









代码是在github上找的学习使用,以下是我学习深度学习时的一个笔记,将cpu上跑的手写数字识别的代码改为gpu上运行,以提高运行效率。
Mnist数据集官网:数据集下载
有一篇博主的文章总结的比较好:如何在GPU上运行pytorch程序
一、方法
1、开始前声明
在代码前加上
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
有多个GPU可选择具体GPU进行调用,使用第几块就选择第几块。
import os
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"]='1'
2、将模型放到GPU上
在实体化网络的时候使用
net=Net()
net.to(device)
3、将数据和标签放到GPU上
inputs, labels = data[0].to(device), data[1].to(device)
或者
inputs, labels= inputs.to(device),labels.to(device)
做完以上三步,代码应该就能正常在GPU上训练了。
二、CPU训练
import torch
from torchvision import datasets, transforms
import torch.nn as nn
import torch.optim as optim
from datetime import datetime
class Config:
batch_size = 64
epoch = 10
momentum = 0.9
alpha = 1e-3
print_per_step = 100
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 3*3的卷积
self.conv1 = nn.Sequential(
nn.Conv2d(1, 32, 3, 1, 2), #kernel_size卷积核大小 stride卷积步长 padding特征图填充
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2) #2*2的最大池化层
)
self.fc1 = nn.Sequential(
nn.Linear(64 * 5 * 5, 128),
nn.BatchNorm1d(128),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(128, 64),
nn.BatchNorm1d(64), # 加快收敛速度的方法(注:批标准化一般放在全连接层后面,激活函数层的前面)
nn.ReLU()
)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
class TrainProcess:
def __init__(self):
self.train, self.test = self.load_data()
self.net = LeNet()
self.criterion = nn.CrossEntropyLoss() # 定义损失函数
self.optimizer = optim.SGD(self.net.parameters(), lr=Config.alpha, momentum=Config.momentum)
@staticmethod
def load_data():
print("Loading Data......")
"""加载MNIST数据集,本地数据不存在会自动下载"""
train_data = datasets.MNIST(root='./data/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_data = datasets.MNIST(root='./data/',
train=False,
transform=transforms.ToTensor())
# 返回一个数据迭代器
# shuffle:是否打乱顺序
train_loader = torch.utils.data.DataLoader(dataset=train_data,
batch_size=Config.batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_data,
batch_size=Config.batch_size,
shuffle=False)
return train_loader, test_loader
def train_step(self):
steps = 0
start_time = datetime.now()
print("Training & Evaluating......")
for epoch in range(Config.epoch):
print("Epoch {:3}".format(epoch + 1))
for data, label in self.train:
data, label = Variable(data.cpu()), Variable(label.cpu())
self.optimizer.zero_grad() # 将梯度归零
outputs = self.net(data) # 将数据传入网络进行前向运算
loss = self.criterion(outputs, label) # 得到损失函数
loss.backward() # 反向传播
self.optimizer.step() # 通过梯度做一步参数更新
# 每100次打印一次结果
if steps % Config.print_per_step == 0:
_, predicted = torch.max(outputs, 1)
correct = int(sum(predicted == label))
accuracy = correct / Config.batch_size # 计算准确率
end_time = datetime.now()
time_diff = (end_time - start_time).seconds
time_usage = '{:3}m{:3}s'.format(int(time_diff / 60), time_diff % 60)
msg = "Step {:5}, Loss:{:6.2f}, Accuracy:{:8.2%}, Time usage:{:9}."
print(msg.format(steps, loss, accuracy, time_usage))
steps += 1
test_loss = 0.
test_correct = 0
for data, label in self.test:
data, label = Variable(data.cpu()), Variable(label.cpu())
outputs = self.net(data)
loss = self.criterion(outputs, label)
test_loss += loss * Config.batch_size
_, predicted = torch.max(outputs, 1)
correct = int(sum(predicted == label))
test_correct += correct
accuracy = test_correct / len(self.test.dataset)
loss = test_loss / len(self.test.dataset)
print("Test Loss: {:5.2f}, Accuracy: {:6.2%}".format(loss, accuracy))
end_time = datetime.now()
time_diff = (end_time - start_time).seconds
print("Time Usage: {:5.2f} mins.".format(time_diff / 60.))
if __name__ == "__main__":
p = TrainProcess()
p.train_step()
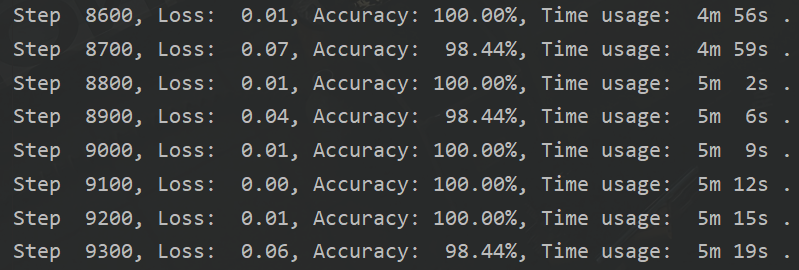
三、GPU训练
import torch
from torchvision import datasets, transforms
import torch.nn as nn
import torch.optim as optim
from datetime import datetime
# 添加
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 添加
class Config:
batch_size = 64
epoch = 10
momentum = 0.9
alpha = 1e-3
print_per_step = 100
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 3*3的卷积
self.conv1 = nn.Sequential(
nn.Conv2d(1, 32, 3, 1, 2), #kernel_size卷积核大小 stride卷积步长 padding特征图填充
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2) #2*2的最大池化层
)
self.fc1 = nn.Sequential(
nn.Linear(64 * 5 * 5, 128),
nn.BatchNorm1d(128),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(128, 64),
nn.BatchNorm1d(64), # 加快收敛速度的方法(注:批标准化一般放在全连接层后面,激活函数层的前面)
nn.ReLU()
)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
class TrainProcess:
def __init__(self):
self.train, self.test = self.load_data()
#修改
self.net = LeNet().to(device)
#修改
self.criterion = nn.CrossEntropyLoss() # 定义损失函数
self.optimizer = optim.SGD(self.net.parameters(), lr=Config.alpha, momentum=Config.momentum)
@staticmethod
def load_data():
print("Loading Data......")
"""加载MNIST数据集,本地数据不存在会自动下载"""
train_data = datasets.MNIST(root='./data/',
train=True,
transform=transforms.ToTensor(),
download=True)
test_data = datasets.MNIST(root='./data/',
train=False,
transform=transforms.ToTensor())
# 返回一个数据迭代器
# shuffle:是否打乱顺序
train_loader = torch.utils.data.DataLoader(dataset=train_data,
batch_size=Config.batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_data,
batch_size=Config.batch_size,
shuffle=False)
return train_loader, test_loader
def train_step(self):
steps = 0
start_time = datetime.now()
print("Training & Evaluating......")
for epoch in range(Config.epoch):
print("Epoch {:3}".format(epoch + 1))
for data, label in self.train:
# 修改
data, label = data.to(device),label.to(device)
# 修改
self.optimizer.zero_grad() # 将梯度归零
outputs = self.net(data) # 将数据传入网络进行前向运算
loss = self.criterion(outputs, label) # 得到损失函数
loss.backward() # 反向传播
self.optimizer.step() # 通过梯度做一步参数更新
# 每100次打印一次结果
if steps % Config.print_per_step == 0:
_, predicted = torch.max(outputs, 1)
correct = int(sum(predicted == label))
accuracy = correct / Config.batch_size # 计算准确率
end_time = datetime.now()
time_diff = (end_time - start_time).seconds
time_usage = '{:3}m{:3}s'.format(int(time_diff / 60), time_diff % 60)
msg = "Step {:5}, Loss:{:6.2f}, Accuracy:{:8.2%}, Time usage:{:9}."
print(msg.format(steps, loss, accuracy, time_usage))
steps += 1
test_loss = 0.
test_correct = 0
for data, label in self.test:
# 修改
data, label = data.to(device),label.to(device)
# 修改
outputs = self.net(data)
loss = self.criterion(outputs, label)
test_loss += loss * Config.batch_size
_, predicted = torch.max(outputs, 1)
correct = int(sum(predicted == label))
test_correct += correct
accuracy = test_correct / len(self.test.dataset)
loss = test_loss / len(self.test.dataset)
print("Test Loss: {:5.2f}, Accuracy: {:6.2%}".format(loss, accuracy))
end_time = datetime.now()
time_diff = (end_time - start_time).seconds
print("Time Usage: {:5.2f} mins.".format(time_diff / 60.))
if __name__ == "__main__":
p = TrainProcess()
p.train_step()
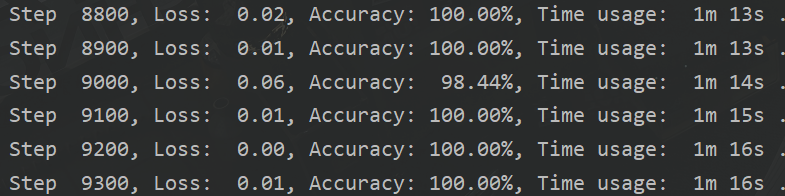
感受下时间的差距















 5083
5083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









