









所有的研究由我的独断和偏见选出,单位仅标注第一单位和通讯单位;本篇为 11.25~12.2 期间我感兴趣的研究摘要;取名创意来自「科技爱好者周刊」
目录
- LLM 在预测神经科学结果方面超越了人类专家(benchmark)
- 上下文特征提取层次结构在大语言模型和大脑中收敛(iEEG研究)
- 心理学中生成式 AI 的应用(综述)
- OPM-MEG 定位运动活动区(3T-fMRI 和 OPM-MEG)
- 意见同步下的间接互惠(行为实验)
- 道德关联图:自动道德推理的认知模型(词语联想网络)
- 答案彼此趋同的个体往往有更准确的答案并且更有能力(行为实验)
- 小学高年级和初中:合作与平等规范理解发展的关键期 (行为实验)
- 人们根据他人的努力意愿来奖励他们(行为实验)
- 大脑自动修正语法错误的时空动态(MEG实验)
- 缓慢的抚摸会引起愉快的感觉(电生理信号)
- 非自愿想象的个体差异(EEG研究)
- 盲视患者检测彩色物体(观察)
- 自然音乐聆听过程中人类听觉皮层的多流预测(MEG与iEEG研究)
- 主观体验的内省心理物理学(综述)
- 对丹尼特意识观的解读(哲学解读)
- 自我耗竭理论与研究(综述)
- 有意人格改变(综述)
- 事件的整体遗忘和物体的碎片化遗忘(行为研究)
- 流畅性和预测加工(综述)
- 人脑中的两个“什么”网络(神经网络)
- 计算认知神经科学(综述)
- 测谎与指尖温度测量
- 大脑间表征转移(算法)
- 动机和决策的神经和计算机制(特刊介绍)
AI+神经科学与心理学
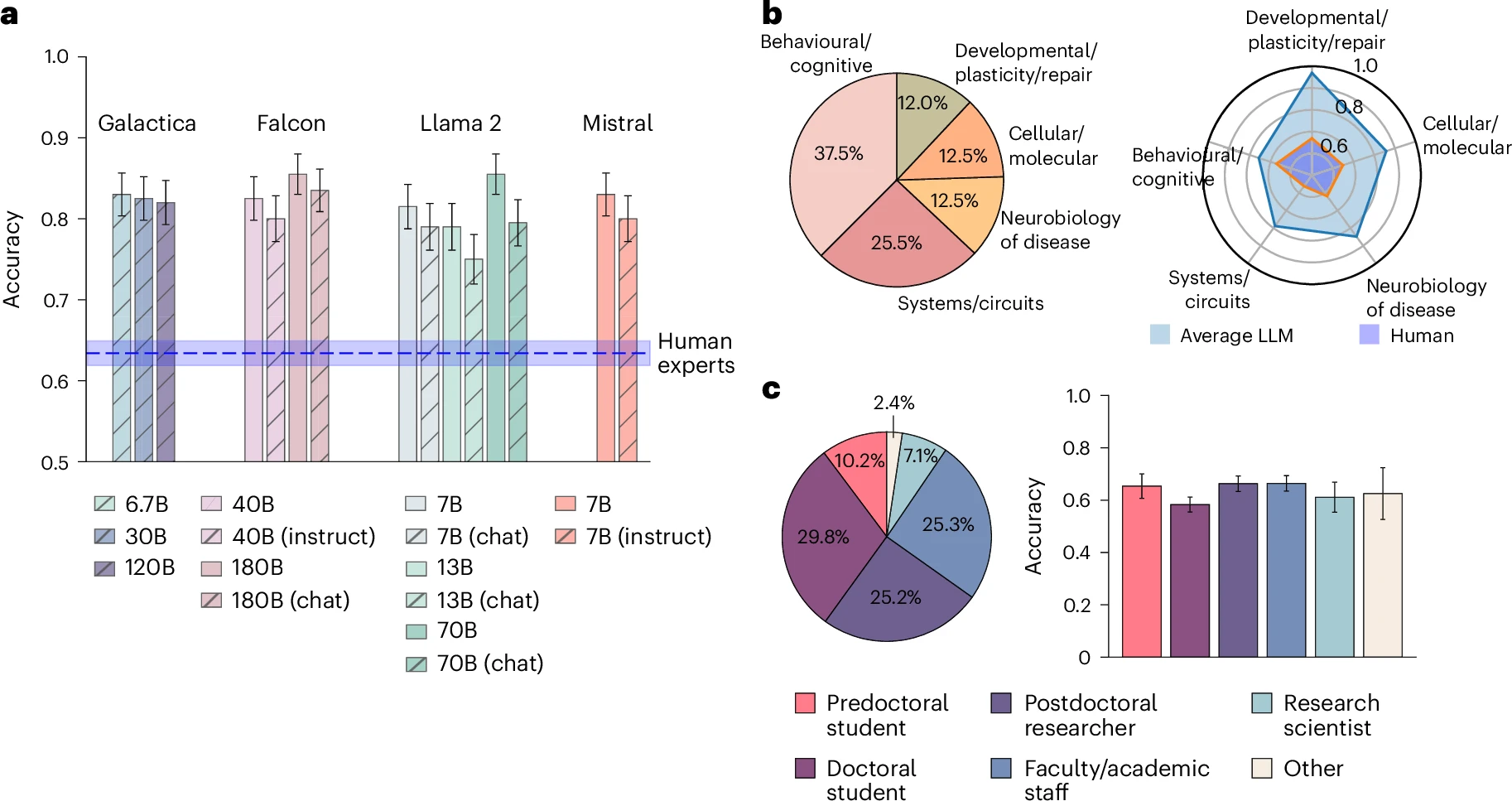
1 大型语言模型在预测神经科学结果方面超越了人类专家(nature human behaviour)
单位:UCL
链接:https://www.nature.com/articles/s41562-024-02046-9
摘要:科学发现往往取决于几十年研究的综合,这一任务可能超过人类的信息处理能力。大型语言模型(LLM)提供了一个解决方案。在大量科学文献中接受训练的 LLM 有可能整合嘈杂但相互关联的发现,比人类专家更好地预测新结果。为了评估这种可能性,本文创建了 BrainBench,这是一个预测神经科学结果的前瞻性基准。结果发现 LLM 在预测实验结果方面超过了专家。作者根据神经科学文献微调的 BrainGPT LLM 表现更好。像人类专家一样,当 LLM 对他们的预测表征高度自信时,他们的反应更有可能是正确的,这预示着 LLM 帮助人类进行发现的未来。本文方法不是神经科学特有的,可以转移到其他知识密集型工作中。
2 上下文特征提取层次结构在大型语言模型和大脑中收敛(nature machine intelligence)
单位:哥伦比亚大学电气工程系
链接:https://www.nature.com/articles/s42256-024-00925-4
预印本链接:https://arxiv.org/abs/2401.17671
摘要:人工智能的最新进展引发了人们对大型语言模型 (LLM) 和人类神经加工之间相似之处的兴趣,尤其是在语言理解方面。尽管先前的研究表明 LLM 表征和神经反应之间存在相似性,但推动这种融合的计算原理(尤其是随着 LLM 的发展)仍然难以捉摸。在这里,我们使用神经外科患者听语音的颅内脑电图记录来研究高性能 LLM 与大脑语言处理机制之间的对齐。我们检查了具有相似参数大小的多种 LLM,发现随着它们在基准任务上的性能提高,它们不仅变得更像大脑,反映在模型嵌入的更好的神经反应预测中,而且它们也更紧密地与大脑的分层特征提取路径保持一致,为相同的编码使用更少的层。此外,我们确定了高性能 LLM 的分层处理机制的共性,揭示了它们向相似语言处理策略的趋同。最后,我们展示了上下文信息在 LLM 性能和大脑对齐中的关键作用。这些发现揭示了大脑和 LLM 中语言处理的融合方面,为开发更符合人类认知处理的模型提供了新的方向。

3 心理学中生成式 AI 的革命:行为、意识和道德的交织(Acta Psychologica)
单位:东南大学经济与管理学院
链接:https://www.sciencedirect.com/science/article/pii/S0001691824004712
摘要:近年来,由于生成式人工智能 (AI) 在自然语言处理中的迅速发展,其在心理学研究中的前景无与伦比,以 ChatGPT 为代表。这篇评论文章探讨了生成式人工智能在心理学中的用途和影响。作者采用了系统的选择过程,包括 2015 年至 2024 年间从 Google Scholar、PubMed 和 IEEE Xplore 等数据库中发表的论文,使用“心理学中的生成式 AI”、“ChatGPT 和行为建模”和“心理健康中的 AI”等关键词。首先,本文回顾了生成式 AI 的基本思想,并列出了它在数据分析、行为建模和社交互动模拟中的用途。添加了一个详细的比较表,以对比心理学研究中的传统研究方法和基于 GenAI 的方法。接下来,分析生成式 AI 为心理学研究带来的理论和伦理问题,强调了开发一个连贯的理论框架是多么重要。这项研究通过将传统研究方法与 AI 驱动的方法进行对比,说明了生成式 AI 在处理大量数据和提高研究效率方面的优势。关于特定用途,该研究探讨了如何使用生成式 AI 来模拟社交互动、分析大量文本和了解认知过程。第 5 节已扩展为包括关于政治偏见、地理偏见和其他偏见的讨论。总之,本文展望了生成式人工智能在心理学研究中的未来发展,并提出了改进它的技术。本文提供了检索增强生成(RAG) 方法和人机回环系统等方法解决方案,以及开源本地 LLM 等数据隐私解决方案。总之,生成式 AI 有可能彻底改变心理学研究,但为了维护该领域的道德和科学完整性,在应用该技术之前必须仔细考虑伦理和理论问题。
方法
4 OPM-MEG 在人体中首次用于定位运动活动区域:与功能性 MRI 相比(NeuroImage)
单位:首都医科大学附属北京天坛医院神经外科
链接:https://www.sciencedirect.com/science/article/pii/S1053811924004506
背景:准确定位大脑运动区域对于在神经外科手术中保护运动功能至关重要。基于光泵磁力计 (OPM) 的脑磁图 (MEG) 提高了 MEG 在临床应用中的可用性。本研究的目的是评估“OPM-MEG”在定位脑肿瘤患者和健康个体运动区域方面的可用性、准确性和精密度。
方法:参与者被纳入并通过 3T-fMRI 和 128 通道 OPM-MEG 检查进行原发性运动区域定位。比较了两种方法的定位精度 (在解剖位置上的映射能力) 和精度 (激活信号集中化),并在神经导航系统的帮助下通过术中直接皮层电刺激 (DCS) 对局部区域进一步验证了准确性。
结果:共有 12 名参与者 (7 名脑肿瘤患者和 5 名健康个体) 入组,两种方法均成功定位运动区域。每个肢体功能的 OPM-MEG 检查平均时间约为 9 分钟。两种方法的定位主要覆盖初级运动皮层的解剖位置,并且部分重叠。OPM-MEG 识别的运动激活信号比 fMRI 更集中。OPM-MEG 定位的运动区质心在 fMRI 上偏离,手或脚定位的中位距离分别为 19.7 mm 和 27.48 mm。此外,用于手部运动的 OPM-MEG 质心成功触发了 DCS 的相应手部响应。
结论:在这项探索 OPM-MEG 在运动区域功能定位中潜力的首次人体研究中,我们揭示了它在绘制运动区域方面的可用性和可靠性,证明它是辅助神经外科实践和神经科学研究的有前途的工具。
社会认知
5 意见同步下的间接互惠(PNAS)
单位:日本 RIKEN 计算科学中心
链接:https://www.pnas.org/doi/abs/10.1073/pnas.2418364121
摘要:间接互惠是人类之间合作规模非凡的关键解释。这些文献表明,人类合作的很大一部分是由社会规范和个人维护良好声誉的激励驱动的。这种直觉已经通过两种类型的模型正式化。在公共评估模型中,假设所有社区成员都同意彼此的声誉;在私人评估模型中,人们可能会有分歧。这两种类型的模型都旨在理解社会规范与合作之间的相互作用。然而,它们的结果可能大不相同。公共评估模型认为,合作很容易发展,最有效的规范往往是严厉的。私人评估模型经常发现合作不稳定,而成功的规范显示出一些宽容。在这里,我们提出了一个模型,可以在一个框架内组织这些不同的结果。我们表明,合作的稳定性取决于一个量:个人意见的关联程度。这种相关性是由一个群体的规范和社会互动的结构决定的。特别是,我们证明了当个人观点在统计上是独立的时,没有合作规范在进化上是稳定的。这些结果对我们理解合作、从众和两极分化具有重要意义。
6 道德关联图:自动道德推理的认知模型(topics in cognitive science)
单位:多伦多大学计算机科学系
链接:https://onlinelibrary.wiley.com/doi/10.1111/tops.12774
摘要:自动道德推理是人工智能中一个至关重要的新兴话题。现代方法通常依赖于语言模型来推断概念的道德相关性或道德属性。这种方法需要复杂的参数化和昂贵的计算,并且它往往与现有的道德化心理学解释脱节。我们提出了一个简单的道德推理认知模型,道德关联图 (MAG),其灵感来自道德心理学工作。我们的模型建立在词语联想网络的基础上,以推断道德相关性,并利用了丰富的心理学数据。我们证明,当根据一组全面的数据进行评估时,MAG 的性能与最先进的语言模型相比具有竞争力,用于道德规范的自动推理和概念的道德判断,以及上下文内的道德推理。我们还表明,我们的模型产生了可解释的输出,适用于为短期道德变革提供信息。
7 群体有多聪明:我们能否仅仅因为他们彼此同意就推断出人们是准确和有能力的?(Cognition)
单位:法国国家科学研究中心
链接:https://www.sciencedirect.com/science/article/abs/pii/S0010027724002919
摘要:在某件事上达成共识的人更有可能是正确的和有能力的吗?有证据表明,人们倾向于做出这种推断。然而,标准的群体智慧方法仅提供有限的规范基础。使用模拟和分析论点,我们认为,当个体在广泛的参数下做出独立和无偏见的估计时,答案彼此趋同的个体往往有更准确的答案并且更有能力。在 6 个实验(英国参与者,总计 N = 1197)中,我们表明参与者推断同意的线人有更准确的答案并且更有能力,即使他们没有先验,并且当线人存在系统性偏见时,这些推断被削弱。总之,我们推测,从收敛到准确性和能力的推论可能有助于解释为什么人们认为科学家有能力,即使他们对科学知之甚少。
8 小学高年级和初中:合作与平等规范理解发展的关键期 (Acta Psychologica)
单位:中国人民大学心理学院
链接:https://www.sciencedirect.com/science/article/pii/S0001691824004864
摘要:各种学者讨论了群体成员身份对成人样本合作行为的影响。尽管如此,从童年中期和青春期早期开始,相关偏见的发展轨迹仍有待探索。使用一次性 4 人公共产品游戏并按学校隶属关系诱导小组成员意识,我们调查了想象伙伴的小组成员身份对第四年级(N = 106,法师 = 9.53 岁,57 名女孩)、第六年级(N = 109,法师 = 11.46 岁,54 名女孩)和八年级(N= 102,法师 = 13.22 岁,47 个女孩)。在实验 1 中,参与者是第一方玩家,与组内成员(即来自同一学校的玩家)的合作程度高于组外成员(即来自其他学校的玩家);合作期望在合作中的群体内偏爱中的中介作用仅在四年级和六年级学生中观察到。在实验 2 中,参与者是第三方执行者(即,可以惩罚组内和组外的搭便车者),结果显示,四年级和六年级学生对组内违规者更宽容;八年级学生在惩罚方面没有表现出明显的偏见。这些发现描述了从童年中期到青春期早期对合作和合作规范执行的群体内偏好下降的发展模式。合作期望仅在低年级学生之间中介群体成员身份对合作的影响,表明不同年级群体之间的合作偏差是不同机制的基础。这些讨论表明,对合作和平等规范的理解是在这一时期发展起来的。
9 人们根据他人的努力意愿来奖励他们:面向未来努力(JESP)
单位:哈佛大学心理学院
链接:https://www.sciencedirect.com/sc10 ience/article/abs/pii/S0022103124001124
摘要:协作任务的个人贡献者通常会因超越他人而获得奖励——销售人员获得佣金,运动员获得绩效奖金,公司向本月最佳员工授予特殊停车位。我们如何决定何时奖励合作者,这些决定是否与他们对协作结果的责任密切相关?在实验1a和1b( N=360),我们测试了参与者如何给予奖金,使用刺激和以前用于引发责任判断的实验设计。过去的工作发现,责任判断是由人们实际贡献了多少努力和他们本可以贡献多少。相比之下,在这里我们发现参与者分配奖金是基于仅关于代理实际贡献了多少努力。在实验2a和2b( N=358),我们引入了被指示付出特定努力水平的代理;参与者仍然奖励努力,但是当代理决定付出多少努力时,他们的奖励对付出的精确努力水平更敏感。总之,这些发现表明,人们根据他们的付出努力的意愿,并指出如何将责任分配给合作者和如何激励他们的决定之间的区别。这种差异的一个可能解释是责任判断可能反映对过去合作的因果推断,而提供激励可能会激励合作者在未来继续努力。我们的工作揭示了合作背后的认知能力。
语言
10 修正语法过程中自下而上和自上而下处理的时空动态(JNeurosci)
单位:纽约大学语言学系
链接:https://www.jneurosci.org/content/44/48/e0374242024
摘要:像所有认知领域一样,语言处理也受到自上而下的知识的影响。这方面的经典证据是信号中缺少明显的错误。在句子理解中,一个例子是没有注意到词序错误,例如句子中间的转置词:「you that read wrong」。我们的大脑似乎可以修复这些错误,因为它们与我们的语法知识不相容,但是我们的大脑是如何做到这一点的呢?在内部换位的行为工作之后,我们使用快速平行视觉呈现闪现了 300 毫秒的四个单词的句子。我们将脑磁图反应与完全语法和颠倒的句子 (24 名人类参与者: 21 名女性,4 名男性) 进行了比较。左侧语言皮层从 213 毫秒开始有力地区分语法和颠倒的句子。因此,语法知识的影响在视觉词形识别之后迅速开始。在这种神经“句子优越效应”的最早阶段,内部换位在语法和反转句子之间形成模式,这表明大脑最初“注意到”了错误。然而,100 毫秒后,内部换位变得与语法句子无法区分,这表明此时大脑已经“修复”了错误。这些结果表明,在看一眼句子后,句法影响我们的神经活动的速度几乎与假设发生更高级别对象识别的速度一样快。最早的阶段涉及自下而上的输入和语法知识之间的详细比较,而不久之后,自上而下的知识可以覆盖刺激中的错误。
感觉
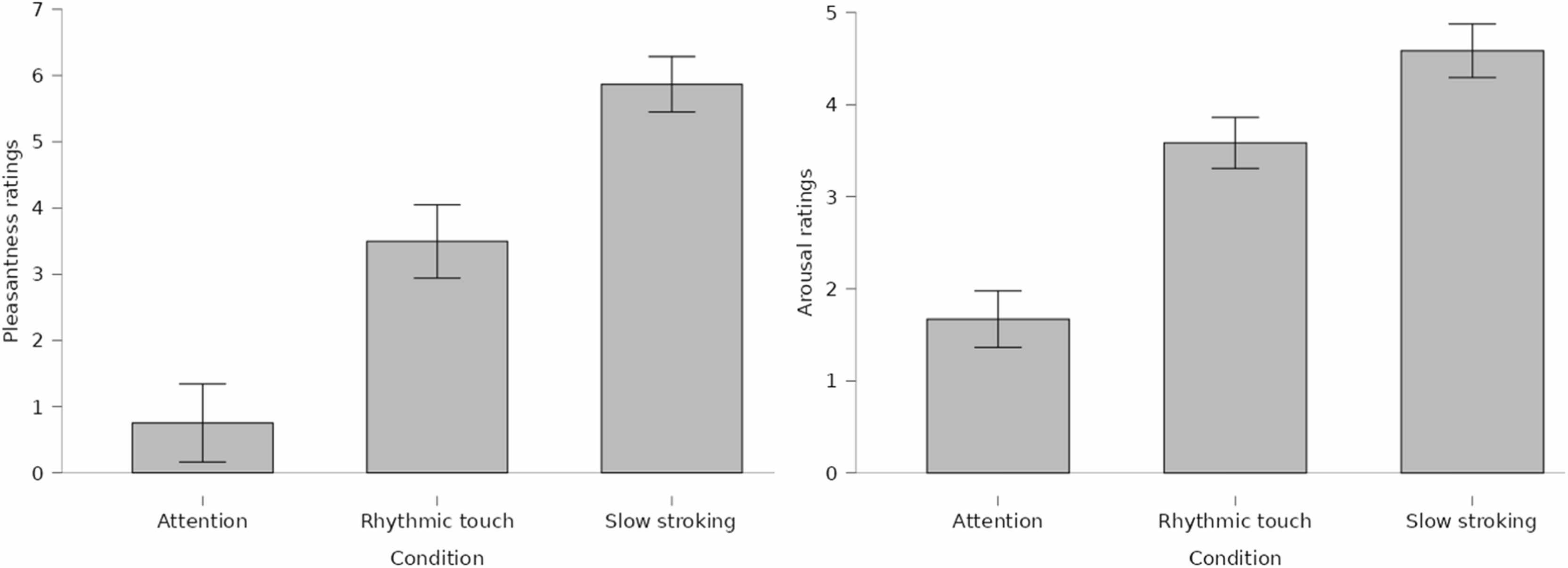
11 缓慢的抚摸会引起愉快的感觉(Biological Psychology)
单位:Károli Gáspr匈牙利归正教会大学
链接:https://www.sciencedirect.com/science/article/pii/S0301051124002175
摘要:通过轻柔缓慢地抚摸毛茸茸的皮肤来刺激 C 触觉传入神经,也称为情感触摸,可唤起愉快的感觉。我们旨在描述缓慢抚摸引起的心理和强直生理变化,以及皮肤感觉的愉悦感与生理变化与类似特征的自我报告特征(即人格的主要维度和身体意识的各个方面)之间的关联。为了更清楚地了解缓慢抚摸影响的相关因素,将抚摸 (5 cm/sec) 3 分钟与以皮肤为中心的关注和轻柔的有节奏的皮肤触摸进行了比较。85 名年轻人参加了一项实验。在刺激期间评估刺激的感觉特性 (愉悦度、强度) 和生理变化 (HR、HF、RMSSD、呼吸频率、SCL)。据报道,在缓慢抚摸的情况下,引起了最令人愉快和强烈的皮肤感觉,其次是有节奏的触摸和注意力。与基线和注意力状况相比,缓慢抚摸和有节奏的触摸显着降低了 HR,并增加了 HF 、 RMSSD、呼吸频率和 SCL。在缓慢抚摸的情况下,感觉的愉悦感在很大程度上与诱发的生理变化和评估的性状样特征无关;贝叶斯分析表明,零假设 (即缺乏关联) 在几乎所有情况下都具有优越性。虽然有节奏的触摸感觉不那么愉快和强烈,但它对心脏活动具有放松(副交感神经)作用,与缓慢抚摸的效果相当。诱发的皮肤感觉的特征与性格和身体意识的主要维度无关。
12 不要想一头粉红色的大象:视觉的个体差异可以预测不自主的意象及其神经相关性(Cortex)
单位:昆士兰大学心理学院
链接:https://www.sciencedirect.com/science/article/pii/S0010945224003083
摘要:人们在想象视觉体验的能力上存在很大差异,从终身无法想象(先天性想象缺失症)到那些报告说想象体验如同真实看到一样生动(高度想象症)。虽然先天性想象缺失症通常被认为是一种认知缺陷,但想象视觉感觉能力弱或缺失可能与对侵入性思维的抵抗力增强相平衡,侵入性思维被体验为一种想象的感觉。在这里,我们报告了对这一假设的直接测试。我们要求人们在想象或尽量不想象一系列音频和视觉体验的同时,用脑电图(EEG)记录他们的大脑活动。描述不同人自愿视觉化主观生动程度的评级可以预测他们是否也会报告有非自愿的视觉化,例如当要求他们不要想象时却出现看到粉色大象的想象体验。不同人非自愿视觉化的发生率和他们视觉化的典型生动程度都可以通过抑制解除、工作记忆和神经反馈的神经相关性来预测。我们的数据表明,人们产生非自愿视觉体验的倾向可能与他们典型视觉化体验的主观强度成正比。
13 对盲视患者意识的新观察(Cerebral Cortex)
单位:马斯特里赫特大学认知神经科学系
链接:https://academic.oup.com/cercor/advance-article/doi/10.1093/cercor/bhae456/7908435
摘要:盲视是指在没有意识地意识到刺激的情况下进行准确视觉辨别的能力。在这项研究中,作者提出了来自对双侧横纹皮层损伤患者的自然主义观察的新证据,该患者令人惊讶地展示了检测彩色物体的能力,尤其是红色物体。尽管过程缓慢而费力,但患者报告说完全了解刺激的颜色方面。这些观察结果无法用 1 型或 2 型盲视的传统概念来解释,这引发了关于客观和主观盲视之间的界限,以及视觉体验和认识能动性的性质的有趣问题。此外,这些发现强调了盲视在未来研究中可能发挥的重要作用,尤其是在了解高级皮层功能如何参与情绪和感受方面。这凸显了进一步探索以更好地了解导致情感性盲视现象的视觉特征的必要性。
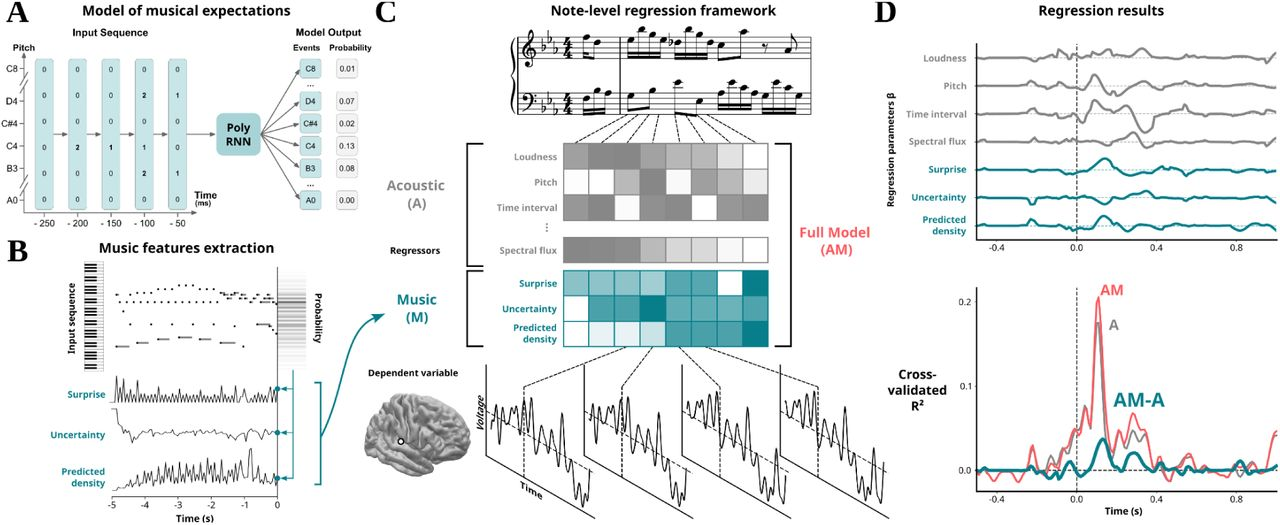
14 自然音乐聆听过程中人类听觉皮层的多流预测(biorxiv)
单位:法国艾克斯-马赛大学
链接:https://www.biorxiv.org/content/10.1101/2024.11.27.625704v1
摘要:现实世界中的感知涉及对多个动态对象和特征的并行预测与整合,但大多数研究聚焦于单一流序列。我们提出了 PolyRNN,这是一种循环神经网络,以复调音乐为例,旨在对多个同时的信息流进行预测建模。我们在参与者聆听真实钢琴音乐时,以非侵入性方式(脑磁图,MEG)和在人类大脑皮层内(颅内脑电图,EEG)记录神经生理活动。音乐预期在听觉区域以类似 P2 和 P3 的成分进行编码。与最先进的生成音乐模型相比,我们证明了并行化比序列化更能反映大脑对同时发生的序列的处理方式。总体而言,我们的方法能够对生态有效的复调音乐中的预测处理进行研究,并为同时发生的信息流中的预测建模提供了一个通用框架。
意识与自我意识
15 用于研究主观体验的内省心理物理学(Cerebral Cortex)
作者:Megan A K Peters(加利福尼亚大学尔湾分校)
链接:https://academic.oup.com/cercor/advance-article-abstract/doi/10.1093/cercor/bhae455/7906053
摘要:研究主观体验是困难的。人们认为疼痛与伤害感受不同,快乐不是计算奖励信号,恐惧也不是威胁回路的激活。不幸的是,内省式的自我报告是获取主观体验的最佳方式,但很多人仍认为内省是“不可靠”和“不可验证”的。那么内省的哪些缺点是最致命的呢?是内省对大脑过程(如感知、记忆)的访问不完美吗?是主观体验无法客观验证吗?还是很难与非主观加工能力区分开?在这里,作者认为这些都不能阻止建立一个有意义、有影响力的心理物理学研究计划,该计划通过精确描述环境变量、大脑过程、行为和自我报告的现象学之间的关系,将主观体验视为有效的实证目标。继彼得斯等人近期的类似呼吁之后,「内省心理物理学」将内省的明显缺点视为特征而非缺陷,就像 150 多年前将环境与行为联系起来的噪音和扭曲激发了费希纳的心理物理学一样。下一代心理物理学将为在多个维度(如紧迫性、情感、清晰度、生动性、信心等)上建立和测试现象学的精确解释模型提供强大工具。
16 对丹尼特意识观的解读(Philosophical Psychology)
作者:Henry Taylor(伯明翰大学)
链接:https://www.tandfonline.com/doi/full/10.1080/09515089.2024.2433526
摘要:丹尼特的工作对意识的哲学和科学理解产生了深远的影响。然而,解释丹尼特关于意识的工作是出了名的具有挑战性。有些人甚至认为他的想法是自相矛盾的。本文发展并捍卫了对 Dennett 观点的解释,其中意识是一种真实的模式。我认为,这种解释可以理解该观点的一些最初令人费解的特征,包括:多重草稿、全局工作空间理论、感受质消除主义、意识作为用户幻觉,以及声称我们关于意识的报告具有一种特殊的权威。对丹尼特的这种解释远非一堆相互矛盾的想法,而是一个一致而强大的意识体验理论。
17 自我控制与意志力有限:自我耗竭理论与研究的现状(Current Opinion in Psychology)
单位:不来梅建筑大学
链接:https://www.sciencedirect.com/science/article/pii/S2352250X24000952
摘要:自我损耗理论提出,自我调节依赖于有限的能量资源(意志力)。最初的简单理论已得到完善,强调的是能量的保存而非资源耗尽,并扩展到包括决策、规划和主动性等方面,且与身体的物理能量(葡萄糖)相关联。最近的质疑提出了替代解释(但在很大程度上未成功)并质疑了该理论的可重复性(现在已被充分证实)。研究方法得到了改进,尤其强调使用更长、更强的操作以确保产生疲劳感。新的研究将自我损耗扩展到工作场所和体育领域。人际冲突可能既是自我损耗的主要原因也是其后果。新的问题包括长期自我损耗的可能性(例如在职业倦怠中)、保护因素和应对策略、个体差异以及恢复过程。
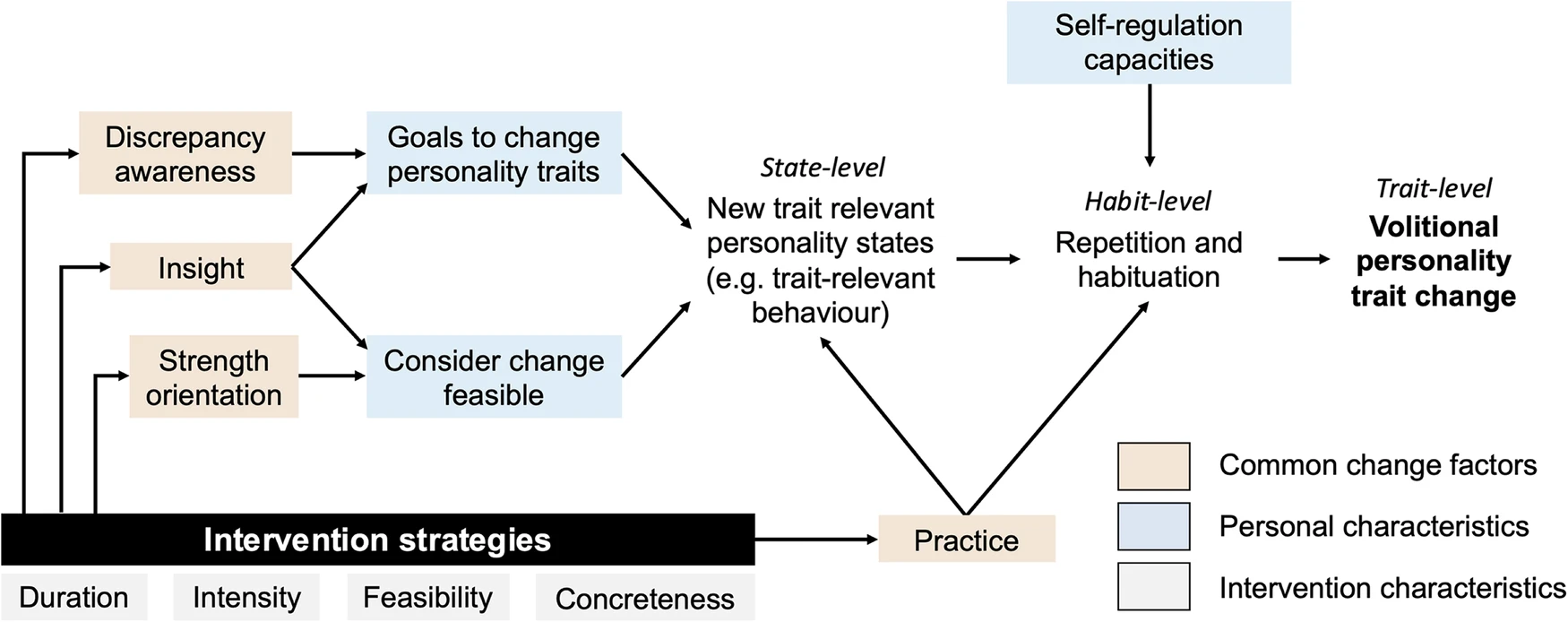
18 有意人格改变研究的系统评价(communications psychology)
单位:苏黎世大学心理学系
链接:https://www.nature.com/articles/s44271-024-00167-5
摘要:人格特质可以预测包括关系成功、教育成就和健康等广泛的生活结果。由于很多人都有改变自己人格某些方面的愿望,所以有意人格改变(VPC),即朝着个人改变目标的自我导向特质改变,最近受到越来越多的关注。这项预先注册的综述旨在对新兴的 VPC 文献(https://osf.io/ns79m)进行综合概述。基于在 PsycINFO 上的系统文献搜索(2024 年 10 月 1 日),确定了 30 项关于 VPC 的实证纵向研究(N = 7719)。通过叙述性整合以及使用元分析工具总结了这些研究的结果,并区分了 VPC 文献中的两个研究方向:不进行干预的 VPC 研究和干预诱导的 VPC 研究。仅仅有改变人格的目标与实际的人格改变只有微弱的关系。然而,VPC 干预在促进期望的人格改变方面是成功的(d = 0.22,95%置信区间=[0.005,0.433],7 项研究,26 个效应量)。这些人格改变在随访期间似乎持续甚至增加(d = 0.37,95%置信区间=[0.140,0.591],4 项研究,17 个效应量),并且与其他变量如幸福感的变化相关。尽管目前关于 VPC 的证据仍然有限,但 VPC 的初步结果是有希望的。未来的研究需要就 VPC 的普遍性、机制和实际意义得出明确的结论。作者进行这项综述没有获得基金资助。
记忆
19 事件的整体遗忘和物体(有时)的碎片化遗忘(cognition)
单位:英国约克大学心理学系
链接:https://www.sciencedirect.com/science/article/pii/S0010027724003032
摘要:情景事件通常是作为一个整体被提取和遗忘的。如果你回忆起其中一个要素(比如一个人),那么你就更有可能回忆起同一事件中的其他要素(比如地点),即便在存在遗忘现象的情况下,这种模式也会随着时间的推移而保留下来。相比之下,单个物品(如物体)的表征可能结合得没那么紧密,以至于物体的各种特征会以不同的速度被遗忘,而且随着时间间隔的拉长,提取的关联性也会降低。 为了验证在表征层次结构的不同层面上遗忘在性质上存在差异这一理论预测,我们通过五个实验对事件记忆和物品记忆之间可能存在的分离现象进行了研究。参与者对由名人照片、地点和物体组成的三要素事件进行编码。我们在编码完成后即刻以及经过不同的时间间隔(5小时到3天)后,测量了提取的准确性以及事件关联提取和物体特征提取之间的关联性。 在各个实验中,随着时间的推移,事件和物体的提取准确性都有所下降,这表明存在遗忘现象。事件要素(即人物、地点和物体)的提取关联性并没有随着时间而改变,这表明事件是作为一个整体被遗忘的。而物体特征(即状态和颜色)的提取关联性则变化较大。根据各个实验中的编码和时间间隔条件,我们观察到物体特征既有碎片化遗忘的情况,也有整体遗忘的情况。 我们的研究结果表明,事件表征随着时间的推移仍能保持连贯性,而物体表征有可能但并非总是会出现碎片化的情况。这为我们的遗忘表征层次结构框架提供了支持,不过,关于物体表征碎片化的边界条件(仍有待确定)。
预测加工
20 处理流畅性和预测处理:预测性思维如何意识到其认知局限性(topics in cognitive science)
单位:格勒诺布尔阿尔卑斯大学
链接:https://onlinelibrary.wiley.com/doi/10.1111/tops.12776
摘要:预测加工是理解人类和动物认知的有影响力的理论框架。在预测处理的上下文中,学习通常被简化为优化具有预定义结构的生成模型的参数。这称为贝叶斯参数学习。然而,要提供对学习的全面描述,还必须解释大脑如何学习其生成模型的结构。第二种学习被称为结构学习。结构学习将涉及生成模型中的真正结构变化。本文的目的是描述这些结构变化上游涉及的过程。为此,我们首先强调预测处理和加工流畅性理论之间的显着兼容性。更准确地说,我们认为预测处理能够解释与处理流畅性概念相关的所有主要理论结构(即流畅性启发式、朴素理论、差异归因假设、绝对流利度、预期流利度和相对流利度)。然后,我们使用这种对加工流畅性的预测处理解释来展示大脑如何推断它是否需要结构变化来学习环境中起作用的因果规律。最后,我们推测这种推论如何在必要时间接触发结构变化。
一般大脑/Mind特征
21 人脑中的两个“什么”网络(Journal of Cognitive Neuroscience)
单位:Maryam Vaziri-Pashkam(特拉华大学)
链接:https://direct.mit.edu/jocn/article-abstract/36/12/2584/123924/Two-What-Networks-in-the-Human-Brain
摘要:Ungerleider 和 Mishkin 在他们有影响力的工作中,依赖于详细的解剖学和消融研究,他们认为视觉信息是沿着两条不同的途径处理的:背侧 “where” 通路,主要负责空间视觉,以及腹侧 “what” 通路,专门用于物体视觉。鉴于令人信服的证据表明,在假定的 “where” 途径中具有强大的形状和对象选择性,这种严格的分工面临着挑战。本文回顾了支持背侧通路中存在形状选择性的证据。从不变性、任务依赖性和表征内容方面对背侧和腹侧物体表征的比较检查揭示了两种途径之间的相似性和差异性。两者都对图像转换表现出一定程度的耐受性并受任务影响,但与腹侧通路中的反应相比,背侧通路的反应表现出更弱的耐受性和更强的任务调节。此外,对它们的表征内容的检查突出了两种途径中反应之间的差异,表明它们对物体的不同特征很敏感。总的来说,这些发现表明,人脑中存在两个网络来处理物体的形状,一个在背侧,另一个在腹侧视觉皮层。这些研究为未来的研究奠定了基础,旨在揭示两个“什么”网络在我们理解物体和与物体互动的能力中所起的确切作用。
其他
22 计算视角:认知神经科学研究问题的催化剂?(Neuroscience & Biobehavioral Reviews)
单位:Macromedia应用科技大学
链接:https://www.sciencedirect.com/science/article/abs/pii/S0149763424004354
摘要:新颖的研究问题从何而来?我们建议识别关键计算问题并比较跨领域的解决方案可以是一个来源。我们通过观察感知和行动来举例说明这一点,并概述了一个领域的发现如何在另一个领域产生新的研究途径。
23 谎言并不让人寒冷:评估测谎的直接、间接和生理测量 (Acta Psychologica)
单位: 荷兰蒂尔堡大学
链接:https://www.sciencedirect.com/science/article/pii/S0001691824004268
摘要:人们往往不善于发现谎言:当明确要求推断别人说的是谎还是真时,人们的表现往往不会比偶然好。然而,越来越多的证据表明,隐含的测谎措施和潜在的生理措施可能反映了观察者对谎言和真相的区分。内隐和生理反应被认为对谎言的反应是与威胁反应相关的威胁刺激。因此,说谎的人应该比说真话的人更受喜欢和信任(间接测谎措施)。在生理学方面,威胁反应应与血管狭窄(血管收缩)有关,这应该会减少外周皮肤血流量。因此,与事实相比,我们预计面对谎言时的手指温度会更低。我们使用显式和间接措施以及使用红外热成像作为测谎的生理测量来测试测谎。参与者 (N = 95) 观察了人们说谎或关于他们社会关系的真相的视频,在此期间记录了参与者的指尖温度。结果表明,显式分类的准确性保持在偶然水平。对讲故事的人的好感度和可信度(测谎的间接衡量标准)的判断表明,没有证据表明观察者可以区分说谎者和说真话的人:那些被认为是说真话的人比那些被认为是说谎的人更受喜欢和信任,即使这种信念是错误的。使用热成像测量的生理谎言检测也失败了:观察者的指尖温度在谎言和真实故事之间没有显着差异。如果有的话,温度效应指向了与谎言即威胁预期相反的方向:与真实故事相比,面对谎言时,指尖温度会有所升高。结果支持人们不善于检测谎言的印象,并对指尖温度反应是否可以用作测谎机制产生怀疑。
24 将表征从一个大脑转移到另一个大脑的无监督方法(Front. Neuroinform.)
单位:日本茨城县产业技术综合研究所人类信息学与交互研究所
链接:https://www.frontiersin.org/journals/neuroinformatics/articles/10.3389/fninf.2024.1470845/full
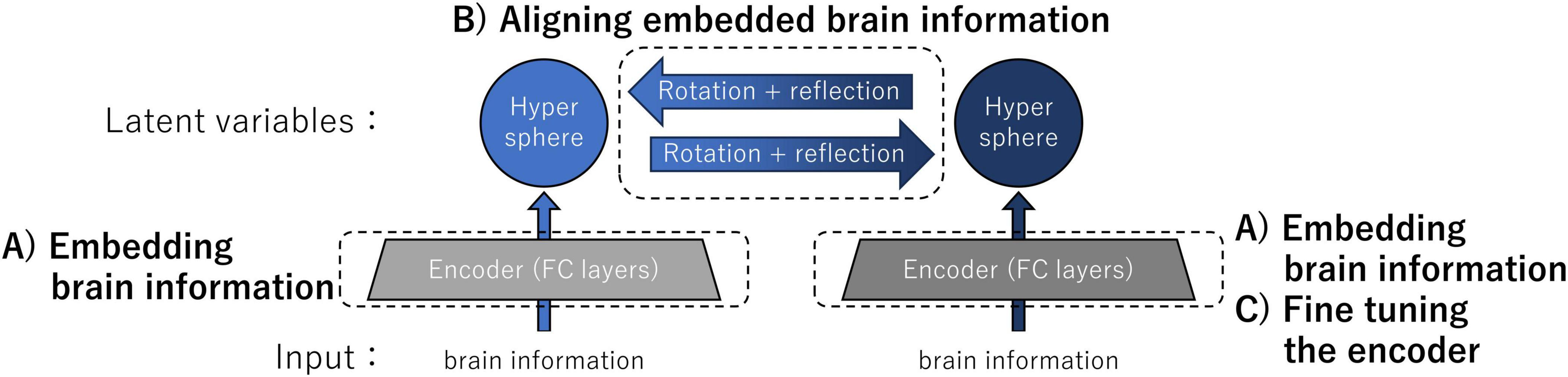
摘要:尽管大脑区域的解剖排列及其内部的功能结构在个体之间相似,但由于各种因素,神经信息的表示(例如记录的大脑活动)因个体而异。因此,在使用使用他人数据训练的模型解码神经信息或实现脑对脑通信时,大脑信息的适当转换和翻译至关重要。我们提出了一种大脑表征转移方法,该方法涉及将从一个人的大脑获得的数据表征转换为从另一个人的大脑获得的数据表征,而无需依赖传输数据集之间相应的标签信息。我们定义了实现这种大脑表征转移的要求,并开发了一种算法,该算法使用编码器进行非线性降维,将跨大脑数据集的共同相似性结构的假设提炼为跨低维超球体的旋转和反射变换。我们首先使用来自人工神经网络的数据作为替代神经活动并检查各种实验因素来验证我们提出的方法。然后,我们使用从人类参与者那里获得的功能性磁共振成像反应数据评估了我们的方法对真实大脑活动的适用性。这些验证实验的结果表明,我们的方法成功地执行了表示转移,并在某些情况下实现了与使用相应标签信息时获得的转换相似的转换。此外,我们通过执行大脑表征迁移,无需训练个性化解码器,即可从个人数据中重建图像。结果表明,我们的无监督转移方法对于重新应用针对特定参与者和数据集的个性化现有模型以解码来自其他个体的大脑信息很有用。我们的发现还可以作为该方法的概念验证,使代表个体感觉的神经信息的潜在特性的交换成为可能。
25 动机和决策的神经和计算机制(Journal of Cognitive Neuroscience)
单位:Debbie M. Yee(布朗大学)
摘要:动机通常被认为通过使行动偏向于奖励而不是惩罚来增强适应性决策。然而,新出现的证据指向一个更微妙的观点,即动机既可以增强也可以损害决策的不同方面。在过去十年中,基于模型的方法因为激励措施如何影响目标导向行为开发更精确的机制解释而获得突出地位。在本特别关注中,我们重点介绍了三项研究,这些研究展示了计算框架如何帮助将决策过程分解为构成认知成分,并正式确定激励因素(例如金钱奖励)何时以及如何影响特定的认知过程、决策策略和自我报告措施。最后,我根据该领域的最新进展提出了一个挑衅性的建议:生物体不仅仅寻求最大化外在激励的预期价值。相反,他们可能正在优化决策以达到所需的内部状态(例如,体内平衡、努力、情感)。未来对此类内部过程的研究将是解锁动机决策的认知、计算和神经机制的有益努力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









