







鉴于日常学习中常遇到将文本数据等转为向量,然后计算向量相似度的问题,现将常用方案进行初步汇总,如统计不足敬请留言提示补充:
1、余弦相似度(cosine)
公式:

即:以向量的夹角为考量角度,以向量的内积(各对应元素相乘求和)比两个向量的模的积为计算结果。
由于余弦相似度表示方向上的差异,对距离不敏感,所以有时候也关心距离上的差异会先对每个值都减去一个均值,这样称为调整余弦相似度。
2、欧氏距离(Euclidean)
公式:

即:基本上考虑的是点的空间距离,各对应元素做差取平方求和后开方。
欧式距离能够体现个体数值的绝对差异,更多用于需要从维度的数值大小中体现差异的分析,如利用用户行为指标评价用户相似度和差异度;余弦相似度从方向上区分差异,对绝对数值不敏感,更多用于根据评论评价用户兴趣的相似度和差异度,此外可修整用户间可能存在的度量标准不一致的问题(对绝对数值不敏感)。
3、曼哈顿距离(Manhattan distance)
公式:
d(i,j)=|X1-X2|+|Y1-Y2|.
即:向量各对应坐标间做差求绝对值后求和。
曼哈顿距离的由来是在规划为方形建筑区块的城市(曼哈顿)内,计算最短的行车路径。从某一地点到另一地点,必须走固定的n个区块,没有其它捷径。为了便于理解,如下:

4、皮尔逊相关系数(PC:Pearson correlation coefficient)
公式:
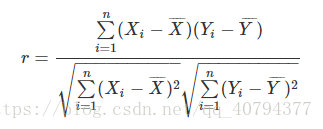
即:上面所提到的调整的余弦相似度,向量内各对应元素减去均值求积后求和,记为结果1;各对应元素减去均值平方求和再求积,记为结果2;结果1比结果2.
针对线性相关情况,可用于比较因变量和自变量间相关性如何。
5、斯皮尔曼(等级)相关系数(SRC :Spearman Rank Correlation)
公式:
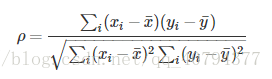
即:和上述类似,不同的是将对于样本中的原始数据Xi,Yi转换成等级数据xi,yi,即xi等级和yi等级。并非考虑原始数据值,而是按照一定方式(通常按照大小)对数据进行排名,取数据的不同排名结果代入公式。
实际上,可通过简单的方式进行计算,n表示样本容量,di表示两向量X和Y内对应元素的等级的差值,等级di = xi - yi,则:
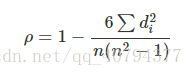
例如( 维基百科):
| 智商, XiXi | 每周花在电视上的小时数, YiYi | 等级xi | 等级yi | di | di2 |
|---|---|---|---|---|---|
| 86 | 0 | 1 | 1 | 0 | 0 |
| 97 | 20 | 2 | 6 | -4 | 16 |
| 99 | 28 | 3 | 8 | -5 | 25 |
| 100 | 27 | 4 | 7 | -3 | 9 |
| 101 | 50 | 5 | 10 | -5 | 25 |
| 103 | 29 | 6 | 9 | -3 | 9 |
| 106 | 7 | 7 | 3 | 4 | 16 |
| 110 | 17 | 8 | 5 | 3 | 9 |
| 112 | 6 | 9 | 2 | 7 | 49 |
| 113 | 12 | 10 | 4 | 6 | 36 |
n = 10,di2的和为194,则可代入公式计算出结果为:-0.17575757...,Xi和Yi几乎不相关。
6、杰卡德相似系数(Jaccard距离)
公式:
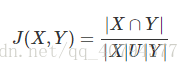
即:用来衡量两个集合差异性的一个指标,交集除以并集,向量(文本)相似度用共同出现的元素(词语、短语等特征)除以两者的总量。
7、SimHash+汉明距离(Hamming Distance)
Simhash:谷歌发明,根据文本转为64位的字节,计算汉明距离判断相似性。
汉明距离:在信息论中,两个等长字符串的汉明距离是两者间对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:
“10110110”和“10011111”的汉明距离为3; “abcde”和“adcaf”的汉明距离为3.
8、等......(待你补充 )
)















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









