







Does Every Second Count?
Time-based Evolution of Malware Behavior in
Sandboxes
背景
随着恶意软件的增多,对网络环境的威胁越来越大,沙箱是一种检测恶意软件的自动化技术,将潜在的恶意软件放入虚拟环境对其分析判定其是否存在危险行为。在利用沙箱对样本进行分析的过程中,分析时间是一个很重要的参数,时间过短很可能难以获得足够能分析样本行为的信息,时间过长会影响到更多样本的分析,本文发现,在前面的许多研究中,研究人员只是凭借主观经验设置分析时间,并没有科学的理论和实验的支撑。
因此,本文分析了执行时间与样本行为的关联。
实现
本文通过观察API或系统调用获得样本的行为,然而新的系统调用并不一定代表着新行为的出现,为此,作者提出三种方法:
①首先,将研究系统调用的列表和高级操作的新类的出现;
②其次,收集在沙箱中执行的实际代码,用来捕获每个系统调用执行时的上下文;观察新行为的出现的一种自然的方法就是检查执行跟踪,即新代码等于新的运行时行为(信息数量)
③使用机器学习分类器以确定将样本标记为恶意的新行为有多重要(信息质量)。在使用机器学习分类器方法中,作者提出三个度量标准:
- 相对覆盖率:
时间t内,行为(观察到的系统调用次数或执行代码的数量/该样本在整个执行间隔内观察到的最大数量)通过定义这一概念,可以判断出减少分析时间得到的分析内容会损失多少。在实验中用到相对系统调用覆盖率(Rs)和相对代码覆盖率(Rc) - 绝对代码覆盖率
它试图估计在总的样本代码中执行了多少代码(可以知道未执行的代码还有多少) - 使用机器学习分类器的准确性
通过延长时间窗口的长度并测量最终的分类精度,可以评估在特定的执行时间内收集到的数据的质量。
同时,为了减少因为恶意软件休眠躲避沙箱的检查的概率,本文利用在Kernel32.dll中挂钩Sleep和slepex函数来检测这种情况,将睡眠时间加到系统时间中。
数据集和评估
分析时间与收集信息量的关系
数据集中包含806个不同的恶意软件家族,数据集分布很均匀。实验在运行32位版本的Windows 7 Service Pack 1 的沙箱进行,对每个样本进行15分钟的分析,通过PANDA插件收集所有的信息。


实验中,大多数恶意样本在到达沙箱阈值之前就停止了他们的执行,超过一半在一分钟内终止。上图显示了良性文件恶意文件的全部累计执行时间,从中可以看到,程序要么在前三分钟终止,要么继续运行超过13分钟。
机器学习分类器判断信息重要性
为了分析收集的信息对于判别行为的重要性,利用机器学习分类器。
本文利用机器学习分类器判断时间窗口长度和每个时间窗口的信息量对于分类贡献。
所用的序列推理模型类似于神经网络模型,不过在其中加入了上一阶段的影响。
将收集到的恶意软件样本中的所有系统调用以及参数转换为分类特征,
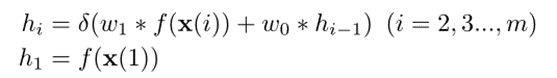
f(xi)表示将类别特征向量映射到标量嵌入变量的嵌入函数,hi表示系统调用序列从开始到第i个时间步长的潜伏期嵌入,δ设为s型激活函数,w1和w0是权值。选择f作为梯度增强回归树来生成分类特征的嵌入,以避免训练LSTM和训练前分类特征的word2vec嵌入作为LSTM输入的高强度计算。
发现:通过数据,发现更长的时间周期并不会导致更好的分类性能,对恶意软件进行分析收集数据的数量, 还有收集数据的“质量”(就对样本进行分类的有用程度而言),主要集中在执行的前两分钟。。
1234567
@本文利用机器学习实现对样本性质的判定,利用梯度增强回归树处理输入使得不需要任何预先训练的嵌入,同时可以平衡样本
@利用序列推理模型(同时获得时空特征)
@交叉验证,80%的数据用于训练分类器,20%的用于评估构建的分类器的分类精度,利用ROC曲线和PR曲线评估。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









