







HPC集群部署 - spark
在前章我们花了很大篇幅介绍并搭建hadoop集群,其中一个主要原因为了搭建hadoop+spark集群
1. 介绍
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎
Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark在诞生之初属于研究性项目,其诸多核心理念均源自学术研究论文。2013年,Spark加入Apache孵化器项目后,开始获得迅猛的发展,如今已成为Apache软件基金会最重要的三大分布式计算系统开源项目之一(即Hadoop、Spark、Storm)。
Spark作为大数据计算平台的后起之秀,在2014年打破了Hadoop保持的基准排序(Sort Benchmark)纪录,使用206个节点在23分钟的时间里完成了100TB数据的排序,而Hadoop则是使用2000个节点在72分钟的时间里完成同样数据的排序。也就是说,Spark仅使用了十分之一的计算资源,获得了比Hadoop快3倍的速度。新纪录的诞生,使得Spark获得多方追捧,也表明了Spark可以作为一个更加快速、高效的大数据计算平台。
Spark具有如下几个主要特点:
- 运行速度快:Spark使用先进的DAG(Directed Acyclic Graph,有向无环图)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比Hadoop MapReduce快上百倍,基于磁盘的执行速度也能快十倍;
- 容易使用:Spark支持使用Scala、Java、Python和R语言进行编程,简洁的API设计有助于用户轻松构建并行程序,并且可以通过Spark Shell进行交互式编程;
- 通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件,这些组件可以无缝整合在同一个应用中,足以应对复杂的计算;
- 运行模式多样:Spark可运行于独立的集群模式中,或者运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
Spark源码托管在Github中,截至2016年3月,共有超过800名来自200多家不同公司的开发人员贡献了15000次代码提交,可见Spark的受欢迎程度。
此外,每年举办的全球Spark顶尖技术人员峰会Spark Summit,吸引了使用Spark的一线技术公司及专家汇聚一堂,共同探讨目前Spark在企业的落地情况及未来Spark的发展方向和挑战。Spark Summit的参会人数从2014年的不到500人暴涨到2015年的2000多人,足以反映Spark社区的旺盛人气。
Spark如今已吸引了国内外各大公司的注意,如腾讯、淘宝、百度、亚马逊等公司均不同程度地使用了Spark来构建大数据分析应用,并应用到实际的生产环境中。相信在将来,Spark会在更多的应用场景中发挥重要作用。
2. Spark VS Hadoop(MapReduce)
Hadoop虽然已成为大数据技术的事实标准,但其本身还存在诸多缺陷,最主要的缺陷是其MapReduce计算模型延迟过高,无法胜任实时、快速计算的需求,因而只适用于离线批处理的应用场景。另外,真实的商业MapReduce场景极端复杂,维护成本极高。
回顾Hadoop的工作流程,可以发现Hadoop存在如下一些缺点:
- 表达能力有限。计算都必须要转化成Map和Reduce两个操作,但这并不适合所有的情况,难以描述复杂的数据处理过程;
- 磁盘IO开销大。每次执行时都需要从磁盘读取数据,并且在计算完成后需要将中间结果写入到磁盘中,IO开销较大;
- 延迟高。一次计算可能需要分解成一系列按顺序执行的MapReduce任务,任务之间的衔接由于涉及到IO开销,会产生较高延迟。而且,在前一个任务执行完成之前,其他任务无法开始,难以胜任复杂、多阶段的计算任务。
Spark在借鉴Hadoop MapReduce优点的同时,很好地解决了MapReduce所面临的问题。相比于MapReduce,Spark主要具有如下优点:
- Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比MapReduce更灵活;
- Spark提供了内存计算,中间结果直接放到内存中,带来了更高的迭代运算效率;
- Spark基于DAG的任务调度执行机制,要优于MapReduce的迭代执行机制。
Spark最大的特点就是将计算数据、中间结果都存储在内存中,大大减少了IO开销,因而,Spark更适合于迭代运算比较多的数据挖掘与机器学习运算。使用Hadoop进行迭代计算非常耗资源,因为每次迭代都需要从磁盘中写入、读取中间数据,IO开销大。而Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据。
在实际进行开发时,使用Hadoop需要编写不少相对底层的代码,不够高效。相对而言,Spark提供了多种高层次、简洁的API,通常情况下,对于实现相同功能的应用程序,Spark的代码量要比Hadoop少2-5倍。更重要的是,Spark提供了实时交互式编程反馈,可以方便地验证、调整算法。
尽管Spark相对于Hadoop而言具有较大优势,但Spark并不能完全替代Hadoop,主要用于替代Hadoop中的MapReduce计算模型。实际上,Spark已经很好地融入了Hadoop生态圈,并成为其中的重要一员,它可以借助于YARN实现资源调度管理,借助于HDFS实现分布式存储。此外,Hadoop可以使用廉价的、异构的机器来做分布式存储与计算,但是,Spark对硬件的要求稍高一些,对内存与CPU有一定的要求。

3. Spark运行模式
部署Spark集群大体上分为两种模式:单机模式与集群模式
大多数分布式框架都支持单机模式,方便开发者调试框架的运行环境。但是在生产环境中,并不会使用单机模式。因此,后续直接按照集群模式部署Spark集群。
下面详细列举了Spark目前支持的部署模式。
-
Local模式:在本地部署单个Spark服务 -
Standalone模式:Spark自带的任务调度模式。(国内常用) -
YARN模式:Spark使用Hadoop的YARN组件进行资源与任务调度。(国内最常用) -
Mesos模式:Spark使用Mesos平台进行资源与任务的调度。(国内很少用)
3.1 YARN模式
Spark分布式集群的安装环境,需要事先配置好Hadoop的分布式集群环境。如果没有配置好Hadoop的分布式集群环境,请查看前一章Hadoop分布式集群环境搭建,根据教程进行安装。(备注:本教程采用Spark2.0搭建集群,同样适用于搭建Spark1.6.2集群)
hadoop集群各节点信息(可参考前一章):
| 主机名 | IP | 用户 | HDFS | YARN |
|---|---|---|---|---|
| node1 | 192.168.71.183 | root | NameNode、DataNode | NodeManager、ResourceManager |
| node2 | 192.168.71.253 | root | DataNode、SecondaryNameNode | NodeManager |
| node3 | - | - | DataNode | NodeManager |
1. 下载资源
[root@node1 local]# tar -zxvf /root/share/spark-3.3.2-bin-hadoop2.tgz -C /usr/local/
[root@node1 local]# ln -s spark-3.3.2-bin-hadoop2 spark
如果是指定用户执行,则还需要赋权
sudo chown -R hadoop ./spark
2. 配置环境变量
在各节点的终端中执行如下命令:
[root@node1 local]# cat ~/.bashrc
...
export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
[root@node1 local]# source ~/.bashrc
3. Spark配置
在Master节点主机上进行如下操作:
-
- 配置workers文件
将 workers.template 拷贝到 workers
- 配置workers文件
[root@node1 spark]# cp conf/workers.template conf/workers
[root@node1 spark]# cat conf/workers
#
...
# A Spark Worker will be started on each of the machines listed below.
node1
node2
-
- 修改spark-defaults.conf
[root@node1 conf]# tail spark-defaults.conf
# Example:
# spark.master spark://master:7077
# spark.eventLog.enabled true
# spark.eventLog.dir hdfs://namenode:8021/directory
# spark.serializer org.apache.spark.serializer.KryoSerializer
# spark.driver.memory 5g
# spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
spark.eventLog.enabled true
spark.eventLog.dir hdfs://node1:8020/directory
-
- 配置spark-env.sh文件
将 spark-env.sh.template 拷贝到 spark-env.sh,编辑spark-env.sh,添加如下内容:
- 配置spark-env.sh文件
[root@node1 spark]# cp conf/spark-env.sh.template conf/spark-env.sh
[root@node1 conf]# tail spark-env.sh
# You might get better performance to enable these options if using native BLAS (see SPARK-21305).
# - MKL_NUM_THREADS=1 Disable multi-threading of Intel MKL
# - OPENBLAS_NUM_THREADS=1 Disable multi-threading of OpenBLAS
export SPARK_DIST_CLASSPATH=$(/root/hadoop/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/root/hadoop/hadoop/etc/hadoop
export SPARK_MASTER_HOST=node1
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://node1:8020/directory
-Dspark.history.retainedApplications=30"
-
- 同步配置文件
配置好后,将Master主机上的/usr/local/spark文件夹复制到各个节点上。在Master主机上执行如下命令:
- 同步配置文件
[root@node1 local]# tar -zcvf ~/spark.tar.gz ./spark-3.3.2-bin-hadoop2
[root@node1 local]# scp ~/spark.tar.gz root@192.168.71.253:/home/
spark.tar.gz
节点机:
[root@node2 home]# tar -zxvf spark.tar.gz -C /usr/local/
[root@node2 home]# cd /usr/local/
[root@node2 local]# ln -s spark-3.3.2-bin-hadoop2 spark
4. 启动Spark集群
启动Spark集群前,要先启动Hadoop集群。
cd /usr/local/hadoop/
sbin/start-all.sh
启动Spark集群
- 启动Master节点
在Master节点主机上运行如下命令:
cd /usr/local/spark/
sbin/start-master.sh
在Master节点上运行jps命令,可以看到多了个Master进程:
[root@node1 spark]# jps
18448 ResourceManager
18193 DataNode
18055 NameNode
20680 Jps
3802 JobHistoryServer
18554 NodeManager
20652 Master
- 启动所有Slave节点
在Master节点主机上运行如下命令:
[root@node2 spark]# sbin/start-workers.sh
node2: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node2.253.out
[root@node2 spark]# jps
26613 NodeManager
26536 SecondaryNameNode
26427 DataNode
33645 Jps
33614 Worker
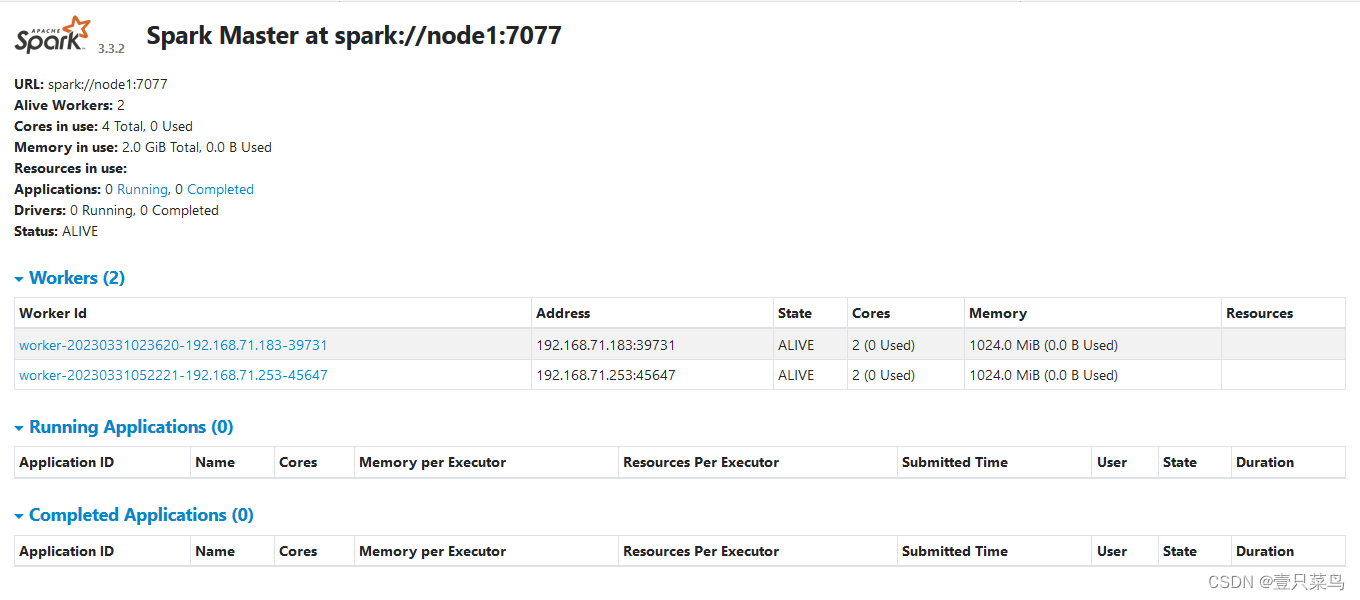
- 在浏览器上查看Spark独立集群管理器的集群信息
在master主机上打开浏览器,访问http://master:8080,如下图:
5. 测试
[root@node1 sbin]# spark-submit --class org.apache.spark.examples.SparkPi --master yarn ../examples/jars/spark-examples_2.12-3.3.2.jar 10
遇到问题
-
- 时区问题
解决:org.apache.hadoop.yarn.exceptions.YarnException: Unauthorized request to start container. ... Note: System times on machines may be out of sync. Check system time and time zones.cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime ntpdate pool.ntp.org -
- safe mode
解决:Failed to cleanup staging dir hdfs://node1:9000/user/root/.sparkStaging/application_1680244484191_0003 org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.SafeModeException): Cannot delete /user/root/.sparkStaging/application_1680244484191_0003. Name node is in safe mode.[root@node1 sbin]# hadoop dfsadmin -safemode leave DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. Safe mode is OFF
















 733
733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









