







主要的逻辑:
main.py为主入口,然后开始从cookies_url.py内读取对于的cookies和url;
然后将返回的数据调用数据处理的函数。
数据处理时,会从biao.py内读取相应的渠道和游戏名。
最终main.py内会将处理完成后的数据写入对应时间的xls
具体的url分析
以友盟为例:
打开fiddler;
浏览器进入友盟相应游戏界面,点击昨日的按钮:


可以在fiddler里看到实际的请求链接和返回的数据。

然后将cookies和相应的链接填入cookies_url.py的对应字典。
同时在biao.py内将数据处理时所需要的渠道和游戏名对应填好。
简单的链接和cookies获取方式
链接获取方式
浏览器内打开对于游戏的渠道数据查看页面。F12打开调试工具。
选择network标签

点击昨日按钮
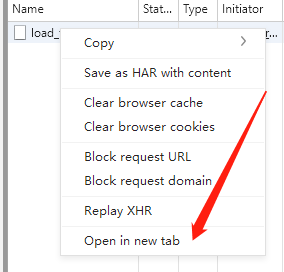
在出现的请求上右键,点击open in new tab

当前的链接即为实际的请求链接。
cookies获取方式
下载八爪鱼采集器

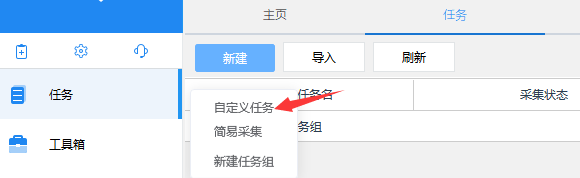
填入之前的请求链接,由于之前没有登录,会跳转至登录页面,登录后


点击打开网页重新进入链接,点击获取当前页面cookies。

然后点击a的标签小按钮。即可获取相应的cookies。















 1828
1828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









