









实验数据来自山西某矿 15103 工作面,时间跨度为 2020 年 9 月 16 日至 2021 年 12 月 31 日,包括瓦斯浓度、CO 浓度、温度、风速、工作面粉尘、瓦斯流量、负压、管道内瓦斯浓度 8 种数据,数据采集间隔为 1 天。
1.数据集介绍
瓦斯是被预测气体,其它列为特征列,原始数据一共有472行数据,因为原始数据比较少,所以要对原始数据(总共8列数据)进行扩增。
开始数据截图

截止数据截图

2. 文件夹介绍

lstm.py是对未扩增的数据进行训练和测试
gan_code.py是数据扩增文件。
gan_data1.npy保留扩增以后的伪数据
gan_lstm.py 是利用扩增后的数据与原始数据的一部分一起作为训练集,对测试集进行测试。
扩增程序运行视频(为减小视频时长,视频中训练次数设置为2):
基于timegan扩增技术,进行多维度数据扩增_哔哩哔哩_bilibili
扩增程序运行5000个train_steps,也就是训练5000次后,将扩增数据与真实数据,利用PCA和TNSE进行特征可视化,可以看出扩增出来的数据与原始数据特征分布近似,扩增数据效果较佳。
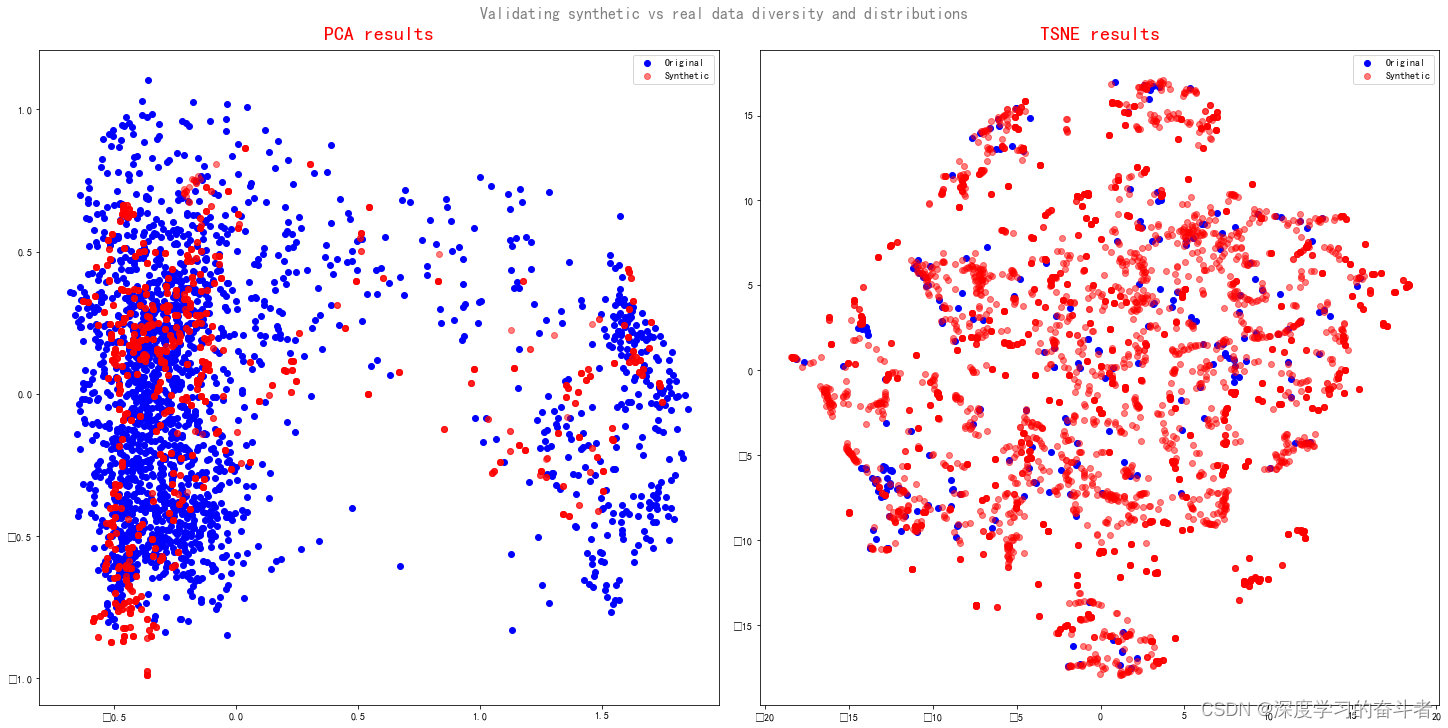
对8列数据,随机选出每列的24个连续的点,真实值与生成的数据对比:

2.利用LSTM进行预测
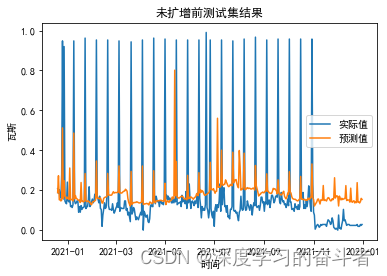
将原始数据集的最后一半(236行,也就是263个样本作为测试集),前面一半单独作为训练集,模型经训练后,对测试集的效果如下:
RMSE: 0.18512594640992197
MAE: 0.11461186704684799
MSE: 0.0342716160341693

将原始数据集的最后一半(236行,也就是263个样本作为测试集),前面一半和扩增后的数据一起组成训练集,模型经训练后,对测试集的效果如下:
RMSE: 0.1454103476829004
MAE: 0.05941093629294589
MSE: 0.02114416921326198

将原始数据集的最后80%(378行,也就是378个样本作为测试集),前面20%(95个样本)单独作为训练集,模型经训练后,对测试集的效果如下:
RMSE: 0.18795273726595538
MAE: 0.12856747175336741
MSE: 0.03532623144576525
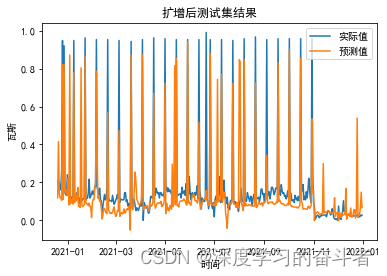
将原始数据集的最后80%(378行,也就是378个样本作为测试集),前面20%(95个样本)和扩增数据一起作为训练集,模型经训练后,对测试集的效果如下:
RMSE: 0.13263138712145212
MAE: 0.07024818880211464
MSE: 0.017591084849760494
对项目感兴趣的,可以关注最后一行
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from tensorflow import function, GradientTape, sqrt, abs, reduce_mean, ones_like, zeros_like, convert_to_tensor,float32
from tensorflow import data as tfdata
from tensorflow import config as tfconfig
#代码和数据集的压缩包:https://mbd.pub/o/bread/mbd-ZpaXmJdv只需要数据集的可以关注下方最后一行
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from tensorflow import function, GradientTape, sqrt, abs, reduce_mean, ones_like, zeros_like, convert_to_tensor,float32
from tensorflow import data as tfdata
from tensorflow import config as tfconfig
#数据集:https://mbd.pub/o/bread/ZZ6Zlp9r















 743
743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











