







2. 决策树
2.1 工作原理
决策树(decision tree)是一种基本的分类与回归方法。举个通俗易懂的例子,如下图所示的流程图就是一个决策树,
- 长方形代表
判断模块(decision block), - 椭圆形成代表
终止模块(terminating block),表示已经得出结论,可以终止运行。 - 从判断模块引出的左右箭头称作为
分支(branch),它可以达到另一个判断模块或者终止模块。

2.2 决策树的一般流程
2.2.1 知识补充
信息熵
集合信息的度量方式称为香农熵或者简称为熵(entropy).
熵定义为信息的期望值。在信息论与概率统计中,熵是表示随机变量不确定性的度量。如果待分类的事物可能划分在多个分类之中,则符号xi的信息定义为

经验熵
当熵中的概率由数据估计(特别是最大似然估计)得到时,所对应的熵称为经验熵(empirical entropy)。
什么叫由数据估计?比如有10个数据,一共有两个类别,A类和B类。其中有7个数据属于A类,则该A类的概率即为十分之七。其中有3个数据属于B类,则该B类的概率即为十分之三。浅显的解释就是,这概率是我们根据数据数出来的。我们定义贷款申请样本数据表中的数据为训练数据集D,则训练数据集D的经验熵为H(D),|D|表示其样本容量,及样本个数。
设有K个类Ck, = 1,2,3,…,K,|Ck|为属于类Ck的样本个数,因此经验熵公式就可以写为 :
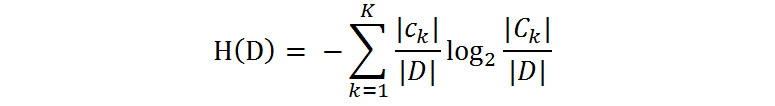
条件熵
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性,随机变量X给定的条件下随机变量Y的条件熵(conditional entropy)H(Y|X),定义为X给定条件下Y的条件概率分布的熵对X的数学期望

同理,当条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的条件熵称为条件经验熵
信息增益
信息增益是相对于特征而言的。所以,特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即:
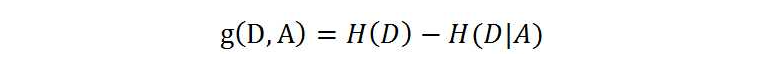
一般地,熵H(D)与条件熵H(D|A)之差称为互信息(mutual information)。决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
信息增益率
2.2.1 构建决策树
2.3 决策树的优缺点
优点:
- 数据形式非常容易理解
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









