







Outlier Detection for Time Series with Recurrent Autoencoder Ensembles文献阅读
这篇文章发表于2019年的IJCAI会议
摘要
作者提出了两种基于RNN自编码器集成的时间序列异常检测方法。这两种方法利用了sparsely-connected RNN构建的自动编码器。这种网络使得产生具有不同神经网络连接结构的多个自动编码器成为可能。这两种方法是集成框架,特别是独立框架和共享框架,两者都结合了基于Multiple S-RNN的自动编码器来实现离群点检测。这种基于集成的方法旨在减少一些自动编码器过度适应异常值的影响,从而提高整体检测质量。作者用两个real world的时间序列数据集(包括单变量和多变量时间序列)进行的实验,提供了对所提出的集成框架的设计的审视,并且证明了所提出的框架能够优于baseline和SOTA。
介绍
作为正在进行的社会和工业过程数字化的一部分,许多配备传感器的设备,如移动电话、GPS导航仪和医疗监视器,产生大量形成时间序列的时间有序观测值。这样的时间序列产生广泛,并且应用领域广泛。
经典的许多异常检测的方法是基于相似性搜索和基于密集聚类。15年开始,基于神经网络的自编码器被提出来应用于异常检测。这种方法的思想是,将原始数据压缩成紧凑的隐藏表示,然后从隐藏表示中重构输入数据。由于隐藏表示非常紧凑,因此只能从输入数据中重构代表性的特征,而不能重构细节,包括任何异常值。这种情况下,原始数据和重构数据之间的误差就能表示原始数据为异常值的可能性有多大。然后,集成的自编码器被用来进一步提高精度,用单一自编码器达到这种精度的时候可能出现过拟合。然而,有效的自动编码器集成只存在于非顺序数据,将它们应用于时间序列数据会直接产生不良结果。作者旨在通过提出两个RNN自动编码器集成框架来填补这一空白,以实现时间序列中的离群点检测。
作者提出利用稀疏连接RNN来实现由不同RNN结构组成的集成自编码器。作者提出了两个集成框架,一个独立的框架IF和一个共享的框架SF,结合多个稀疏连接的RNN自动编码器。具体来说,IF独立训练多个自动编码器。相比之下,在多任务学习原则的激励下,SF通过共享的特征空间联合训练多个自动编码器。对于这两个框架,作者使用多个自动编码器的重建误差的中值作为最终的重建误差,该误差量化了时间序列中的观测值成为异常值的可能性。因此,这两个框架受益于多个编码器和解码器的组合。
这是第一次提出使用RNN自编码器来实现异常检测。这篇文章的贡献如下:
1.作者提出采用稀疏连接的RNN单元来使得自编码器具有不同的网络结构。
2.提出了两个集成自编码器框架来实现异常检测。
3.在单变量和多变量序列上都进行了实验,从而验证了所提出框架的有效性。
Preliminaries
time series
一个时间序列 T = ⟨ s 1 , s 2 , … , s c ⟩ T=\langle s_1,s_2,\ldots,s_c\rangle T=⟨s1,s2,…,sc⟩是按照时间排列的向量序列。每个向量 s i = ( s i ( 1 ) , s i ( 1 ) , … , s i ( k ) ) s_i=(s_i^{(1)},s_i^{(1)},\ldots,s_i^{(k)}) si=(si(1),si(1),…,si(k))表示一个实体在时间 t t t上的 k k k 个特征,其中 1 ≤ i ≤ C 1\leq i\leq C 1≤i≤C。此外,当 i < j i<j i<j的时候,有 t i < t j t_i<t_j ti<tj。当 k = 1 k=1 k=1的时候,时间序列为单变量,当 k > 1 k>1 k>1的时候,时间序列为多变量。
outlier Detection in time series
给定时间序列 T = ⟨ s 1 , s 2 , … , s c ⟩ T=\langle s_1,s_2,\ldots,s_c\rangle T=⟨s1,s2,…,sc⟩,目标是为每个向量计算一个离群值得分 O S ( s i ) OS(s_i) OS(si),这样 O S ( s i ) OS(s_i) OS(si)越高,向量 s i s_i si成为离群值的可能性就越大。
autoencoders
典型的自动编码器是前馈全连接神经网络,其中输入层和输出层中的神经元数量相同,并且隐藏层中的神经元比输入层和输出层中的少得多。自动编码器旨在产生一个输出,该输出在去除噪声的情况下重构其输入。由于隐藏层由更少的神经元组成,为了尽可能接近地重建输入,隐藏层中的权重仅捕获原始输入数据的最具代表性的特征,而忽略输入数据的详细细节,例如异常值。换句话说,内联数据(即正常数据)比外联数据更容易重构。基于上述,输出(即重构输入)与原始输入之间的差异越大,对应的输入数据越有可能是异常值。
基于前馈神经网络的经典自动编码器通常用于非顺序数据。为了在时序数据(如时间序列)中执行离群点检测,Kieu等人提出了基于rnn的自动编码器,同时重新利用了较大重构误差表示异常点的思想。
Autoencoder Ensembles
遵循集成学习的原理,自动编码器集成旨在进一步提高基于自动编码器的离群点检测的准确性[陈等人,2017]。主要思想是建立一组自动编码器,并在检测异常值时考虑来自多个自动编码器的重建误差。使用一组经典的、完全连接的自动编码器没有帮助,因为不同自动编码器的网络结构是相同的。相反,对于每个自动编码器,随机移除一些连接以获得稀疏连接的自动编码器是有帮助的(参见图1)。然后,自动编码器集成由多个稀疏连接的具有不同网络结构的自动编码器组成,这有助于减少整体重建误差的方差[陈等人,2017]。
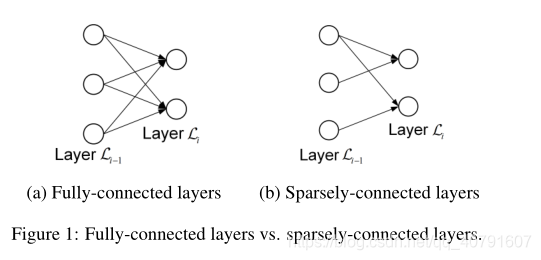
但是,自动编码器集成仅适用于非顺序数据,不能直接应用于时间序列等顺序数据(参见表1中的摘要)。作者通过提出两个能够在时间序列中执行异常检测的自动编码器集成框架来填补这一空白。
Autoencoder Ensembles For Time Series
作者利用rnn来构建自编码器,因为rnn被证实对于时间序列建模和学习都有效。
Sparsely-connected RNNs (S-RNNs)
seq-to-seq模型[Sutskever等人,2014]通常用作时间序列中离群点检测的自动编码器。这种模型有一个编码器和一个解码器,如图2所示。
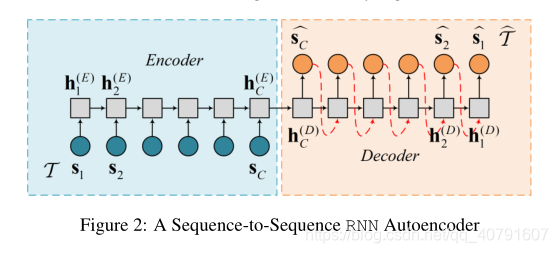
在编码器中,时间序列
T
T
T中的每个向量
s
t
s_t
st被输入到一个rnn单元中去,来执行下式的计算:
h
t
(
E
)
=
f
(
s
t
,
h
t
−
1
(
E
)
)
(1)
h_t^{(E)}=f(s_t,h_{t-1}^{(E)})\tag{1}
ht(E)=f(st,ht−1(E))(1)
其中,
s
t
s_t
st是
t
t
t时刻的向量,隐藏状态
h
t
−
1
(
E
)
h_{t-1}^{(E)}
ht−1(E)是
t
−
1
t-1
t−1时刻编码器中前一个RNN单元的输出。然后,
f
(
⋅
)
f(\cdot)
f(⋅)是一个非线性函数,可以是tanh或者sigmoid或者更复杂的LSTM。基于此,在
t
t
t时刻获得当前RNN单元的隐藏状态
h
t
(
E
)
h_{t}^{(E)}
ht(E),然后在
t
+
1
t+1
t+1时刻输入下一个RNN单元。
在解码器中,按照相反的顺序重建序列,得到
T
^
=
⟨
s
C
^
,
s
C
−
1
^
,
…
,
s
1
^
⟩
\hat{T}=\langle \hat{s_C},\hat{s_{C-1}},\dots,\hat{s_1}\rangle
T^=⟨sC^,sC−1^,…,s1^⟩。首先,编码器的最后一个隐藏状态被用作解码器的第一个隐藏状态。基于解码器先前的隐藏状态
h
^
t
+
1
(
D
)
\hat h_{t+1}^{(D)}
h^t+1(D)和前一个重建向量
s
^
t
+
1
\hat s_{t+1}
s^t+1,利用公式2计算当前的重构向量,利用公式3计算当前的隐藏状态,其中
f
(
⋅
)
f(\cdot)
f(⋅)和
g
(
⋅
)
g(\cdot)
g(⋅)仍然是非线性函数:
s
^
t
=
g
(
s
^
t
+
1
,
h
t
+
1
(
D
)
)
(2)
\hat s_t=g(\hat s_{t+1},h_{t+1}^{(D)})\tag 2
s^t=g(s^t+1,ht+1(D))(2)
h
t
(
D
)
=
f
(
s
^
t
,
h
t
+
1
(
D
)
)
(3)
h_t^{(D)}=f(\hat s_t,h_{t+1}^{(D)})\tag 3
ht(D)=f(s^t,ht+1(D))(3)
遵循现有非连续数据自动编码器集成的思想,作者旨在构建具有不同网络结构的多个自动编码器。但是,在这种设置下,随机删除RNN单元之间的连接是不可行的,因为无论删除哪个连接,RNN单元都会断开,从而无法训练网络。
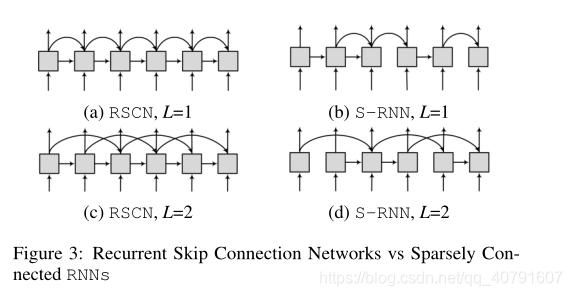
为了应对这一挑战,作者考虑在单元之间使用额外辅助连接的重复跳跃连接网络[王和田,2016]。特别地,每个RNN单元不仅考虑先前的隐藏状态,还考虑过去的附加隐藏状态。形式上,有:
h
t
=
f
(
s
t
,
h
t
−
1
)
+
f
′
(
s
t
,
h
t
−
L
)
2
(4)
h_t={f(s_t,h_{t-1})+f'(s_t,h_{t-L})}\over2\tag4
2ht=f(st,ht−1)+f′(st,ht−L)(4)
在这里,考虑了前一时刻的隐藏状态
h
t
−
1
h_{t-1}
ht−1和
L
L
L个step之前时刻的隐藏状态。使用两个不同的函数
f
(
⋅
)
f(\cdot)
f(⋅)和
f
′
(
⋅
)
f'(\cdot)
f′(⋅),图3 (a)和(c)显示了RSCNs当
L
=
1
L= 1
L=1和
L
=
2
L = 2
L=2的示例。
基于RSCNs,随机移除一些隐藏状态之间的联系。具体来说,作者引入了一个稀疏权重向量
w
t
=
(
w
t
(
f
)
,
w
t
(
f
′
)
)
w_t=(w_t^{(f)},w_t^{(f')})
wt=(wt(f),wt(f′))来控制在
t
t
t时刻哪个连接应该被移除, 其中
w
t
(
f
)
∈
{
0
,
1
}
w_t^{(f)}\in\{0,1\}
wt(f)∈{0,1},
w
t
(
f
′
)
∈
{
0
,
1
}
w_t^{(f')}\in\{0,1\}
wt(f′)∈{0,1}。并且保证
w
t
w_t
wt中有一个元素不为0,即
w
t
=
(
1
,
0
)
,
w
t
=
(
0
,
1
)
,
w
t
=
(
1
,
1
)
w_t=(1,0),w_t=(0,1),w_t=(1,1)
wt=(1,0),wt=(0,1),wt=(1,1)。
基于
w
t
w_t
wt,作者提出了稀疏连接RNNs(s-RNNs),其中每一个单元的计算定义如下式5:
h
t
=
f
(
s
t
,
h
t
−
1
)
⋅
w
t
(
f
)
+
f
′
(
s
t
,
h
t
−
L
)
⋅
w
t
(
f
′
)
∣
∣
w
t
∣
∣
0
(5)
h_t ={{f(s_t,h_{t-1})\cdot w_t^{(f)}+f'(s_t,h_{t-L})\cdot w_t^{(f')}}\over {||w_t||_0}}\tag 5
ht=∣∣wt∣∣0f(st,ht−1)⋅wt(f)+f′(st,ht−L)⋅wt(f′)(5)
其中
∣
∣
w
t
∣
∣
0
||w_t||_0
∣∣wt∣∣0表示向量
w
t
w_t
wt中非零元素的数量,图3(b)和(d)展示了S-RNNs当
L
=
1
L= 1
L=1和
L
=
2
L = 2
L=2的例子。
S-RNNs不同于使用dropout的RNNs[Gal和Ghahramani,2016]。稀疏连接的RNNs在整个训练阶段是固定的,而含有dropout的RNNs在每个训练周期随机移除连接。
S-RNN Autoencoder Ensembles
为了实现ensemble,作者构建了一组S-RNN自动编码器。然后,提出了两种不同的框架来将自动编码器整合到ensemble中去。
Independent Framework
图4显示了S-RNN自动编码器集成的基本独立框架。该集合包含
N
N
N个S-RNN自动编码器,每个自动编码器由一个编码器
E
i
E_i
Ei和一个解码器
D
i
D_i
Di组成,
1
≤
i
≤
N
1 ≤ i ≤ N
1≤i≤N。此外,每个自动编码器具有其独特的稀疏性权重向量。
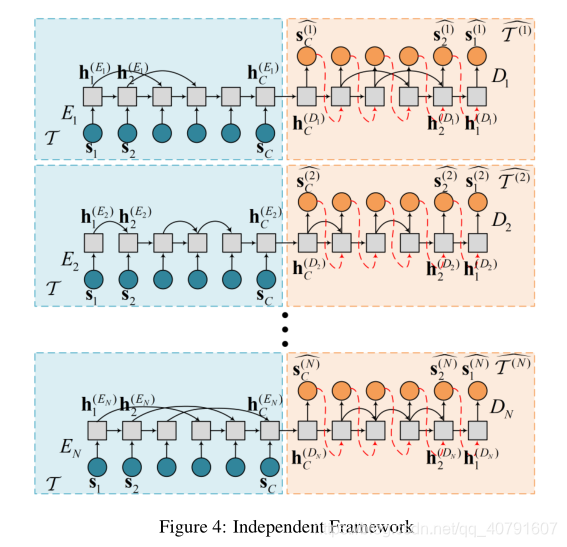
集合中的每个自动编码器通过最小化目标函数来独立训练,该目标函数
J
i
\mathcal{J}_i
Ji测量原始时间序列中的输入向量和重建向量之间的差异,如等式6中所定义。
J
i
=
∑
t
=
1
C
∥
s
t
−
s
^
t
(
D
i
)
∥
2
2
(6)
\mathcal{J}_{i}=\sum_{t=1}^{C}\left\|\mathbf{s}_{t}-\hat{\mathbf{s}}_{t}^{\left(D_{i}\right)}\right\|_{2}^{2}\tag 6
Ji=t=1∑C∥∥∥st−s^t(Di)∥∥∥22(6)其中
s
^
t
(
D
i
)
\hat{\mathbf{s}}_{t}^{\left(D_{i}\right)}
s^t(Di)表示解码器
D
i
D_i
Di在
t
t
t时刻的重构向量,
∣
∣
⋅
∣
∣
2
||\cdot||_2
∣∣⋅∣∣2是L2范数。
Shared Framework
基本框架独立地训练不同的自动编码器,这意味着不同的自动编码器在训练阶段不相互作用。然而,由于所有的自动编码器都试图重建相同的原始时间序列,因此让自动编码器之间进行交互是重要的。受多任务学习原则的激励[龙等,2017;Cirstea等人,2018年;Kieu等人,2018a],作者提出了一个共享的框架,它包含了不同自动编码器之间的交互。更具体地说,给定N个任务,其中每个任务重建原始时间序列,让这N个任务通过一个共享层进行交互。共享框架如图5所示。
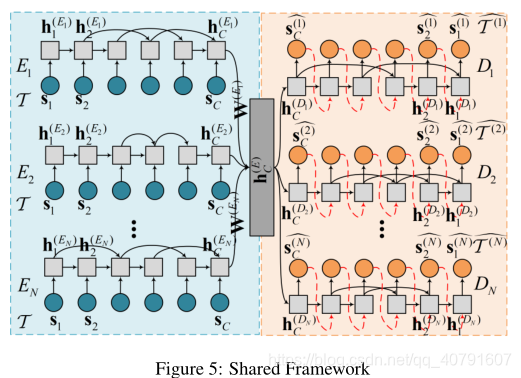
如图5所示,SF框架采用一个共享层
h
C
(
E
)
\mathbf h_C^{(E)}
hC(E)来将所有隐藏层最终的输出进行线性组合,使用线性权重矩阵
W
(
E
i
)
\mathbf W^{(E_i)}
W(Ei),形式上有:
h
C
(
E
)
=
concatenate
(
h
C
(
E
1
)
⋅
W
(
E
1
)
,
…
,
h
C
(
E
N
)
⋅
W
(
E
N
)
)
\mathbf{h}_{C}^{(E)}=\operatorname{concatenate}\left(\mathbf{h}_{C}^{\left(E_{1}\right)} \cdot \mathbf{W}^{\left(E_{1}\right)}, \ldots, \mathbf{h}_{C}^{\left(E_{N}\right)} \cdot \mathbf{W}^{\left(E_{N}\right)}\right)
hC(E)=concatenate(hC(E1)⋅W(E1),…,hC(EN)⋅W(EN))
当重构时间序列
T
^
(
i
)
=
⟨
s
^
C
(
i
)
,
…
,
s
^
2
(
i
)
,
s
^
1
(
i
)
⟩
\hat{\mathcal{T}}^{(i)}=\left\langle\hat{\mathbf{s}}_{C}^{(i)}, \ldots, \hat{\mathbf{s}}_{2}^{(i)}, \hat{\mathbf{s}}_{1}^{(i)}\right\rangle
T^(i)=⟨s^C(i),…,s^2(i),s^1(i)⟩的时候,每个解码器
D
i
D_{i}
Di把线性组合后的
h
C
(
E
)
\mathbf{h}_{C}^{(E)}
hC(E) 作为初始隐藏状态。在SF框架中,通过最小化目标函数
J
\mathcal{J}
J和共享隐藏状态上的L1正则项来联合训练所有自动编码器,该目标函数
J
\mathcal{J}
J将所有自动编码器的重建误差进行求和:
J
=
∑
i
=
1
N
J
i
+
λ
∥
h
C
(
E
)
∥
1
(7)
\mathcal{J} =\sum_{i=1}^{N} \mathcal{J}_{i}+\lambda\left\|\mathbf{h}_{C}^{(E)}\right\|_{1}\tag7
J=i=1∑NJi+λ∥∥∥hC(E)∥∥∥1(7)
=
∑
i
=
1
N
∑
t
=
1
C
∥
s
t
−
s
^
t
(
D
i
)
∥
2
2
+
λ
∥
h
C
(
E
)
∥
1
(8)
=\sum_{i=1}^{N} \sum_{t=1}^{C}\left\|\mathbf{s}_{t}-\hat{\mathbf{s}}_{t}^{\left(D_{i}\right)}\right\|_{2}^{2}+\lambda\left\|\mathbf{h}_{C}^{(E)}\right\|_{1}\tag8
=i=1∑Nt=1∑C∥∥∥st−s^t(Di)∥∥∥22+λ∥∥∥hC(E)∥∥∥1(8)其中,
λ
\lambda
λ是控制L1正则项
∥
h
C
(
E
)
∥
1
\left\|\mathbf{h}_{C}^{(E)}\right\|_{1}
∥∥∥hC(E)∥∥∥1的权重。L1正则化具有使共享隐藏状态
h
C
(
E
)
\mathbf h_C^{(E)}
hC(E)稀疏的效果。这避免了一些编码器过拟合,并有助于使解码器更具有鲁棒性,更少受到异常值的影响。因此,当自动编码器遇到异常值时,原始时间序列和重建时间序列之间的差异更加明显。
Ensemble Outlier Scoring
根据自动编码器集成对非序列数据的原理[陈等人,2017],当使用集成框架时,计算时间序列中每个向量的异常值分数。回想一下,我们有N个自动编码器来重建原始时间序列 T = ⟨ s 1 , s 2 , … , s c ⟩ \mathcal T=\langle s_1,s_2,\ldots,s_c\rangle T=⟨s1,s2,…,sc⟩。因此,我们得到了N个重构时间序列 T ( i ) ^ = ⟨ s C ^ ( i ) , s C − 1 ^ ( i ) , … , s 1 ^ ( i ) ⟩ \hat{T^{(i)}}=\langle \hat{s_C}^{(i)},\hat{s_{C-1}}^{(i)},\dots,\hat{s_1}^{(i)}\rangle T(i)^=⟨sC^(i),sC−1^(i),…,s1^(i)⟩,其中 1 ≤ i ≤ N 1 ≤ i ≤ N 1≤i≤N .对于原始时间序列T中的每个向量 s k s_k sk,计算N个重构误差 { ∥ s k − s ^ k ( 1 ) ∥ 2 2 , ∥ s k − s ^ k ( 2 ) ∥ 2 2 , … , ∥ s k − s ^ k ( N ) ∥ 2 2 } \left\{\left\|\mathbf{s}_{k}-\hat{\mathbf{s}}_{k}^{(1)}\right\|_{2}^{2},\left\|\mathbf{s}_{k}-\hat{\mathbf{s}}_{k}^{(2)}\right\|_{2}^{2}, \ldots,\left\|\mathbf{s}_{k}-\hat{\mathbf{s}}_{k}^{(N)}\right\|_{2}^{2}\right\} {∥∥∥sk−s^k(1)∥∥∥22,∥∥∥sk−s^k(2)∥∥∥22,…,∥∥∥sk−s^k(N)∥∥∥22}。我们使用N个误差的中值 s k : O S ( s k ) = median ( ∥ s k − s ^ k ( 1 ) ∥ 2 2 , ∥ s k − s ^ k ( 2 ) ∥ 2 2 , … , ∥ s k − s ^ k ( N ) ∥ 2 2 ) . s_{k}: O S\left(\mathbf{s}_{k}\right)=\operatorname{median}\left(\left\|\mathbf{s}_{k}-\hat{\mathbf{s}}_{k}^{(1)}\right\|_{2}^{2},\left\|\mathbf{s}_{k}-\hat{\mathbf{s}}_{k}^{(2)}\right\|_{2}^{2}, \ldots, \| \mathbf{s}_{k}-\right.\left.\hat{\mathbf{s}}_{k}^{(N)} \|_{2}^{2}\right) . sk:OS(sk)=median(∥∥∥sk−s^k(1)∥∥∥22,∥∥∥sk−s^k(2)∥∥∥22,…,∥sk−s^k(N)∥22).来作为最终的异常分数。使用中值可以防止自编码器对原始数据的过拟合。
Experiments
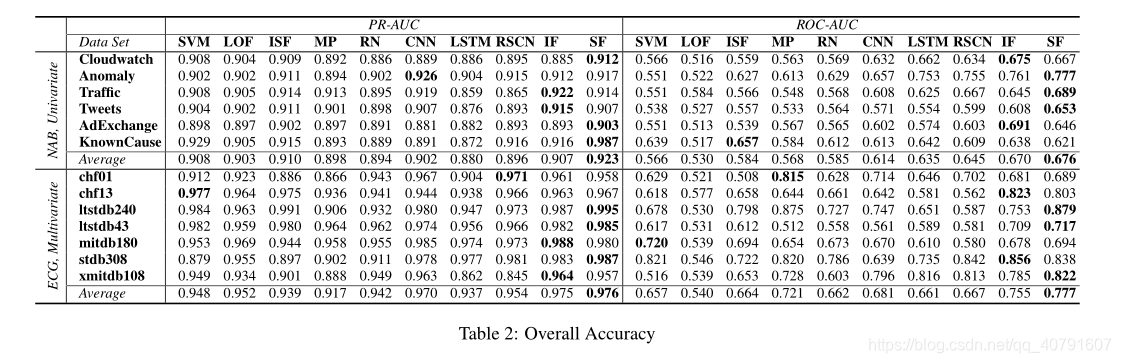














 304
304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









