






先是说明一下这个问题:
我们在看很多大佬写的代码时候,特别是涉及到分布式训练的时候会发现他们在 argsparse 中添加了这样一个参数“--loacl_rank”,比如下面是Swin-Transformer官方训练源码中cmd参数声明的一个部分,可以看到第70行添加了一个"“--local_rank”。

可是我们知道local_rank一般是需要动态获取的(也就是获取当前进程在本机上的rank),而不是由用户设置为固定值,所以它这个参数声明是什么意思呢。
问题解决:
其实这个问题在官方的说明文档上已经给出了答案:

大概内容就是,这个命令行参数“--loacl_rank”是必须声明的,但它不是由用户填写的,而是由pytorch为用户填写,也就是说这个值是会被自动赋值为当前进程在本机上的rank。但是有的新手(比如我),就会把这个参数理解为是需要用户声明,而用户声明的值会覆盖pytorch为用户生成的值,因此就会产生莫名其妙的错误。
问题扩展
现在命令行参数“--loacl_rank”的问题解决了,还以一个问题,就是还有很多大佬的代码在分布式训练中并没有声明命令行参数“--loacl_rank”,但程序同样可以运行,这是为什么呢?
回答这个问题首先需要解释一下pytorch分布式训练的启动方式(当然这种方式官方已经建议废弃,但在很多SOTA论文的代码中都使用这种方式,所以有必要了解):
python -m torch.distributed.launch --nproc_per_node 3 --use_env main.py其中“--nproc_per_node”是每个节点的进程数量,“main.py”是程序的入口脚本。但“--use_env”这个参数,很多人拿来就用了,并没有注意它是干什么的,官方是这样解释的:

大概意思就是说,声明“--use_env”后,pytorch会将当前进程在本机上的rank添加到环境变量“LOCAL_RANK”中,而不再添加到args.local_rank。大家可以看一下下面的代码就理解了:
# d.py
import os
import argparse
def main(args):
local_rank = args.local_rank
print(local_rank, os.environ['LOCAL_RANK'])
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int)
args = parser.parse_args()
main(args)
输出:
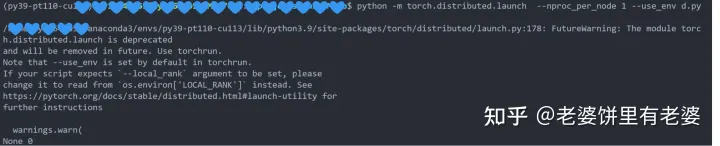
也就是说如果声明“--use_env”那么pytorch就会把当前进程的在本机上的rank放到环境变量中,而不会放在args.local_rank中。
同时上面的输出大家可能也也注意到了,官方现在已经建议废弃使用torch.distributed.launch,转而使用torchrun,而这个torchrun已经把“--use_env”这个参数废弃了,转而强制要求用户从环境变量LOACL_RANK里获取当前进程在本机上的rank(一般就是本机上的gpu编号)。关于这样更改后的新写法大家可以参考:
官方文档,以及github上facebookai实现的detr

















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









