






安装分布式的Spark集群的环境
Spark分布式集群的安装环境,需要事先配置好Hadoop的分布式集群环境,如果没有配置好Hadoop的分布式集群环境,请点击西北工业大学软件学院大数据技术试验(二)进行安装,本文采用Spark2.4.0来搭建集群。
1.安装Spark
这里采用5台机器(节点)作为实例来演示如何搭建Spark集群,其中一台机器作为master节点,另外4台机器作为slave节点,主机名一次命名为slave01,slave02.......。我们需要在master主机上,访问Spark官方下载地址来获取最新的3.X版本的Spark,或者采用作者在网盘中分享的2.4.0版本的Spark安装包来进行安装。若从官方下载的话需要看一下Spark3.X版本的需要提前准备的Hadoop版本是多少,可能Hadoop2.7.x已经满足不了高版本的Spark需求了,按下图所指示的下载即可。

待我们获取到Spark的安装包时,执行如下的命令:
sudo tar -zxf ~/下载/spark-2.4.0-bin-without-hadoop.tgz -C /usr/local/ #解压到指定的文件夹
cd /usr/local
sudo mv ./spark-2.4.0-bin-without-hadoop/ ./spark #更改文件夹的名字
sudo chown -R hadoop ./spark #更改文件的所属用户并在主节点master主机执行如下命令:
vim ~/.bashrc
在其中添加如下的配置:
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin执行source ~/.bashrc来使得配置立马生效。
2.Spark的配置
(1)配置slaves文件。首先将slaves.template拷贝到slaves,执行如下的命令:
cd /usr/local/spark/
cp ./conf/slaves.template ./conf/slaves编辑slaves的内容,将默认的localhost替换成如下内容:
slave01 #在/etc/hosts文件里面已经有了IP 名称对应的信息
slave02
slave03
slave04(2)配置spark-env.sh文件。将spark-env.sh.template拷贝到spark-env.sh,执行如下命令:
cp ./conf/spark-env.sh.template ./conf/spark-env.sh编辑spark-env.sh,并添加如下的内容:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=10.13.0.33 #这是你的master的IP地址(3)将master主机上的spark文件分配到若干个节点上,在master主机上执行如下命令 :
cd /usr/local/
tar -zcf ~/spark.master.tar.gz ./spark
cd ~
scp ./spark.master.tar.gz slave01:/home/hadoop # :后面指的是指定主机的文件路径
scp ./spark.master.tar.gz slave02:/home/hadoop(4)我们进入到子节点slave主机上,分别执行如下的步骤:
sudo rm -rf /usr/local/spark/
sudo tar -zxf ~/spark.master.tar.gz -C /usr/local
sudo chown -R hadoop /usr/local/spark这时,我们有关spark集群的配置到此就结束了。
3.启动Spark集群
(1)启动Hadoop集群
在启动Spark集群前,我们应该先启动Hadoop集群。在master主机节点上运行如下命令:
cd /usr/local/hadoop/
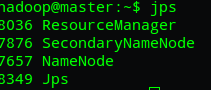
sbin/start-all.sh在master主节点上运行jps的命令,我们可以看见如下进程。如果少了哪些的话建议先看一下问题所在再进行下面的步骤:

(2)启动Spark集群 :启动master节点,在master主机上执行如下命令:
cd /usr/local/spark/
sbin/start-master.sh此时我们可以在master节点上运行jps命令,可以看到了多了Master进程:

若出现了JAVA_HOME is not set的错误,请别惊慌,首先关闭Spark集群,修改位于 /usr/local/spark/sbin/下面的spark-config.sh,并添加JDK的安装目录即可。
(3)启动Spark集群:启动所有的slave节点,在master主机上执行如下命令:
sbin/start-slaves.sh此时我们可以在若干个slave节点上运行jps命令,可以看见了多了个Worker进程:

(4)在浏览器中观察Spark独立集群管理器的信息:在master主机上打开浏览器,访问http://master:8080地址,会观察到下图:

4.在Spark集群上运行一个程序 (Scala版本的)
(1)启动Spark-Shell(编写交互式的Scala程序),执行如下命令:
cd /usr/local/spark
bin/spark-shell下面展示的是在交互式的shell中来进行一些列操作的结果图(涉及到了一些简单的RDD编程):

但是这样一行一行的输入命令总归有点麻烦,我们需要运行整个程序,这样的话我们就需要将整个scala程序打包,封装成jar包来提交给spark来执行。具体执行方法如下一小节:
(2)使用sbt打包工具来打包独立的应用程序
1.构建scala项目的目录
cd ~ # 进入用户主文件夹
mkdir ./sparkapp # 创建应用程序根目录
mkdir -p ./sparkapp/src/main/scala # 创建所需的文件夹结构在 ./sparkapp/src/main/scala 下建立一个名为 SimpleApp.scala 的文件(vim ./sparkapp/src/main/scala/SimpleApp.scala),添加代码如下:
/* SimpleApp.scala */
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object SimpleApp {
def main(args: Array[String]) {
val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system
val conf = new SparkConf().setAppName("Simple Application")
val sc = new SparkContext(conf)
val logData = sc.textFile(logFile, 2).cache()
val numAs = logData.filter(line => line.contains("a")).count()
val numBs = logData.filter(line => line.contains("b")).count()
println("Lines with a: %s, Lines with b: %s".format(numAs, numBs))
}
}该程序计算 /usr/local/spark/README 文件中包含 “a” 的行数 和包含 “b” 的行数。代码第logFile行的 /usr/local/spark 为 Spark 的安装目录,如果不是该目录请自行修改。不同于 Spark shell,独立应用程序需要通过val sc=new SparkContext(conf) 初始化 SparkContext,SparkContext 的参数 SparkConf 包含了应用程序的信息。至此一个完整的scala项目的目录就已经准备好了。
2.安装SBT打包程序
大家可以去我分享的百度网盘中找到一个名为sbt-1.3.8.tgz的文件下载到master节点上,并执行如下命令:
cd /usr/local
tar -zxvf ~/下载/sbt-1.3.8.tgz /usr/local/ #解压到/usr/local/目录下面并且修改名字为sbt
将SBT打包程序的安装路径添加到.bashrc文件中,执行如下命令:
vim ~/.bashrc
#####添加如下内容
export SBT_HOME=/usr/local/sbt
export PATH=${SBT_HOME}/bin:$PATH
source ~/.bashrc这样一来 ,SBT打包程序就被我们顺利安装了。
3.打包Scala项目
进入先前创建的sparkapp目录中,在根目录下创建一个名为simple.sbt的脚本文件,里面写上了该项目所需要的依赖环境,如下所示:
cd ~/sparkapp
vim simple.sbt
#########添加如下的内容
name := "xxx" #显示的是你打成jar包的名字
version := "1.0" #你这个项目的版本号
scalaVersion := "2.11.12" #这个看一下你启动的spark-shell环境中的scala版本号
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.0" #基本的依赖
libraryDependencies += "org.apache.spark" %% "spark-graphx" % "2.4.0" #如果需要运行spark生态中的graphx或者sparkstreaming时需要另外添加的依赖关系
之后执行find .命令来查看项目目录(如果不是如下展示的目录结构需要修改一下) :
cd ~/sparkapp
find .
######展示如下的内容
.
./src
./src/main
./src/main/scala
./src/main/scala/SimpleApp.scala
./simple.sbt执行如下命令来打包整个项目:
cd ~/sparkapp
sbt package以上命令会执行很久,好像得从网上重新下载所需要的依赖,我们 只需要静静等待即可,如果出现错误的话可以根据错误信息来确定时依赖的问题还是在编译时出现的代码问题来具体解决。如果显示打包成功的话,可以在~/sparkapp/target/scala-2.11/xxxx.jar找到对应的jar包,这样我们就可以将jar包提交给spark环境来运行独立的程序了。最后打包后的项目目录如下所示:

如果打包过程中出现失败的话,我们只需要删除project目录和target目录,然后修改错误重新打包即可。
4.将jar包提交给spark集群来运行,执行如下命令:
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar
#其中class后面跟的"xxxxx"指的是simpleapp.scala程序中的主类,即object后面的名称,只是简单介绍一下,如果复杂的项目可以去网络上自行查找。
######执行结果如下
Lines with a: 58, Lines with b: 26
可以同样在master主机上的浏览器中打开http://master:8080来查看下面的spark运行程序的情况。
5.关闭 Spark集群
(1)关闭Master节点:
sbin/stop-master.sh(2)关闭Worker节点:
sbin/stop-slaves.sh(3)关闭Hadoop集群
cd /usr/local/hadoop/
sbin/stop-all.sh至此,大数据实验的两大基本环境以及相关相关软件的安装就暂时告一段落了。有同学在实验过程中遇到了不一样的问题时,欢迎各位在本文下面评论区留言,大家也可以互相讨论学习一下,我也会积极回复大家的问题的。祝愿大家在赵老师带的大数据原理与技术的课程中学到很多对自己有帮助的知识。















 444
444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









