







任何能够衡量模型预测出来的值h(θ)与真实值y之间的差异的函数都可以叫做代价函数C(θ)。简单理解就是用于评估回归方程中的误差大小的函数。
在前面的文章中梳理了什么是机器学习以及机器学习中的监督学习与非监督学习的概念区别,在接下来的课程中就开始涉及到众多算法的学习。
机器学习的主要任务是分类和回归。分类是将实例数据划分到合适的分类中。机器学习的另一项任务是回归,它主要用于预测数值型数据。在吴恩达老师的机器学习课程中,首先讲到的便是回归-数据拟合曲线。
与此同时便引出了代价函数(Cost Function)这一概念。所谓代价函数,简单理解就是用于评估回归方程中的误差大小的函数。
机器学习中要学习大量的算法,代价函数在机器学习中的每一种算法中都很重要,因为训练模型的过程就是优化代价函数的过程。代价函数能帮我们找到数据的最佳拟合直线
代价函数详细介绍
1、定义:任何能够衡量模型预测出来的值h(θ)与真实值y之间的差异的函数都可以叫做代价函数C(θ)。如果有多个样本,则可以将所有代价函数的取值求均值,记做J(θ)。因此很容易就可以得出以下关于代价函数的性质:
- 对于每种算法来讲,代价函数不是唯一的。
- 代价函数是参数θ的函数。
- 总的代价函数J(θ)可以用来评价模型的好坏,代价函数越小说明模型和参数越符合训练样本(X,Y)
- J(θ)是一个标量
在吴恩达老师讲解的课程中以房价为例,所得到的预测模型为:
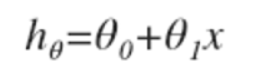
其中,θ0 和 θ1 之类这些 θi ,称为模型参数,接下来要讲的就是如何选择这两个参数值。使用不同的θi ,我们会得到不同的假设函数。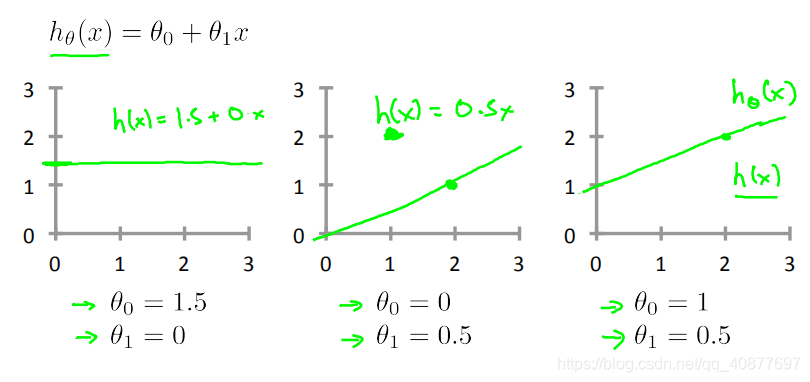
在此案例中我们要做的就是得出 θ0 和 θ1 这两个参数的值,来让假设函数表示的直线尽量地与这些数据点很好的拟合。那么我们如何得出 θ0 和 θ1 的值,来使它很好地拟合数据的呢?
我们的想法是,输入 x 时,我们要确定参数θ0 和 θ1 的值,以使我们的预测值 h(x) ,最接近该样本(x)对应的 y 值。训练集中有一定数量的样本, x 表示某一所房子,我们也知道这所房子的实际价格。所以,我们要选择参数值,尽量使得在训练集中给出的 x 值,能准确地预测 y 的值。
在线性回归中,我们要解决的其实是最小化问题。在这里,即希望误差h(x) - y达到最小,此时(h(x) - y)的平方也达到了最小值。模型所预测的值与训练集中实际值之间的差距(下图中蓝线所指)就是建模误差(modeling error)。
我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数。即:
其中,用符号(x(i),y(i))代表第i个样本,我们需要对所有训练样本的建模误差平方进行求和。此时的输入是x(i),即第i个房子的面积。m是训练集的样本容量(有多少个样本,m就是多少)。
为了尽量减少平均误差,我们在前面乘上一个因子1/m,为了在数学上表达的更简单直白一些,再除以2,经过这些处理,得到的应是相同的θ0 和 θ1 。为了使上述函数更明确,按照惯例,定义一个代价函数,如下,
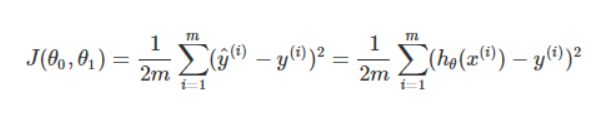
我们要做的就是求关于θ0 和 θ1 的J(θ0 , θ1 )的最小值,其中J(θ0 , θ1 )即代价函数(Cost Function)。代价函数也称为平方误差函数或平方误差代价函数。也还有其他的代价函数,但平方误差代价函数是处理回归问题时最常用的。
课程中的房价预测模型与代价函数的图像如下:
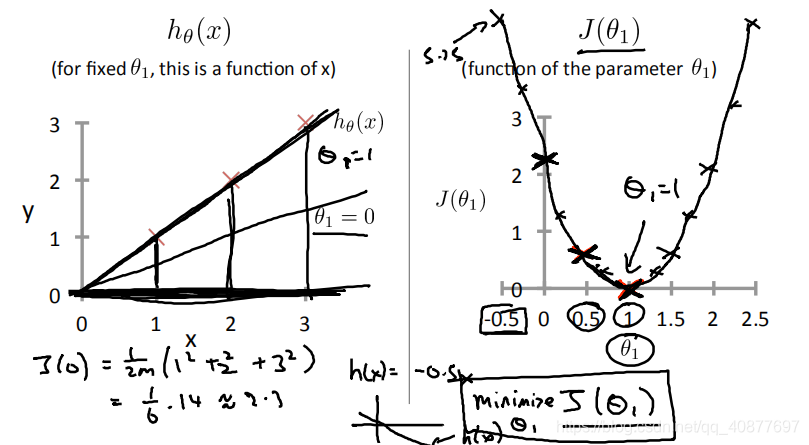
可以看出当代价函数取最小值时θ1取1,也就是h(x)中的斜率为1,由源数据可知此时数据的拟合效果最好,所得到的预测值最准确。















 698
698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









