







1.数据集(开始位置),数据集免费下载链接:https://download.csdn.net/download/qq_40840797/89051099
数据集一共8列,第一列是时间,特征列一共有6列:"WindSpeed" - 风速 "Sunshine" - 日照时数 "AirPressure" - 大气压力 "Radiation" - 辐射 "AirTemperature" - 空气温度 "RelativeAirHumidity" - 相对空气湿度。被预测列为最后一列:光伏发电量
数据采集每间隔一个小时,开始时间是2017.1.1号凌晨
数据截止时间:2017年12月31号23:00

预测(训练集和测试集比例:4:1)
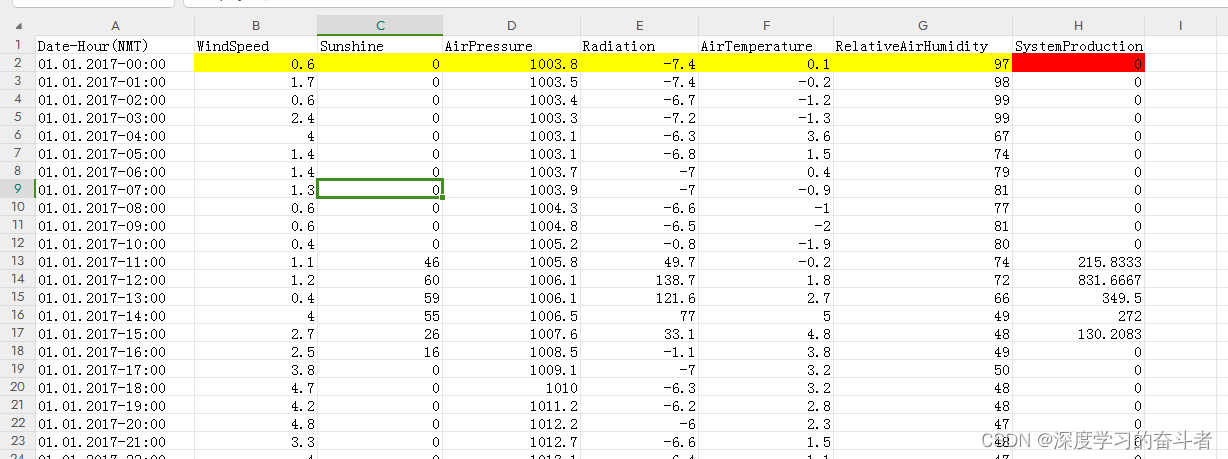
黄色部分是一个样本的输入,红色部分为该样本预测输出
测试集预测结果

指标(归一化后的数据进行衡量指标):
测试集上的MAE/MSE:
MAE: 0.010868210556556764
MSE: 0.0014309633127727228
衡量指标代码
from sklearn.metrics import mean_squared_error
from sklearn.metrics import mean_absolute_error
from math import sqrt
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 输出模型性能指标
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
print('测试集上的MAE/MSE:')
print('MAE:', mae)
print('MSE:', mse)
#代码和数据集压缩包:https://mbd.pub/o/bread/mbd-ZZ2alZhu















 902
902











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











