









下一篇:NLP篇【01】tfidf与bm25介绍与对比
目录
一、NLP篇概述
众所周知,NLP的基础是词向量。什么是词向量?其实就是用数学中的向量表示文字。苹果可以用向量[1,2,3]表示,所以向量[1,2,3]其实是机器可以识别的苹果(就好比apple是美国人可以识别的苹果),但在自然语言处理中,我们不可能人为给每个词定义对应的向量表示,事实上,每个词对应的向量表示是通过算法来实现的。如word2vec、glove、fasttext,elmo,gpt以及现在火热的bert算法,都可以实现自动训练获取词向量。因为word2vec是最早训练词向量的算法,所以现在常常用word2vec代表词向量。这些算法后面会分别介绍它们的原理以及实现代码,所以这里就不详述了。
利用上述Word2vec算法,可以把文字表示成词向量,然后再输入到机器中,在这个基础上,NLP可以做的任务就可多了,有:文本分类,命名实体识别(NER),信息抽取,文本匹配,机器翻译,知识图谱等等。后面也会利用算法实现这些任务,代码也会一 一上传到github上,最后还会做一个前端页面来展示这些任务的结果。
小结一下:这里我简单介绍了一下NLP的基础词向量以及NLP主要的任务,然后交代了一下,后续博客将要更新的内容。NLP的发展历程或者想看更详细的NLP的综述,可以自行百度查阅。
二、电商篇——算法在电商中的应用
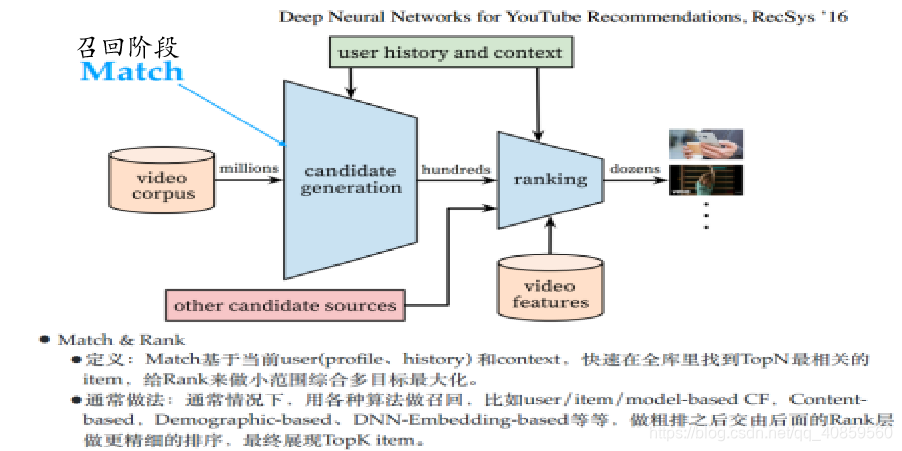
目前,算法在电商应用场景主要有:搜索排序,列表页排序和推荐排序。三种场景,是有很多共同点的(如上图,都遵循先召回再排序,原谅我的懒,用了一张视频推荐的图),但又有很多不同的地方,就好比游戏多塔,lol和王者之前的关系,想必玩了lol后再玩王者上手是很快的。同样做了搜索排序后再去做列表页或推荐排序上手也会很快的。下面我就分别介绍一下三者:
搜索排序:
场景就是用户输入query获取结果,如下图:
搜索的召回方法有:关键词匹配(bm25),语义检索,标签召回等等。搜索排序阶段一般采用双塔模型,一端是输出用户端embedings,另一端输出商品端embedings,最后求cos值,根据这个值大小排序展示搜索结果。这部分内容后续博客还会详细介绍召回方法、双塔模型及其实现。
列表页排序
场景就是用户点击列表获取结果,如下图:

推荐排序
推荐排序的场景大家也了解的比较多,如买了这个商品的人还买了,猜你喜欢等等,推荐主要是根据你的历史行为来预估你的喜好。这种预估方法有协同过滤,矩阵分解以及击预估模型,常用的点击预估模型有essm,din等等。
列表页排序、推荐排序与搜索排序最主要的不同是召回,搜索召回可以根据query召回,后面的排序阶段,三者使用的模型是相同的。因为我自己是做搜索排序的,所以后续博客会系统的介绍搜索的召回、粗排和精排,主要涉及到的模型如:dssm,essm,din等也会介绍其原理和实现细节,以及我们实际应用时的一些调优小trick。
三、NLP遇见电商
搜索推荐中一个重要的特征就是query,利用这个query特征我们可以做很多事情,如:
1、把query分词后输入到词向量模型(词向量模型有word2vec,fastext,lstm,bert,qanet,elmo等)获得向量特征,再输入到其他模型
2、可以先让query经过一个分类器,这个分类器会预测这个query是想找哪个属性或类目,然后根据属性或类目做召回,也可以放在重排层做类目或属性打压
3、可以根据用户对商品的评论,训练一个打标签的模型,然后根据query做一个标签召回
四、内容预告
后续博客将会更新以下内容:
1、NLP内容
传统算法tfidf,bm25(生产中,还是会常使用这些轻量级的算法,比如做相似度召回)
词向量算法:word2vec,fasttext,glove,elmo,gpt和bert
具体NLP任务:文本分类,命名实体识别(NER),信息抽取,文本匹配,机器翻译,知识图谱
2、电商实战
电商中的搜索推荐:召回、粗排、精排,其中涉及到的模型dssm,essm,din,dien
注:暂时想到的就这些了
能力有限,可能会有理解错误,谢谢指出!















 5820
5820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









