







知识图谱的技术与应用简短介绍
为了让机器能够理解文本背后的含义,我们需要对可描述的事物(实体)进行建模,填充它的属性,拓展它和其他事物的联系,即,构建机器的先验知识。
使用场景:分析个体间关系
什么是知识图谱?
语义网络(Semantic Network): 上个世纪五六十年代提出的一种知识表示形式,相互连接的节点和边组成,节点表示概念或者对象,边表示他们之间的关系。
知识图谱(Knowledge Graph),由Google公司在2012年提出,
从学术角度定义:“语义网络(Semantic Network)的知识库”;从实际应用的角度,可理解成多关系图(Multi-relational Graph)。
图是由节点(Vertex) 和 边(Edge)来构成,但这些图通常只包含一种类型的节点和边。多关系图一般包含多种类型的节点和多种类型的边。
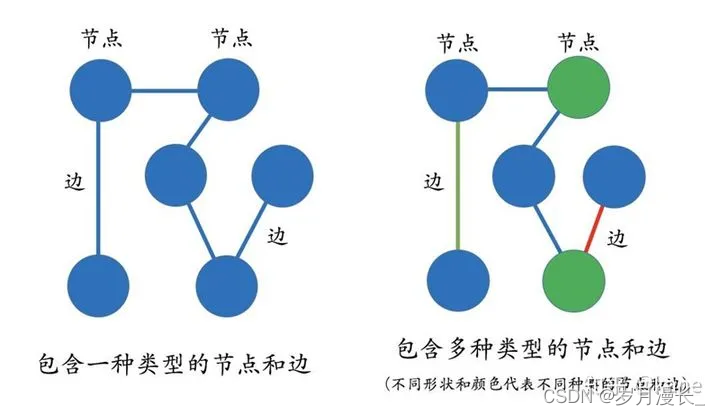 用实体(Entity)来表达图里的“节点”、用关系(Relation)来表达图里的“边”。实体指的是现实世界中的事物,比如人、地名、概念、药物、公司等;关系则用来表达不同实体之间的某种联系,比如人-“居住在”-北、张三和李四是“朋友”、逻辑回归是深度学习的“先导知识”等等。
用实体(Entity)来表达图里的“节点”、用关系(Relation)来表达图里的“边”。实体指的是现实世界中的事物,比如人、地名、概念、药物、公司等;关系则用来表达不同实体之间的某种联系,比如人-“居住在”-北、张三和李四是“朋友”、逻辑回归是深度学习的“先导知识”等等。
现实世界中的很多场景非常适合用知识图谱来表达。
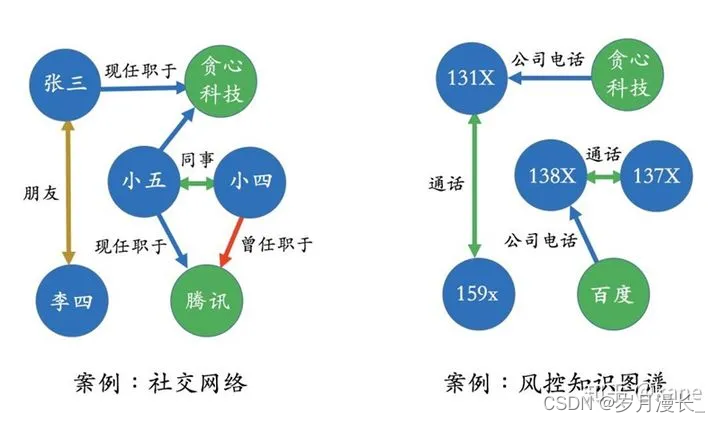
知识图谱的表示
在现实世界中,实体和关系也会拥有各自的属性,比如人可以有“姓名”和“年龄”。当一个知识图谱拥有属性时,我们可以用属性图(Property Graph)来表示。
例,李明和李飞是父子关系,并且李明拥有一个138开头的电话号,这个电话号开通时间是2018年,其中2018年就可以作为关系的属性。类似的,李明本人也带有一些属性值比如年龄为25岁、职位是总经理等。
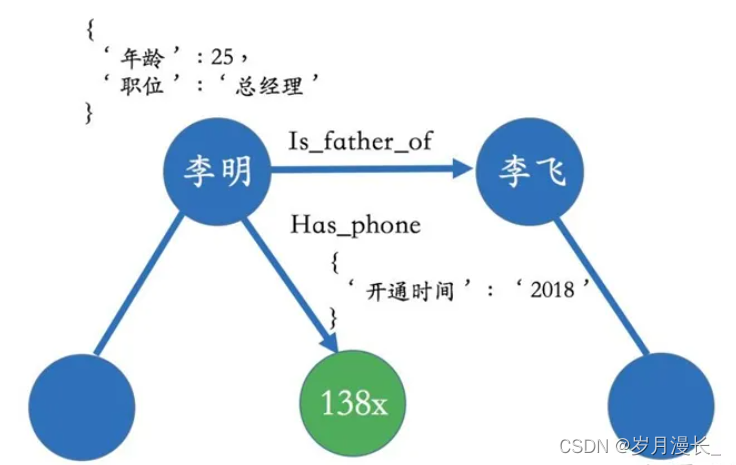
这种属性图的表达很贴近现实生活中的场景,也可以很好地描述业务中所包含的逻辑。除了属性图,知识图谱也可以用RDF来表示,它是由很多的三元组(Triples)来组成。RDF在设计上的主要特点是易于发布和分享数据,但不支持实体或关系拥有属性,如果非要加上属性,则在设计上需要做一些修改。
RDF:学术界
图数据库:工业界
知识抽取(知识图谱构建的前提)
知识图谱的构建是后续应用的基础,而且构建的前提是需要把数据从不同的数据源中抽取出来。
对于垂直领域的知识图谱来说,它们的数据源主要来自两种渠道:
- 业务本身的数据,这部分数据通常包含在公司内的数据库表并以结构化的方式存储;一般只需要简单预处理即可以作为后续AI系统的输入。
- 网络上公开、抓取的数据,这些数据通常是以网页的形式存在所以是非结构化的数据;一般需要借助于自然语言处理等技术来提取出结构化信息。(难点)
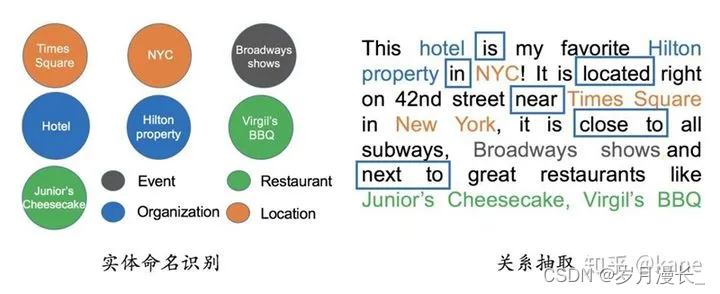
左边是一段非结构化的英文文本,右边是从这些文本中抽取出来的实体和关系。在构建类似的图谱过程当中,主要涉及以下几个方面的自然语言处理技术:
a. 实体命名识别(Name Entity Recognition)
b. 关系抽取(Relation Extraction)
c. 实体统一(Entity Resolution)
d. 指代消解(Coreference Resolution)
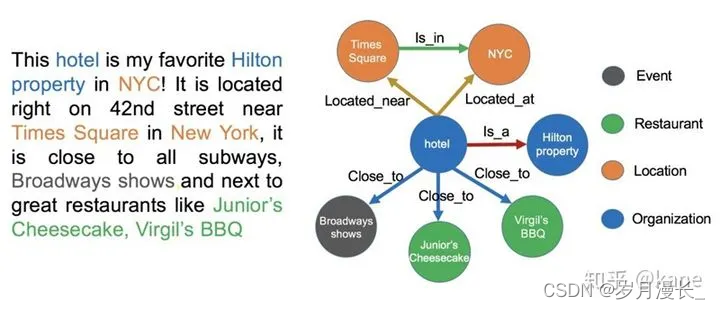
实体命名识别,就是从文本里提取出实体并对每个实体做分类/打标签:比如从上述文本里,我们可以提取出实体-“NYC”,并标记实体类型为 “Location”;我们也可以从中提取出“Virgil’s BBQ”,并标记实体类型为“Restarant”。
关系抽取技术:把实体间的关系从文本中提取出来,比如实体“hotel”和“Hilton property”之间的关系为“in”;“hotel”和“Time Square”的关系为“near”等等。
在实体命名识别和关系抽取过程中,有两个比较棘手的问题:
一个是实体统一,也就是说有些实体写法上不一样,但其实是指向同一个实体。比如“NYC”和“New York”表面上是不同的字符串,但其实指的都是纽约这个城市,需要合并。实体统一不仅可以减少实体的种类,也可以降低图谱的稀疏性(Sparsity);
另一个问题是指代消解,也是文本中出现的“it”, “he”, “she”这些词到底指向哪个实体,比如在本文里两个被标记出来的“it”都指向“hotel”这个实体。

知识图谱的存储
知识图谱主要有两种存储方式:
- 基于RDF的存储
- 基于图数据库的存储

RDF一个重要的设计原则是数据的易发布以及共享,图数据库则把重点放在了高效的图查询和搜索上;其次,RDF以三元组的方式来存储数据而且不包含属性信息,但图数据库一般以属性图为基本的表示形式,所以实体和关系可以包含属性,这就意味着更容易表达现实的业务场景。
2018年上半年,图数据库仍然是增长最快的存储系统。关系型数据库的增长基本保持在一个稳定的水平。
常用的图数据库系统:Neo4j系统(不支持准分布式);OrientDB和JanusGraph(原Titan)(支持分布式)


















 5203
5203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











