








一、感知机模型
1.感知机定义
定义(感知机):假设输入空间(特征空间)是
χ
⊆
R
n
\chi\subseteq R^n
χ⊆Rn,输出空间是
Y
=
{
+
1
,
−
1
}
Y = \{+1,-1\}
Y={+1,−1},输入
x
∈
χ
x\in\chi
x∈χ 表示实例的特征向量,对应于输入空间(特征空间)的点;输出
y
∈
Y
y\in Y
y∈Y 表示实例的类别,由输入空间到输出空间的如下函数:
f
(
x
)
=
s
i
g
n
(
ω
⋅
x
+
b
)
f(x)=sign(\omega \cdot x + b)
f(x)=sign(ω⋅x+b) 称为感知机。其中,
ω
\omega
ω 和
b
b
b 为感知机模型参数,
ω
∈
R
n
\omega \in R^n
ω∈Rn 叫做权值(weight)或权值向量(weight vector),
b
∈
R
b \in R
b∈R 叫做偏置(bias),
ω
⋅
x
\omega \cdot x
ω⋅x 表示
ω
\omega
ω 和
x
x
x 的内积,
s
i
g
n
sign
sign是符号函数,即:
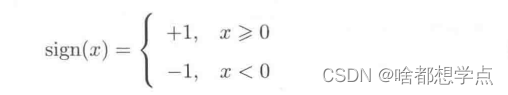
2.感知机几何解释
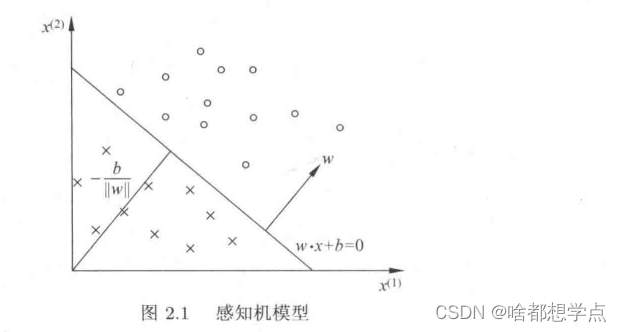
在一个数据集中,我们将正类用“o”表示,将负类用"×"表示,每个数据集我们取两个特征值
x
i
=
(
x
i
1
,
x
i
2
)
x_i=(x_i^1,x^2_i)
xi=(xi1,xi2),各点的分布如上图,横坐标为
x
1
x^1
x1,纵坐标为
x
2
x^2
x2。感知机模型就是能较好的将正负类区分的一个超平面1,具体函数为:
f
(
x
)
=
s
i
g
n
(
ω
⋅
x
+
b
)
f(x)=sign(\omega \cdot x + b)
f(x)=sign(ω⋅x+b),其中
ω
\omega
ω 是超平面的法向量,
b
b
b是超平面的截距。
当然,类似的超平面有有很多。比如
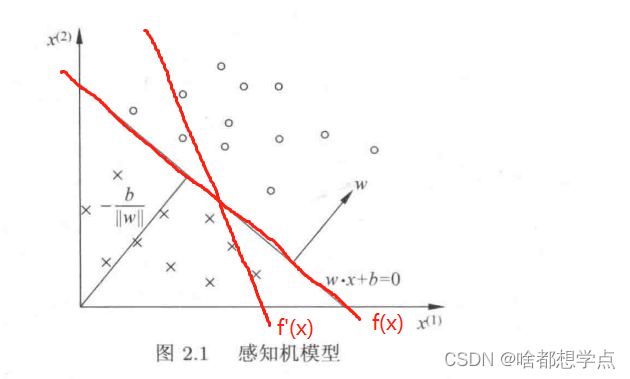
f
(
x
)
,
f
′
(
x
)
f(x),f'(x)
f(x),f′(x) 都可以称为超平面,这些函数的集合
{
f
∣
f
(
x
)
=
ω
⋅
x
+
b
}
\{f|f(x)=\omega \cdot x + b \}
{f∣f(x)=ω⋅x+b} 称为感知机模型的假设空间。
二、感知机学习策略
1.数据集的线性可分性
定义(数据集的线性可分性):给定一个数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T = \{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\} T={(x1,y1),(x2,y2),...,(xN,yN)}其中, x i ∈ χ = R n x_i \in \chi =R^n xi∈χ=Rn, y i = Y = { + 1 , − 1 } , i = 1 , 2 , . . . , N y_i=Y=\{+1,-1\},i=1,2,...,N yi=Y={+1,−1},i=1,2,...,N ,如果存在某个超平面 S S S能够将数据集的正实例点和负实例点完全正确的划分到超平面的两侧,即对所有 y i = + 1 y_i=+1 yi=+1 的实例 i i i,有 ω ⋅ x i + b > 0 \omega\cdot x_i + b >0 ω⋅xi+b>0,对于所有 y i = − 1 y_i=-1 yi=−1 ,有 ω ⋅ x i + b < 0 \omega\cdot x_i + b <0 ω⋅xi+b<0,则称数据集 T T T 为线性可分数据集(linearly separable data set),否则,称数据集 T T T 线性不可分。
2.感知机学习策略
感知机学习策略,主要是梳理,在给定一个线性可分的数据集后,如何得到将正实例点和负实例点完全正确分开的分离超平面2,换句话将,就是如何得到感知机函数中的 ω , b \omega,b ω,b这两个参数。
感知机采用误分类点到超平面 S S S 的总距离作为损失函数。因为该损失函数满足连续可导,容易优化3。
Step 1: 写出输入空间 R n R^n Rn 中任意一点 x 0 x_0 x0 到超平面 S S S 的距离4: 1 ∣ ∣ ω ∣ ∣ ∣ ω ⋅ x 0 + b ∣ \frac{1}{||\omega||}|\omega\cdot x_0 + b| ∣∣ω∣∣1∣ω⋅x0+b∣
Step 2: 对于误分类的数据 ( x i , y i ) (x_i,y_i) (xi,yi),始终存在: − y i ( ω ⋅ x i + b ) > 0 -y_i(\omega \cdot x_i +b) > 0 −yi(ω⋅xi+b)>0 所以误分类点的距离之和为:
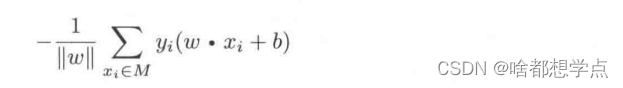
Step 3 :简化感知机损失函数为:
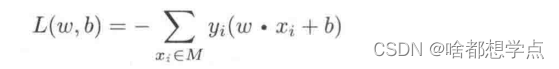
其中,
M
M
M 为误分类点的集合,这个损失函数就是感知机学习的经验风险函数。
关于不用考虑
−
1
∣
∣
ω
∣
∣
-\frac{1}{||\omega||}
−∣∣ω∣∣1的个人理解:
不用考虑是因为,我们之前假设的数据集首先是一个线性可分的数据集,这就确保了必然存在一个感知机能够将正实例点和负实例点完全分开,套用在公式中,就是肯定存在误分类点到分离超平面的距离之和为0的情况,所以我们只要使
L
(
ω
,
b
)
=
0
L(\omega,b)=0
L(ω,b)=0 即可,故不用考虑
−
1
∣
∣
ω
∣
∣
-\frac{1}{||\omega||}
−∣∣ω∣∣1。
Step 4: 由于损失函数 L ( ω , b ) L(\omega,b) L(ω,b) 是非负的,所以其最小值为0,即没有误分类的情况。感知机学习的策略是在假设空间中选取使损失函数最小的模型参数 ω , b \omega,b ω,b,即感知模型。
三、希望大家一起探讨的点
在书P38,第二段中,有这么一句话:“误分类点越少,误分类点里超平面越近,损失函数值就越小”。 大家怎么理解这句话?
个人认为,误分类点的多少并不能决定损失函数值的大小,比如
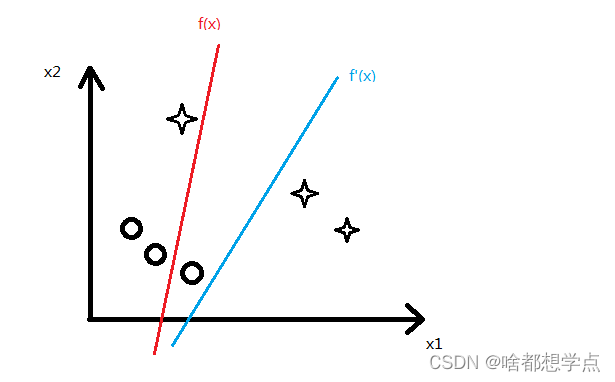
在上图中,
f
(
x
)
f(x)
f(x) 感知机模型有2个误分类点,
f
′
(
x
)
f'(x)
f′(x)感知机有1个误分类点,很明显,
f
‘’
(
x
)
f‘’(x)
f‘’(x) 的损失函数要大于
f
(
x
)
f(x)
f(x) 的损失函数。
所以个人认为,损失函数值的大小只与误分类点与超平面的距离成正比,与误分类点的多少无关。不知道可不可以这样理解。
所谓超平面,就是能够将数据有效进行分离的一个平面,在图中,我们对一个数据仅选取两个特征值,主要是为了方便观察,所以,图中的感知机模型为一条直线,当特征值选取为3个,或者更多时,数据的分布就会扩展到3维或者高维度中,相对应的感知机模型也会成为一个面,或者一个能将高维度数据分割的分割体。对于这些模型机,我们统一称之为超平面。 ↩︎
能将正实例点和负实例点完全正确分开的超平面,称为分离超平面 ↩︎
当函数满足连续可导时,对该函数进行偏微分,将偏微分等于0计算出的值,就是函数的极值。 ↩︎
点到直线的距离公式为: d = ∣ A x 0 + B y 0 + C A 2 + B 2 ∣ d=| \frac{Ax_0+By_0+C}{\sqrt{A^2+B^2}}| d=∣A2+B2Ax0+By0+C∣,对应到图中例子,其坐标为 x = ( x 1 , x 2 ) x=(x^1,x^2) x=(x1,x2) 对应公式中的 ( x , y ) (x,y) (x,y) , ω = ( ω 1 , ω 2 ) \omega = (\omega^1,\omega^2) ω=(ω1,ω2)对应公式中的 A , B A,B A,B, ∣ ∣ ω ∣ ∣ = ( ω 1 ) 2 + ( ω 2 ) 2 = A 2 + B 2 ||\omega||=\sqrt{(\omega^1)^2+(\omega^2)^2}=\sqrt{A^2+B^2} ∣∣ω∣∣=(ω1)2+(ω2)2=A2+B2,从而得到Step 1 中的距离公式。 ↩︎















 2438
2438











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









