






随着人工智能技术的飞速发展,将大型语言模型(LLM)部署到生产环节变得日益复杂。特别是在AI和基于LLM的API需求激增的当下,这一挑战尤为突出。Gartner的预测显示,到2026年,由AI和LLM工具驱动的API需求将激增超过30%,这无疑强调了高效模型管理的重要性。
在这方面,企业面临的一个主要难题是如何在不同模型间灵活切换,比如GPT-4和Anthropic。每个模型都有其独特的API接口,这意味着需要对应用程序代码进行大量的修改,既耗时又影响效率。
LLM网关/AI网关提供了一个解决方案。通过统一的API接入,它们允许我们在不同模型间无缝切换,无需改动底层代码。这些网关使得企业能够轻松集成和切换LLM,从而在AI部署中实现最大的灵活性和效率。
本文将介绍一下2024年最热门的10款LLM网关。这些网关不仅为企业提供了一个统一的平台来管理和部署LLM,还极大地简化了AI集成的复杂性,让企业在AI的浪潮中更加游刃有余。
01. APIPark
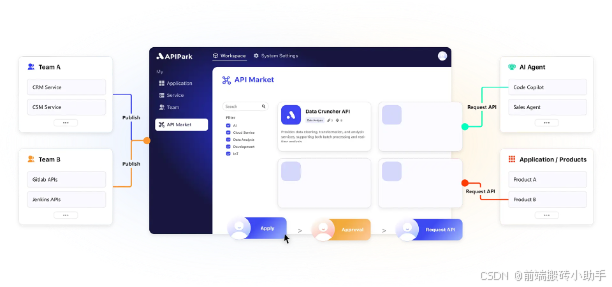
APIPark是一款高性能的开源LLM网关和API开发平台,旨在帮助开发者和企业轻松管理、集成及部署 AI 服务,基于 Apache 2.0 协议开源,支持免费商用。
APIPark 极大地简化了调用大型语言模型的流程,无需编写代码,即可快速连接100+多款AI大语言模型。同时,它提供了有效的安全保护,防止企业敏感数据的泄露,帮助企业快速、安全地应用 AI 技术。
优势:
APIPark 除了支持快速对接100+AI大模型外,还支持将Prompt 与大模型的API封装成API接口,发布到团队内外部进行共享使用,并且支持LLM调用的负载均衡,实现多个LLM无缝切换,保障业务的连续性。
相关链接
02. Portkey
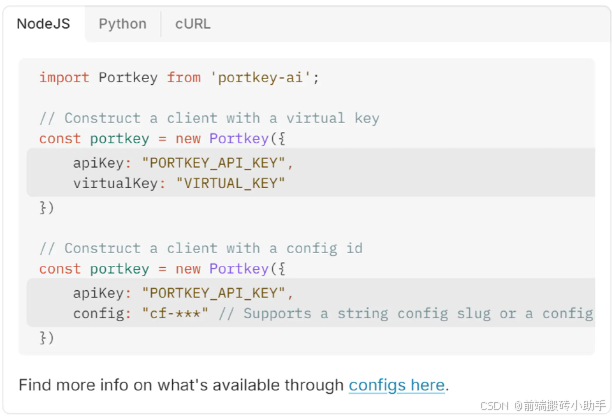
Portkey AI Gateway 是一个强大的平台,旨在通过统一的 API 简化和优化对多种大型语言模型(LLMs)的访问。该平台提供了增强的监控、安全性和成本管理功能,非常适合希望高效管理多个提供商的 LLM 的企业使用。
相关链接
03.Kong
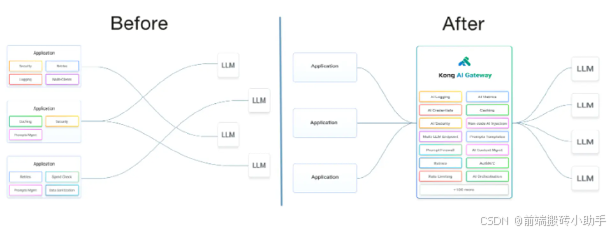
Kong Gateway 的广泛 API 管理功能以及基于插件的可扩展性,使其成为 AI 特定 API 管理和治理的理想选择。
AI Gateway 提供了一个标准化的 API 层,即使 AI 提供商之间缺乏统一的 API 规范,也能让客户通过统一的代码库访问多个 AI 服务。它还通过凭证管理、使用监控、治理和提示工程等功能提升了 AI 服务管理的效率。开发者可以利用无代码 AI 插件来丰富现有的 API 流量,从而无缝增强应用功能。
优势
AI Gateway 功能是Kong 网关的一个专门插件,采用与其他 Kong 网关插件相同的模式。Kong 用户无需自定义代码或使用陌生工具,就可以快速构建一个强大的 AI 管理平台。
相关链接
04.Cloudfare
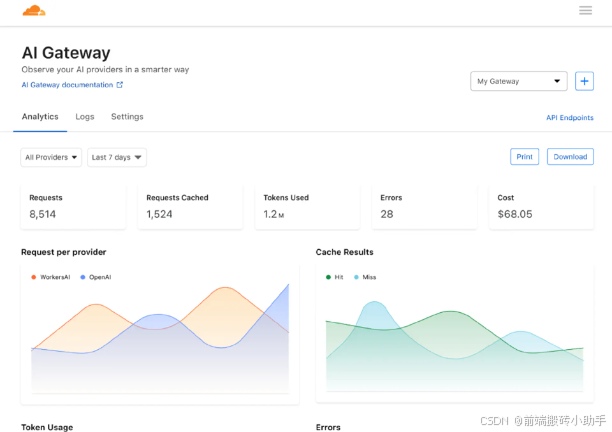
Cloudflare AI Gateway 充当您的应用程序与其交互的 AI API(例如 OpenAI)之间的中介。它通过缓存响应、管理和重试请求以及提供详细的分析来监控和跟踪使用情况,帮助优化工作流程。
优势
通过处理这些常见的 AI 应用任务,AI Gateway 减轻了工程工作负担,让您能够专注于构建应用程序本身。
相关链接
05.Gloo Gateway
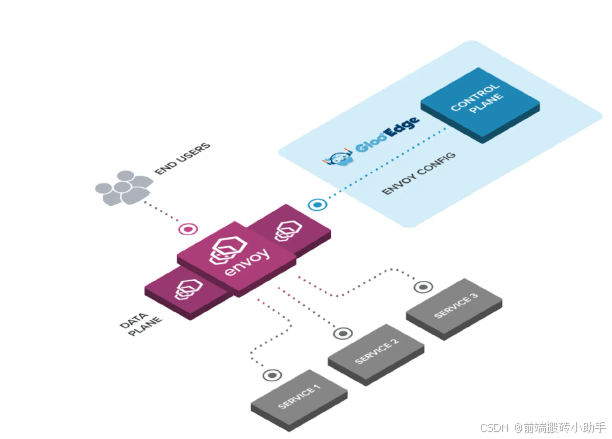
Gloo Gateway 是一个强大的、原生 Kubernetes 的入口控制器和下一代 API 网关。它以其先进的功能级路由、对传统应用程序、微服务和无服务器架构的支持以及强大的服务发现能力而脱颖而出。
优势
凭借众多功能和与顶级开源项目的无缝集成,Gloo Gateway 专为支持混合应用程序而设计,能够使不同的技术、架构、协议和云环境协同工作。
相关链接
06.Aisera
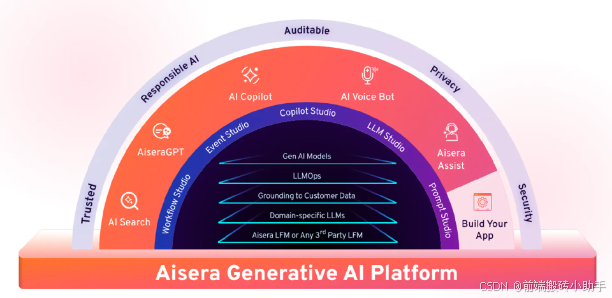
Aisera 的 LLM 网关将任何大语言模型 (LLM) 无缝集成到其 AI 服务体验平台中,通过 AiseraGPT 和生成式 AI 将其转变为生成式 AI 应用或 AI 助手。
优势
这使得平台能够深入理解特定领域的细微差别,并通过 AI 驱动的行动工作流自动化复杂任务,将聊天机器人转变为面向行动的机器人。
相关链接
Demo https://aisera.com/product-demos/
文档:https://content.aisera.com/white-papers
07.LiteLLM
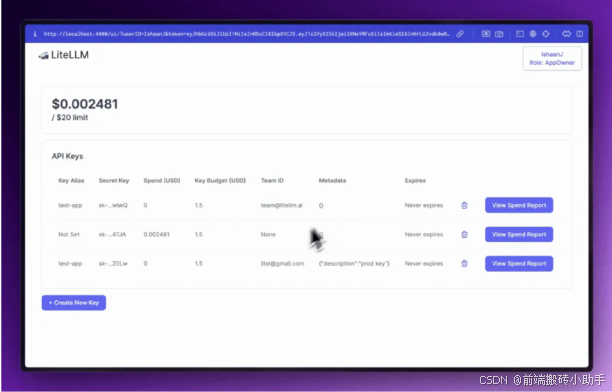
LiteLLM(全称为“轻量级大语言模型库”)通过充当各种先进 AI 模型的多功能网关,简化了高级 AI 模型的使用。
优势
它提供了统一的接口,使您能够轻松访问和使用不同的 AI 模型,进行写作、理解和图像创作等任务,无论模型提供方是谁。
需要考虑的事项
LiteLLM 与领先的提供商如 OpenAI、Azure、Cohere 和 Hugging Face 无缝集成,为您的项目提供简化且一致的 AI 使用体验。
相关链接
文档:https://docs.litellm.ai/docs/
社区: https://discord.com/invite/wuPM9dRgDw
08.IBM API Connect
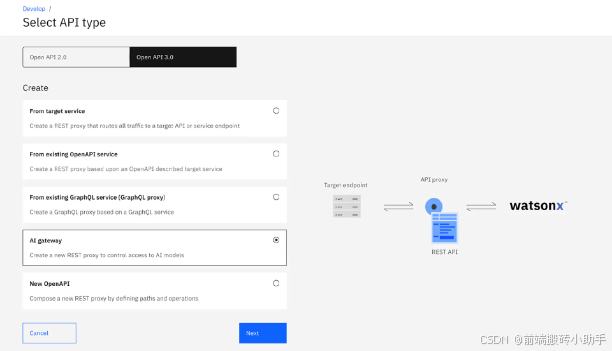
IBM API Connect 中的 AI 网关是一项功能,允许组织安全地将 AI 驱动的 API 集成到其应用程序中。该网关促进了您的应用程序与 AI 服务之间的无缝连接,无论这些服务是在组织内部还是外部。
需要考虑的事项
您可以通过限制请求速率和缓存 AI 响应来应对意外或过高的 AI 服务费用。内置的分析和仪表板提供了企业范围内使用 AI API 的可视化。
通过将 LLM API 流量通过 AI 网关路由,您可以集中管理 AI 服务,实施政策、数据加密、敏感数据屏蔽、访问控制和审计追踪,所有这些都支持您的合规性要求。
相关链接
文档: https://www.ibm.com/docs/api-connect/saas
09.LM Studio
LM Studio 是一个平台,旨在帮助您通过用户友好的界面轻松微调和部署大语言模型(LLM)。它简化了定制 LLM 的过程,即使您没有深入的 AI 或机器学习专业知识,也能轻松使用。
优势
使用 LM Studio,您可以利用预训练模型并将其调整到特定的使用场景或领域,高效地部署它们,并通过直观的工具和仪表板管理其性能。
相关链接
GitHub:https://github.com/lmstudio-ai
10.Tyk
TYK 是一个开源的 API 管理平台,提供设计、部署和管理 API 的工具,确保安全高效。
优势
TYK 利用 AI 进行 API 设计,集成 AI 技术以简化和自动化 API 开发过程。以下是它们如何使用 AI 的方式:
- 自动化 API 生成:AI 可以分析现有的数据模型、文档,甚至是实时流量,自动建议或生成 API 端点,从而减少设计 API 时所需的手动工作。
- 智能推荐:AI 提供 API 设计最佳实践的推荐,帮助开发人员优化 API 的结构、安全性和性能。
- 增强测试:AI 可以用来模拟各种场景,更有效地测试 API 响应,识别潜在问题,并在部署前优化 API 的可靠性和性能。
- API 文档:AI 可以根据设计的 API 协助生成全面的 API 文档,确保文档一致、最新,并与 API 的实际行为保持一致。
- 设计优化:AI 工具可以通过分析使用模式,建议改进 API 设计,帮助开发人员创建更高效、用户友好的 API。
需要考虑的事项
这些 AI 驱动的功能帮助 TYK 用户加速 API 开发过程,提高设计质量,减少错误,从而最终实现更强大、更可扩展的 API。
相关链接
GitHub:https://github.com/TykTechnologies/tyk
写在最后
在选择 LLM 网关时,应根据具体需求和运营规模做出决策。如果您是初创公司,正在尝试集成 LLM,且需要快速且经济高效的解决方案,可以优先选择开源或提供基础功能免费的平台,这些通常足以满足基本需求。
当进入生产阶段并需要更强大的功能,例如增强的安全性或本地部署选项,适合支持扩展的解决方案将更为理想。这些工具能够在保护数据隐私的同时,提供灵活的管理和高效的运行。
对于大型企业,频繁的 LLM 集成需求使可靠性和全面的管理能力至关重要。在这种情况下,支持企业级管理和高稳定性的网关方案是最佳选择。
如果您的团队关注高级功能,例如提示优化和模型微调,则应选择能够支持更复杂配置的网关工具,以帮助充分发挥 AI 项目的潜力。

















 1093
1093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









