







目录
1. 决策树(decision tree)的定义
决策树是一个类似于流程图的数结构:其中每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或者类分布。树的最顶层是根结点。
决策树通常包含3个步骤:特征选择、决策树的生成、和决策树的修建
分类决策树模型是一种描述对实例进行分类的树形结构。一棵决策树包含一个根节点,若干个内部节点和若干个叶节点,叶节点对应于决策结果。
- 树的递归思想
由根节点出发到内部结点的每一条路径构建一条规则,内部结点的特征对应着规则的条件,结点的类对应着规则的结论。
递归结束条件:
- 遍历完所有划分数据集的属性;
- 每个分支下的所有实例都具有相同的分类
2. 熵(entropy)的计算
- 信息量
一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常非常不确定的事情,或者是我们一无所知的事情,需要了解大量信息>>>>信息量的度量就等于不确定性的多少。 a i a_{i} ai信息的计算,已知道其概率。
I ( a i ) = − l o g P ( a i ) \boldsymbol{I(a_{i})}=-log P(a_{i}) I(ai)=−logP(ai) - 熵
它是表示随机变量不确定的度量,是对所有可能发生的事件产生的信息量的期望。
H ( x ) = − ∑ p ( x ) l o g P ( x ) H(x) =-\sum p(x) log P(x) H(x)=−∑p(x)logP(x)
3.联合熵
随机变量的值有多个的时候。p(x,y)表示联合概率,一起发生的概率。
H
(
X
,
Y
)
=
−
∑
p
(
x
,
y
)
l
o
g
p
(
x
,
y
)
H(X,Y) = -\sum p(x,y) log p(x,y)
H(X,Y)=−∑p(x,y)logp(x,y)
4.条件熵/噪声熵
已知条件下,事件的不确定性的大小。X条件下Y的信息熵
H
(
Y
∣
X
)
=
H
(
X
,
Y
)
−
H
(
X
)
=
−
∑
x
,
y
p
(
x
,
y
)
l
o
g
p
(
x
,
y
)
+
∑
x
p
(
x
)
l
o
g
p
(
x
)
=
−
∑
x
,
y
p
(
x
,
y
)
l
o
g
p
(
x
,
y
)
+
∑
[
∑
y
p
(
x
,
y
)
]
l
o
g
p
(
x
)
=
−
∑
x
,
y
p
(
x
,
y
)
l
o
g
p
(
x
,
y
)
+
∑
x
,
y
p
(
x
,
y
)
l
o
g
p
(
x
)
=
−
∑
x
,
y
p
(
x
,
y
)
l
o
g
p
(
x
,
y
)
p
(
x
)
=
−
∑
x
,
y
p
(
x
,
y
)
l
o
g
p
(
y
∣
x
)
\begin{aligned}H(Y|X)&=H(X,Y) -H(X)\\ &=-\sum_{x,y} p(x,y)log p(x,y) +\sum_{x} p(x) log p(x)\\ &=-\sum_{x,y} p(x,y)log p(x,y) +\sum[\sum_{y}p(x,y)]log p(x)\\ &=-\sum_{x,y} p(x,y)log p(x,y) + \sum_{x,y}p(x,y) log p(x)\\ &=-\sum_{x,y}p(x,y)log \frac{p(x,y)}{p(x)}\\ &=-\sum_{x,y}p(x,y)logp(y|x)\end{aligned}
H(Y∣X)=H(X,Y)−H(X)=−x,y∑p(x,y)logp(x,y)+x∑p(x)logp(x)=−x,y∑p(x,y)logp(x,y)+∑[y∑p(x,y)]logp(x)=−x,y∑p(x,y)logp(x,y)+x,y∑p(x,y)logp(x)=−x,y∑p(x,y)logp(x)p(x,y)=−x,y∑p(x,y)logp(y∣x)
H ( X , Y ) = − ∑ x , y p ( x , y ) l o g p ( y ∣ x ) = − ∑ x ∑ y p ( x , y ) l o g p ( y ∣ x ) = − ∑ x ∑ y p ( x ) p ( y ∣ x ) l o g p ( y ∣ x ) = − ∑ x p ( x ) ∑ y p ( y ∣ x ) l o g p ( y ∣ x ) = ∑ x p ( x ) [ − ∑ y p ( y ∣ x ) l o g p ( y ∣ x ) ] = ∑ x p ( x ) H ( Y ∣ X = x ) \begin{aligned}H(X,Y) &= -\sum_{x,y}p(x,y)log p(y|x)\\ &=-\sum_{x}\sum_{y}p(x,y)log p(y|x)\\ &=-\sum_{x}\sum_{y}p(x)p(y|x)log p(y|x)\\ &=-\sum_{x} p(x)\sum_{y}p(y|x)log p(y|x)\\ &=\sum_{x}p(x)[-\sum_{y}p(y|x)log p(y|x)]\\ &=\sum_{x}p(x)H(Y|X=x)\end{aligned} H(X,Y)=−x,y∑p(x,y)logp(y∣x)=−x∑y∑p(x,y)logp(y∣x)=−x∑y∑p(x)p(y∣x)logp(y∣x)=−x∑p(x)y∑p(y∣x)logp(y∣x)=x∑p(x)[−y∑p(y∣x)logp(y∣x)]=x∑p(x)H(Y∣X=x)
5.疑义度/损失熵
它也是条件熵,已知道Y的情况下,X的信息熵,公式证明和上面一样。
H
(
X
∣
Y
)
=
−
∑
x
,
y
p
(
x
,
y
)
l
o
g
p
(
x
∣
y
)
H(X|Y) = -\sum_{x,y} p(x,y)log{p(x|y)}
H(X∣Y)=−x,y∑p(x,y)logp(x∣y)
6.平均互信息
I
(
X
,
Y
)
=
H
(
X
)
−
H
(
X
∣
Y
)
=
H
(
Y
)
−
H
(
Y
∣
X
)
I(X,Y)=H(X)-H(X|Y)=H(Y)-H(Y|X)
I(X,Y)=H(X)−H(X∣Y)=H(Y)−H(Y∣X)
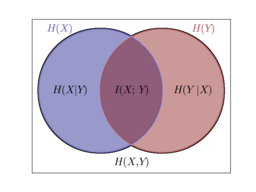
插入一张维恩图帮助理解上面各种熵的关系
7.交叉熵
现在有关于样本集的两个概率分布
p
(
x
)
p(x)
p(x) 和
q
(
x
)
q(x)
q(x),其中
p
(
x
)
p(x)
p(x) 为真实分布,
q
(
x
)
q(x)
q(x)非真实分布。
H
(
p
,
q
)
=
∑
x
p
(
x
)
l
o
g
1
q
(
x
)
H(p,q)=\sum_{x}p(x)log\frac{1}{q(x)}
H(p,q)=x∑p(x)logq(x)1
3. ID3算法
- 信息增益
"信息熵"是度量样本的不确定度,是度量样本集合纯度最常用的一种方法。
熵的计算(2为底熵的单位是bit,e为底是纳特):
H ( Y ) = − ∑ i = 1 n p ( y i ) l o g 2 p ( y i ) H(Y) = -\sum_{i=1}^{n}p(y_{i})log_{2}p(y_{i}) H(Y)=−i=1∑np(yi)log2p(yi)
信息增益定义
表示得知特征A的信息而使得类X的信息的不确定性减少的程度。
(A:代表数据集里面的特征,X:数据集里面标签的类别)
统计学里面的公式:
g ( D , A ) = H ( D ) − H ( D ∣ A ) g(D,A)=H(D)-H(D|A) g(D,A)=H(D)−H(D∣A)
西瓜书里面的公式:
G a i n ( D , a ) = E n t ( D ) − ∑ v = 1 V D v D E n t ( D v ) Gain(D,a)=Ent(D)-\sum_{v=1}^{V} \frac{D^{v}}{D}Ent(D^{v}) Gain(D,a)=Ent(D)−v=1∑VDDvEnt(Dv)
计算的方法就是按照西瓜书里面的,信息增益就是互信息,
计算一下使用的是统计学里面的数据

类别是“是”的有9个,类别是“否”的有6个。年龄是“青年”的有5个,年龄是“中年”的有5个,年龄是“老年”的有5个。
E n d ( D ) = − ( 9 15 l o g 9 15 + 6 15 l o g 6 15 ) = 0.971 End(D) =-(\frac{9}{15}log\frac{9}{15}+\frac{6}{15}log\frac{6}{15})=0.971 End(D)=−(159log159+156log156)=0.971
D 1 年 龄 是 青 年 , 其 中 “ 是 ” 有 2 个 , “ 否 ” 有 3 个 ; D 2 年 龄 是 中 年 , 其 中 “ 是 ” 有 3 个 , “ 否 ” 有 2 个 ; D 3 年 龄 是 老 年 , 其 中 “ 是 ” 有 4 个 , “ 否 ” 有 1 个 D^{1}年龄是青年,其中“是”有2个,“否”有3个;D^{2}年龄是中年,其中“是”有3个,“否”有2个;D^{3}年龄是老年,其中“是”有4个,“否”有1个 D1年龄是青年,其中“是”有2个,“否”有3个;D2年龄是中年,其中“是”有3个,“否”有2个;D3年龄是老年,其中“是”有4个,“否”有1个
E n t ( D 1 ) = − ( 2 5 l o g 2 5 + 3 5 l o g 3 5 ) = 0.971 E n t ( D 2 ) = − ( 3 5 l o g 3 5 + 2 5 l o g 2 5 ) = 0.971 E n t ( D 3 ) = − ( 4 5 l o g 4 5 + 1 5 l o g 1 5 ) = 0.722 \begin{aligned}Ent(D^{1})&=-(\frac{2}{5}log\frac{2}{5}+\frac{3}{5}log\frac{3}{5})=0.971\\ Ent(D^{2})&=-(\frac{3}{5}log\frac{3}{5}+\frac{2}{5}log\frac{2}{5})=0.971\\ Ent(D^{3})&=-(\frac{4}{5}log\frac{4}{5}+\frac{1}{5}log\frac{1}{5})=0.722 \end{aligned} Ent(D1)Ent(D2)Ent(D3)=−(52log52+53log53)=0.971=−(53log53+52log52)=0.971=−(54log54+51log51)=0.722
G a i n ( D , 年 龄 ) = E n t ( D ) − ∑ v = 1 3 D D v E n t ( D v ) = 0.971 − ( 5 15 × 0.971 + 5 15 × 0.971 + 5 15 x × 0.722 ) = 0.083 \begin{aligned}Gain(D,年龄)&=Ent(D)-\sum_{v=1}^{3}\frac{D}{D^{v}}Ent(D^{v})\\ &=0.971-(\frac{5}{15} \times 0.971+\frac{5}{15} \times 0.971+\frac{5}{15} x\times 0.722)\\ &=0.083 \end{aligned} Gain(D,年龄)=Ent(D)−v=1∑3DvDEnt(Dv)=0.971−(155×0.971+155×0.971+155x×0.722)=0.083
- ID3算法
ID3算法的核心是在决策树各个结点上应用信息增益准则选择特征
- ID3优点:
理论清晰、方法简单、学习能力较强。 - 缺点:
- ID3算法只有树的生成,所以该算法生成的树容易产生过拟合。
- 只能处理分类属性的数据,不能处理连续的数据
- ID3算法采用信息增益作为评价标准。信息增益的缺点是倾向于取值较多的特征,在有些情况下这类特征可能不会提供太多有价值的信息
4. C4.5
- 信息增益率
信息增益对可取数目较多的属性有所偏好,如果将ID也作为一个特征,那么它的信息增益为0.971,因为每一个ID对应一个,即每一个对应的 E n t ( D i d ) Ent(D^{id}) Ent(Did)熵为0,为了减少这种偏好带来的影响,可以使用“信息增益率”来选择最优划分的属性。
统计学:特征A对训练数据集D的信息增益比 g R ( D , A ) 定 义 其 为 信 息 增 益 g ( D , A ) 与 训 练 数 据 集 D 的 经 验 熵 H ( D ) 之 比 g_{R}(D,A)定义其为信息增益g(D,A)与训练数据集D的经验熵H(D)之比 gR(D,A)定义其为信息增益g(D,A)与训练数据集D的经验熵H(D)之比
g R ( D , A ) = g ( D , A ) H ( D ) g_{R}(D,A)=\frac{g(D,A)}{H(D)} gR(D,A)=H(D)g(D,A)
西瓜书:
G a i n r a t i o ( D , a ) = G a i n ( D , a ) I V ( a ) Gain_ratio(D,a)= \frac{Gain(D,a)}{IV(a)} Gainratio(D,a)=IV(a)Gain(D,a)
I V ( a ) = − ∑ v = 1 V D v D l o g D v D IV(a)=-\sum_{v=1}^{V}\frac{D^{v}}{D}log\frac{D^{v}}{D} IV(a)=−v=1∑VDDvlogDDv - C4.5算法
C4.5算法与ID3算法相似,C4.5使用的是信息增益比来选取特征。
- 优点:
- 解决偏向取值较多的属性的问题
- 可以处理连续型属性。
- 缺点:
- 对数据集进行多次的顺序扫描和排序,算法的效率低。
- C4.5算法处理连续值
- 需要连续属性离散化,最简单的策略采用二分法对连续属性进行处理,这就是C4.5算法采用的。
- 连续值处理方法:
给定数据集D和连续特征a,假定a出现了n个不同的值,将这n个值从小到大进行排序,取相邻的两个点的均值,作为划分点,这样的可以取n-1个划分点,计算哪个划分点的信息增益大。
5. CART
1. Gini指数
CART(Classification and Regression Tree, 分类和回归树)决策树是使用“基尼指数”来选择划分特征属性的。数据集D的纯度可以使用Gini值来度量:
G i n i ( D ) = ∑ k = 1 ∣ y ∣ ∑ k ′ ≠ k p k p k ′ = ∑ k = 1 y p k ( 1 − p k ) = 1 − ∑ k = 1 ∣ y ∣ p k 2 = 1 − ∑ k = 1 y ( ∣ C k ∣ ∣ D ∣ ) 2 \begin{aligned} Gini(D) &= \sum_{k=1}^{\left | y \right |}\sum_{{k}'\neq k}p_{k}p_{{k}'}\\ &= \sum_{k=1}^{y}p_{k}(1-p_{k})\\ &=1-\sum_{k=1}^{\left | y \right |}p_{k}^{2}\\ &=1- \sum_{k=1}^{y}(\frac{|C_{k}|}{|D|})^{2} \end{aligned} Gini(D)=k=1∑∣y∣k′=k∑pkpk′=k=1∑ypk(1−pk)=1−k=1∑∣y∣pk2=1−k=1∑y(∣D∣∣Ck∣)2
p
k
p_{k}
pk指样本属于第k类的概率,总共有y个类别,
C
k
C_{k}
Ck属于第k个类别的样本子集。
Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一样的概率。因此,GIni(D)越小,则数据集D的纯度越高。
属性a的基尼指数定义:
G
i
n
i
i
n
d
e
x
(
D
,
a
)
=
∑
v
=
1
V
∣
D
v
∣
∣
D
∣
G
i
n
i
(
D
v
)
Gini_index(D,a)=\sum_{v=1}^{V}\frac{|D^{v}|}{|D|}Gini(D^{v})
Giniindex(D,a)=v=1∑V∣D∣∣Dv∣Gini(Dv)
选择属性,基尼指数最小的属性作为划分属性,V表示分类
例子

计算基尼指数:
G
i
n
i
(
D
,
A
=
青
年
)
=
5
15
(
2
×
2
5
×
(
1
−
2
5
)
)
+
10
15
(
2
×
7
10
×
(
1
−
7
10
)
)
=
0.44
Gini(D,A=青年)=\frac{5}{15}(2 \times \frac{2}{5}\times (1-\frac{2}{5}))+\frac{10}{15}(2 \times\frac{7}{10}\times (1-\frac{7}{10}) )=0.44
Gini(D,A=青年)=155(2×52×(1−52))+1510(2×107×(1−107))=0.44
2. 回归树
回归树使用平方误差最小准则,一个回归树对应着输入空间(特征空间)的一个划分以及在划分的单元上的输出值。假设已经将输入空间划分为M个单元
R
1
R_{1}
R1,
R
2
R_{2}
R2,
.
.
.
...
...,
R
M
R_{M}
RM,并且在每个单元
R
m
R_{m}
Rm上有一个固定的输出值
c
m
c_{m}
cm,回归树模型:
f
(
x
)
=
∑
m
=
1
M
c
m
I
(
x
∈
R
m
)
f(x)=\sum_{m=1}^{M}c_{m}I(x\in R_{m})
f(x)=m=1∑McmI(x∈Rm)
当输入空间的划分确定时,使用平方误差
∑
x
i
∈
R
m
(
y
i
−
f
(
x
i
)
)
2
\sum_{x_{i}\in R_{m}}(y_{i}-f(x_{i}))^{2}
∑xi∈Rm(yi−f(xi))2表示回归树训练数据的预测误差。
最优切分变量
j
j
j,与切分点s,求解:
m i n j , s [ m i n c 1 ∑ x i ∈ R 1 ( j , s ) ( y i − c 1 ) 2 + m i n c 2 ∑ x i ∈ R 2 ( j , s ) ( y i − c 2 ) 2 ] min_{j,s}\left [ min_{c_{1}} \sum_{x_{i}\in R_{1}(j,s)} (y_{i}-c{1})^{2} + min_{c_{2}} \sum_{x_{i}\in R_{2}(j,s)} (y_{i}-c{2})^{2} \right ] minj,s⎣⎡minc1xi∈R1(j,s)∑(yi−c1)2+minc2xi∈R2(j,s)∑(yi−c2)2⎦⎤
遍历变量 j j j,对固定的切分变量 j j j扫描切分点 s s s,使得上式达到最小值的 ( j , s ) (j,s) (j,s)
6. 决策树剪枝
剪枝(pruning)是决策树学习算法解决过拟合的重要手段。在决策学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时候会出现过拟合。
决策树剪枝分为“预剪枝”(prepruning)和“后剪枝”(postpruning)。
- 预剪枝
预剪枝是在决策树生成过程中,对每个结点在划分前进行估计,若当前节点的划分不能带来决策树泛化性能提升,则停止划分并且将当前的节点标记为叶节点。
解决过拟合方法:- 树的深度
- 叶节点树
# sklearn参数设置
from sklearn import tree
model = tree.DecisionTreeClassifier(max_depth=, # 最大深度
max_leaf_nodes=) # 叶节点树
- 后剪枝
后剪枝是先从训练集生成一棵完整的决策树,然后自底向上地对非叶节点进行考察,若该节点对应的子树替换成叶节点能带来决策树泛化性能的提示,则将该子树替换成叶节点。
计算子树的损失函数:
C α ( T ) = C ( T ) + α ∣ T ∣ C_{\alpha }(T)=C(T) +\alpha |T| Cα(T)=C(T)+α∣T∣
其中 T T T为任意子树, C ( T ) 为 对 训 练 数 据 的 预 测 误 差 C(T)为对训练数据的预测误差 C(T)为对训练数据的预测误差, ∣ T ∣ |T| ∣T∣为子树的叶节点个数, α \alpha α是一个大于0的参数。 C α ( T ) C_{\alpha }(T) Cα(T)为参数是 α \alpha α时的子树 T T T的整体损失, α \alpha α权衡训练数据的拟合程度与模型的复杂度。















 156
156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









