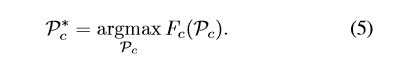
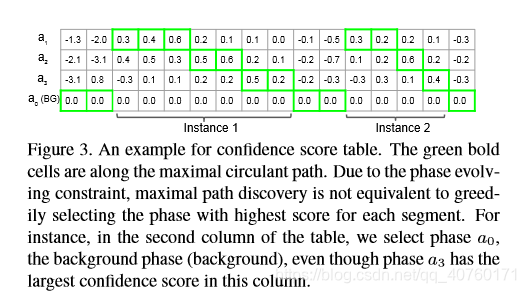
图3中用绿方框显示了一个最大循环路径的例子。
在训练阶段,最大循环路径 F c ( P c ∗ ) F_c(P^*_c) Fc(Pc∗)的分数代表了行为c在视频中的存在,它构造了分类损失。
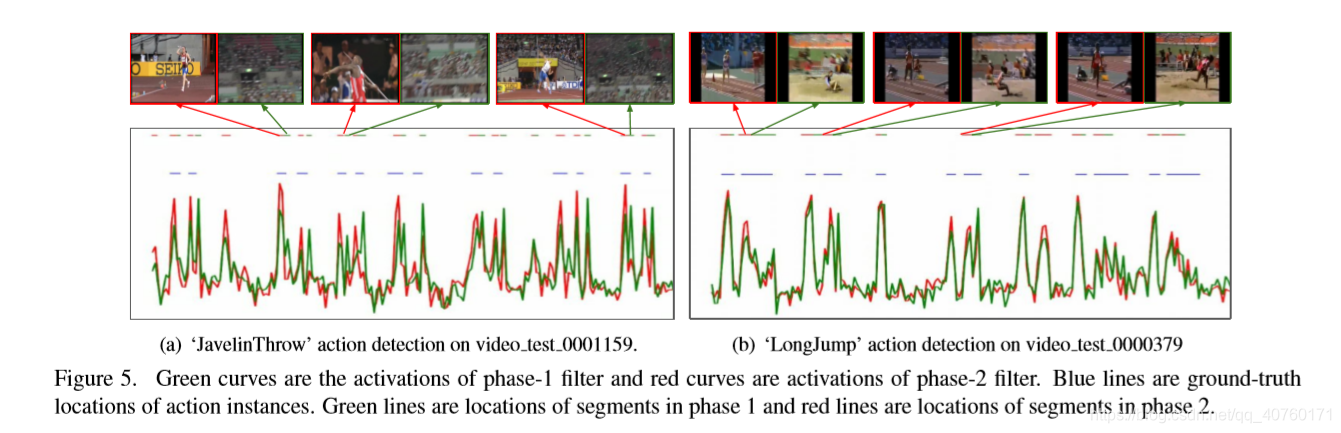
在测试阶段,通过背景阶段分离的连续段进行分组来检测某个类的动作实例。如图3所示,它检测两个由背景分隔的行为实例。
阶段过滤器学习
问题:阶段滤波器的学习依赖于发现的最大路径,同时最大路径的发现依赖于预先训练的阶段滤波器。它们之间的相互依赖导致训练过程不能按顺序进行。
解决:采用一个交替更新的策略,分为两步。
1)基于当前滤波器{
f
(
⋅
,
w
c
j
,
b
c
j
)
f(·,w^j_c,b^j_c)
f(⋅,wcj,bcj)}
j
=
1
M
^M_{j=1}
j=1M的输出,使用最大化路径发现得到
P
c
∗
P^*_c
Pc∗
2)使用
F
c
(
P
c
∗
)
F_c(P^*_c)
Fc(Pc∗)和视频的真实标签
y
c
∈
y_c∈
yc∈{0, 1}计算分类损失函数:
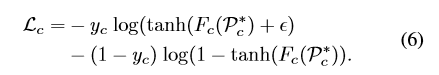
注:这里使用的是
t
a
n
h
(
)
tanh()
tanh(),而不是
s
i
g
m
o
i
d
(
)
sigmoid()
sigmoid(),因为对于背景类
P
c
^
=
[
0
,
.
.
.
,
0
]
\hat{P_c}=[0,...,0]
Pc^=[0,...,0],所以
F
c
(
P
c
^
)
=
0
F_c(\hat{P_c})=0
Fc(Pc^)=0,所以
F
c
(
P
c
∗
)
∈
[
0
,
+
∞
)
F_c(P^*_c)∈[0, +∞)
Fc(Pc∗)∈[0,+∞),所以
s
i
g
m
o
i
d
(
F
c
(
P
c
∗
)
)
∈
[
1
/
2
,
1
)
sigmoid(F_c(P^*_c))∈[1/2, 1)
sigmoid(Fc(Pc∗))∈[1/2,1),是的损失函数不够灵活,故使用
t
a
n
h
(
)
tanh()
tanh()。
迭代:
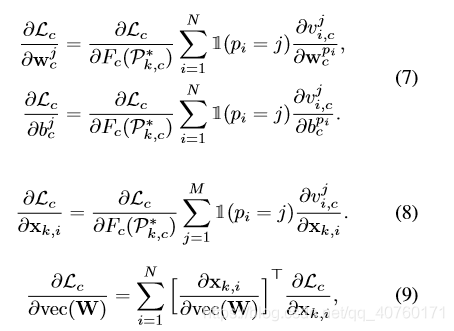
尽管该算法支持骨干网权值的更新,但由于计算资源的限制,在实现中对骨干网进行了修正,并将其作为特征提取模块。
流程:

- 每各类的每个阶段都有一个权重和偏置,对其进行初始化。
- 在每次迭代中,对每个视频提取特征,特征大小C×M×T。(类别,阶段,帧)
- 对每个视频特征对于每个类都有一个置信度分数表,基于算法2,找到视频对于每个类的 P k , c ∗ P^*_{k,c} Pk,c∗,并计算损失函数。
- 更新权重和偏置。
注:对于同一实例片段,应该是对应分数最大的那个类别。
最大路径发现
一种动态规划算法,节约发现路径时间,复杂度降为 O ( M N ) O(MN) O(MN)
- 重写约束:
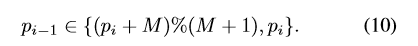
- 定义
S
c
,
i
j
S^j_{c,i}
Sc,ij:表示在类别c中:所有从片段
S
1
S_1
S1开始,在片段
S
i
S_i
Si(在阶段
j
j
j)的所有路径的最大分数。
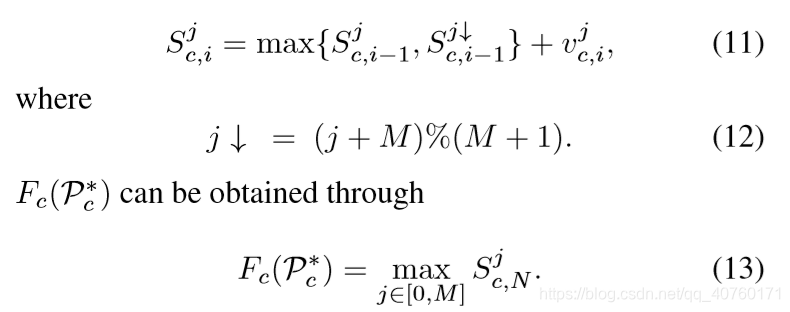
以图3为例,求得 S c S_c Sc列表如下:根据约束求得 p i p_i pi如标红数字。

具体算法流程如下:

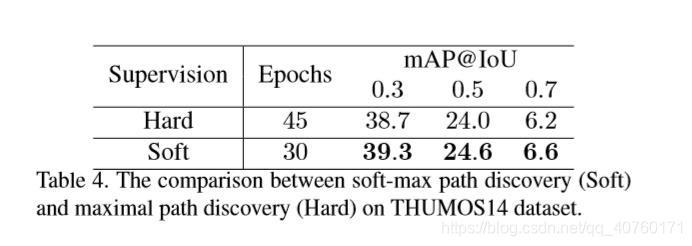
- 前面提到的最大路径发现过程只选择得分最高的路径。在这种情况下,梯度只在沿着最大路径的单元中反向传播,而忽略不是最大路径中的单元。为在分数表中挖掘更多信息,稳定训练。提出一种软最大路径发现算法:
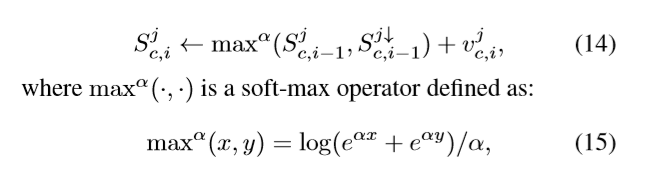
其中:
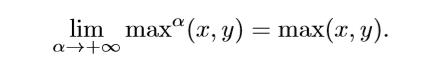
在这里 α = 10 α=10 α=10
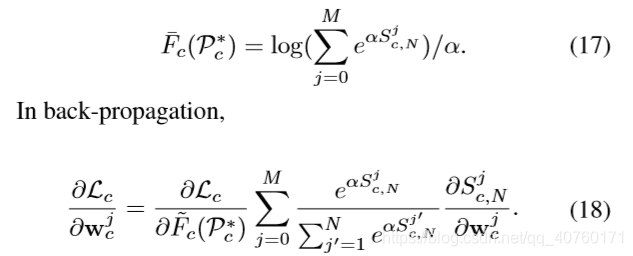
注:软最大路径发现仅在训练中执行。在测试中,仍然执行最大路径发现来检测动作实例。
具体算法流程如下:

实验
数据集和评估方法
数据集:THUMOS14 , ActivityNet 1.2和ActivityNet 1.3
评估标准:mAP
主干网络和双流融合
采用两种主干网络来提取视频片段的特征。
- 在 Kinetics数据集上预训练的I3D[5],一个比较基线STPN也采用了该数据集。
2.由UntrimmedNet预训练的TSN,它也被一个比较基线Auto-Loc使用。 - 虽然算法支持端到端训练,但是由于计算资源有限,只使用主干作为特征提取模块。
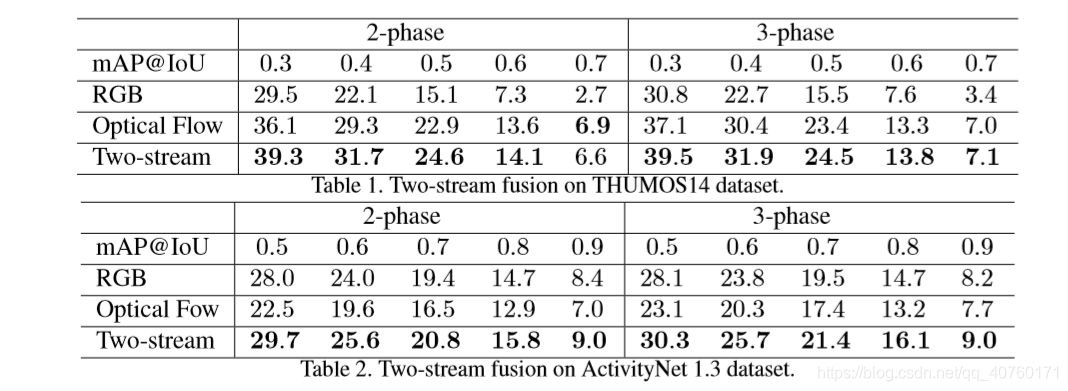
利用两个独立的网络,分别以RGB和光流作为输入。将两流网络的检测结果进一步融合,得到最终的检测结果。具体来说,给定一个视频V和一个特定的类c,首先分别基于单个RGB或光流网络获得候选的时间间隔
I
r
g
b
=
I_{rgb} =
Irgb= {
I
r
g
b
i
I^i_{rgb}
Irgbi}
i
=
1
K
r
g
b
^{K_{rgb}}_{ i=1}
i=1Krgb和
I
o
f
I_{of}
Iof = {
I
o
f
i
I^i_{of}
Iofi}
i
=
1
K
o
f
^{K_of}_{i=1}
i=1Kof。每个区间
I
∈
I
r
g
b
∪
I
o
f
I∈I_{rgb}∪I_{of}
I∈Irgb∪Iof的最终分数是由RGB网络和光流网络的分数结合得到的:
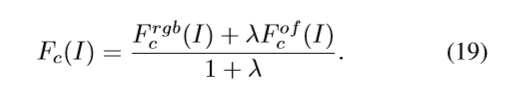
在THUMOS14数据集中,λ= 2组。在ActivityNet 1.2和1.3 ActivityNet数据集中,λ= 0.5。由于
I
r
g
b
∪
I
o
f
I_{rgb}∪I_{of}
Irgb∪Iof中存在重叠区间,根据其得分对区间进行非最大抑制。
实现细节
- 对于RGB流,将帧的最小维度缩放到256,并执行大小为224的中心裁剪。
- 对于光流场,采用了TV-L1光流算法。将得到的光流像素值截断到[20,20]范围,然后在-1和1之间重新标度。
- 从每个视频中以均匀的间隔采样400个片段。网络使用传统的SGD优化器进行训练。学习率初始化为0.005,每10个周期衰减为1个10。整个训练过程在30个epoch处停止,相对于初始化权值,性能相当稳定。
- 在测试时,对于每个类,根据它们的结构分数对检测到的候选位置进行排序。
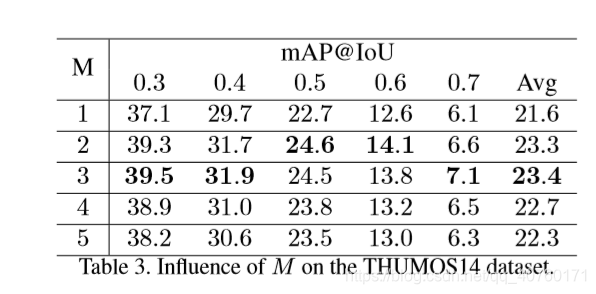
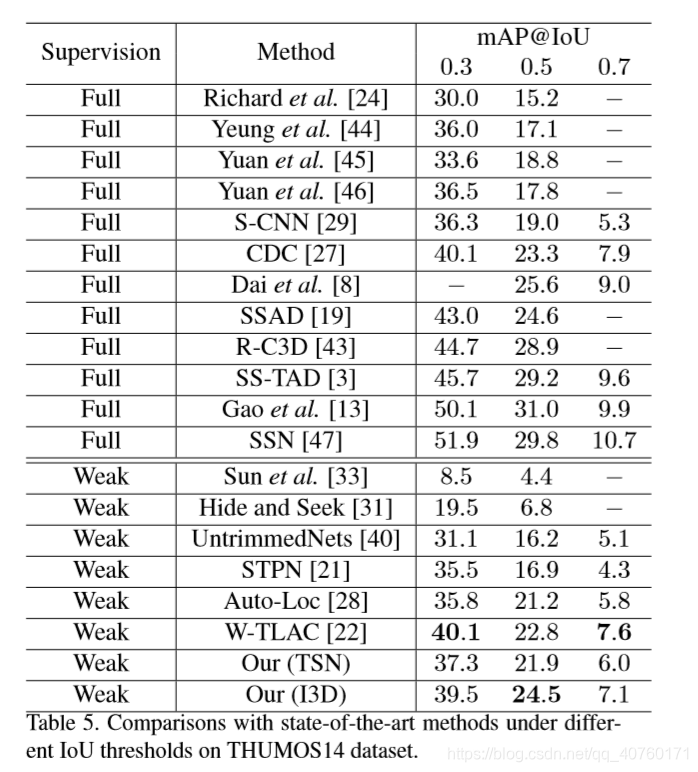
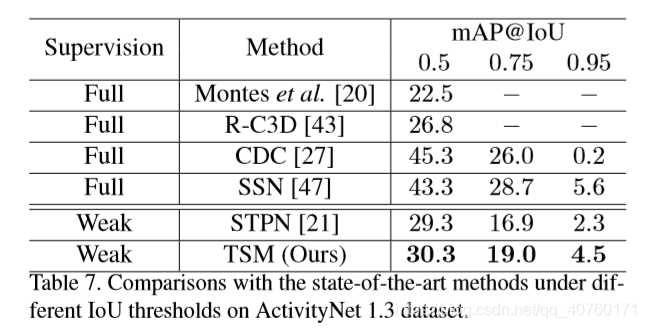
消融实验和比较结果
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









