







 文章详细描述了如何使用OpenCompass评测InternLM2-Chat-7B模型在C-Eval数据集上的性能,包括基础作业中的直接评测和进阶作业中使用LMDeploy部署后的对比。文中提供了配置文件修改和评测流程的详细步骤。
文章详细描述了如何使用OpenCompass评测InternLM2-Chat-7B模型在C-Eval数据集上的性能,包括基础作业中的直接评测和进阶作业中使用LMDeploy部署后的对比。文中提供了配置文件修改和评测流程的详细步骤。
基础作业
- 使用 OpenCompass 评测 InternLM2-Chat-7B 模型在 C-Eval 数据集上的性能
进阶作业
- 使用 OpenCompass 评测 InternLM2-Chat-7B 模型使用 LMDeploy 0.2.0 部署后在 C-Eval 数据集上的性能
1. 基础作业
使用 OpenCompass 评测 InternLM2-Chat-7B 模型在 C-Eval 数据集上的性能
1.1 修改配置文件
from opencompass.models import HuggingFaceCausalLM
from mmengine.config import read_base
with read_base():
from .datasets.ceval.ceval_gen_5f30c7 import ceval_datasets # noqa: F401, F403
# and output the results in a choosen format
#from .summarizers.medium import summarizer
_meta_template = dict(
round=[
dict(role='HUMAN', begin='<|im_start|>user\n', end='<|im_end|>\n'),
dict(role='SYSTEM', begin='<|im_start|>system\n', end='<|im_end|>\n'),
dict(role='BOT', begin='<|im_start|>assistant\n', end='<|im_end|>\n', generate=True),
],
eos_token_id=92542
)
internlm_meta_template = dict(round=[
dict(role='HUMAN', begin='<|User|>:', end='\n'),
dict(role='BOT', begin='<|Bot|>:', end='<eoa>\n', generate=True),
],
eos_token_id=103028)
models = [
dict(
type=HuggingFaceCausalLM,
abbr='internlm2-chat-7b',
path="/root/share/model_repos/internlm2-chat-7b/",
tokenizer_path='/root/share/model_repos/internlm2-chat-7b/',
model_kwargs=dict(
trust_remote_code=True,
device_map='auto',
),
tokenizer_kwargs=dict(
padding_side='left',
truncation_side='left',
use_fast=False,
trust_remote_code=True,
),
max_out_len=16,
max_seq_len=2048,
batch_size=4,
meta_template=internlm_meta_template,
run_cfg=dict(num_gpus=1, num_procs=1),
# end_str='<|im_end|>',
)
]
datasets = [*ceval_datasets]1.2 启动评测
python run.py configs/eval_internlm2_chat_7b.py1.3 评测完成
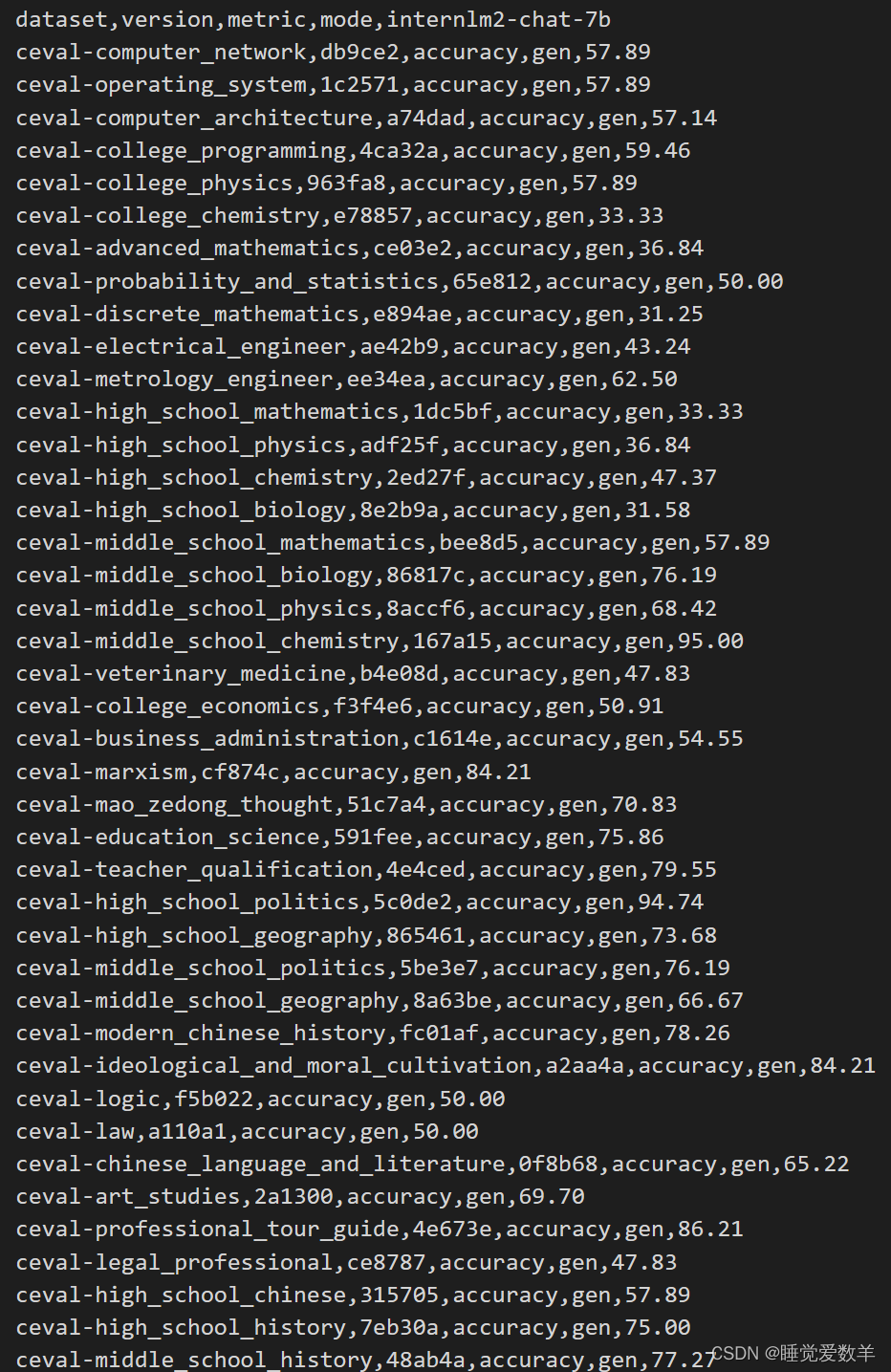
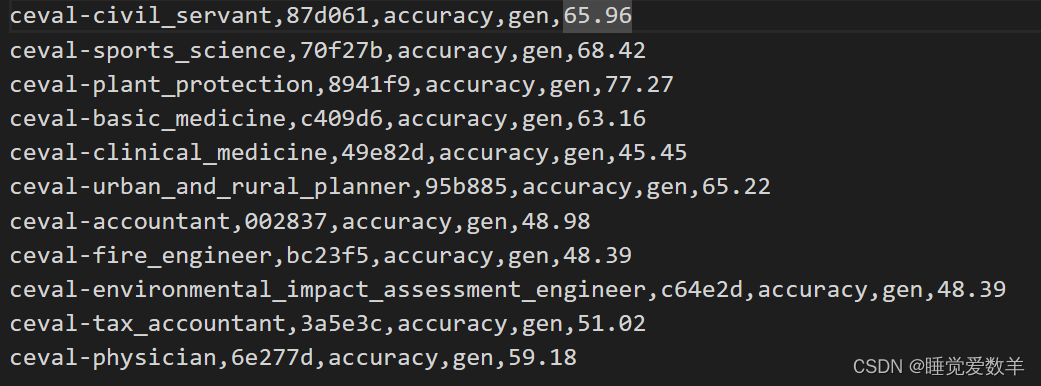

2. 进阶作业
使用 OpenCompass 评测 InternLM2-Chat-7B 模型使用 LMDeploy 0.2.0 部署后在 C-Eval 数据集上的性能
参考文档:
评测 LMDeploy 模型 — OpenCompass 0.2.1 文档
2.1 安装lmdeploy0.2.0
2.2 修改配置文件
from mmengine.config import read_base
from opencompass.models.turbomind import TurboMindModel
with read_base():
# choose a list of datasets
# from .datasets.mmlu.mmlu_gen_a484b3 import mmlu_datasets
from .datasets.ceval.ceval_gen_5f30c7 import ceval_datasets
# from .datasets.SuperGLUE_WiC.SuperGLUE_WiC_gen_d06864 import WiC_datasets
# from .datasets.SuperGLUE_WSC.SuperGLUE_WSC_gen_7902a7 import WSC_datasets
# from .datasets.triviaqa.triviaqa_gen_2121ce import triviaqa_datasets
# from .datasets.gsm8k.gsm8k_gen_1d7fe4 import gsm8k_datasets
# from .datasets.race.race_gen_69ee4f import race_datasets
# from .datasets.crowspairs.crowspairs_gen_381af0 import crowspairs_datasets
# and output the results in a choosen format
from .summarizers.medium import summarizer
datasets = sum((v for k, v in locals().items() if k.endswith('_datasets')), [])
internlm_meta_template = dict(round=[
dict(role='HUMAN', begin='<|User|>:', end='\n'),
dict(role='BOT', begin='<|Bot|>:', end='<eoa>\n', generate=True),
],
eos_token_id=103028)
# config for internlm2-chat-7b
internlm2_chat_7b = dict(
type=TurboMindModel,
abbr='internlm2-chat-7b-turbomind',
path='/root/share/model_repos/internlm2-chat-7b/',
engine_config=dict(session_len=2048,
max_batch_size=32,
rope_scaling_factor=1.0),
gen_config=dict(top_k=1,
top_p=0.8,
temperature=1.0,
max_new_tokens=100),
max_out_len=16,
max_seq_len=2048,
batch_size=4,
concurrency=32,
meta_template=internlm_meta_template,
run_cfg=dict(num_gpus=1, num_procs=1),
)
models = [internlm2_chat_7b]
2.3 启动评测
python run.py configs/eval_internlm2_chat_7b_turbomind.py 若报错显存不足,换成显存40G的开发机即可

2.4 评测完成
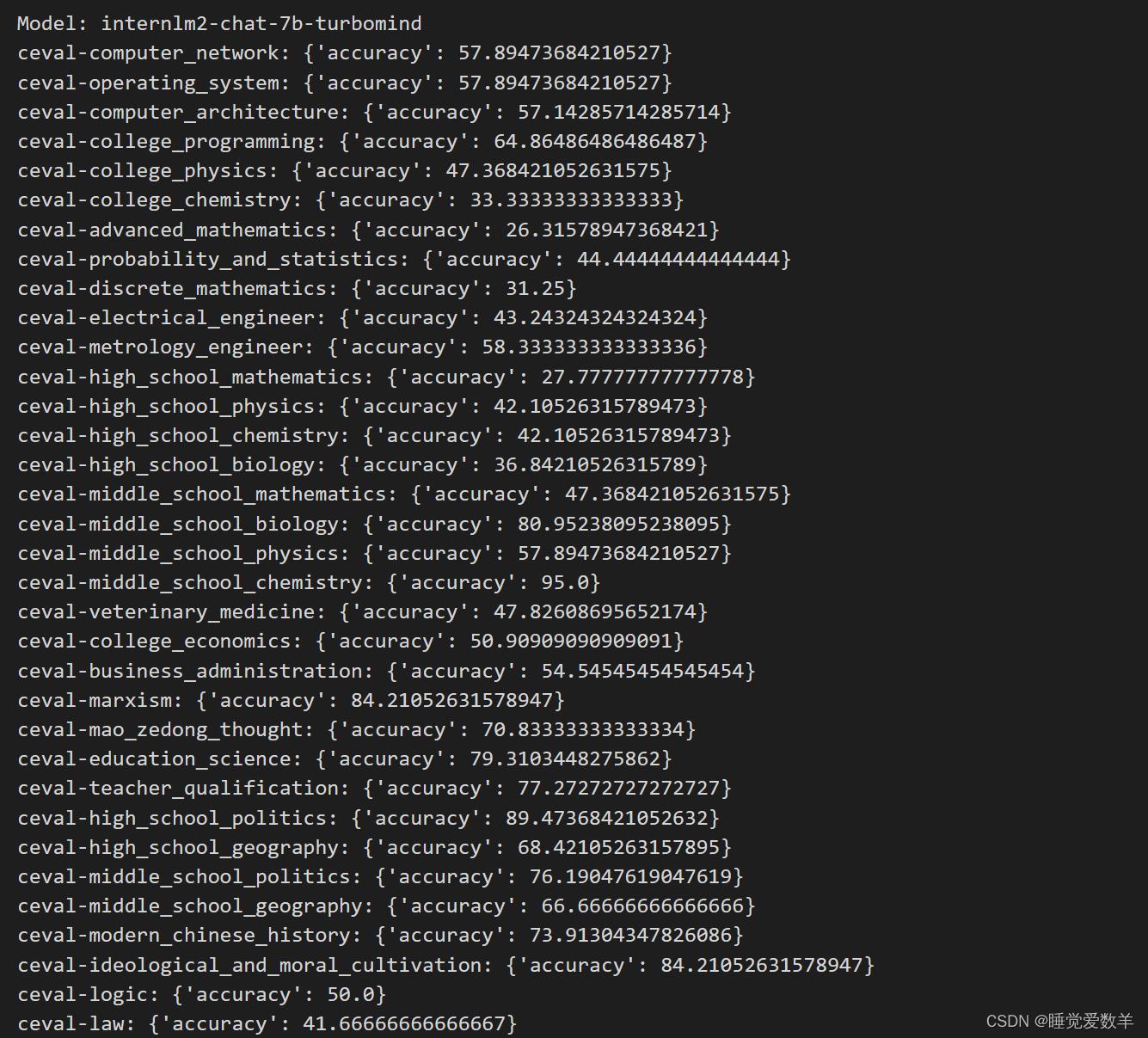
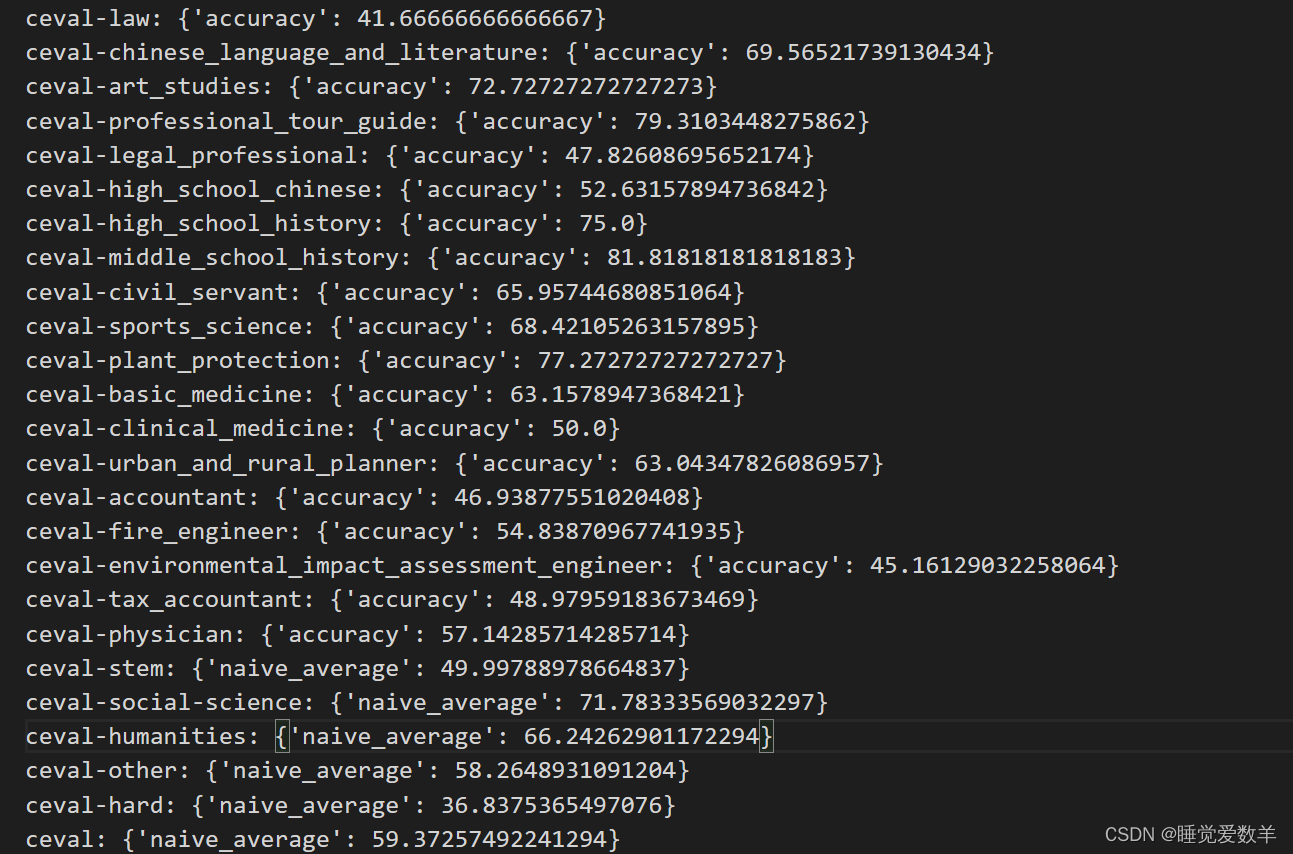
2.5 对比
使用LMDepoly平均分:59.37
未使用LMDepoly平均分:60.62
使用LMDeploy花费时间:

未使用LMDeploy花费时间:
















 497
497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









