









 C3D网络是一种基于3D卷积的模型,用于提取视频的时空特征。它在ICCV'15上提出,核心贡献在于使用3x3x3的卷积核在所有层中,有效保留时间信息,实验表明depth-3最为高效。网络结构包括5层卷积,5层下采样,2层全连接和1层softmax。
C3D网络是一种基于3D卷积的模型,用于提取视频的时空特征。它在ICCV'15上提出,核心贡献在于使用3x3x3的卷积核在所有层中,有效保留时间信息,实验表明depth-3最为高效。网络结构包括5层卷积,5层下采样,2层全连接和1层softmax。
《Learning Spatiotemporal Features with 3D Convolutional Networks》概述
写在前面:
最近阅读了本篇论文,这篇论文发表在ICCV’15上,提出了经典的C3D网络结构,这是一种基于3D卷积的方式能够同时提取时间以及空间上的特征,以下是对文章的整体概述,如有错误的地方,欢迎留言指正。
一、主要贡献:
- 3D ConvNets 比起 2D ConvNets更容易学习时空特征;
- 在C3D模型结构中使用一个3x3x3的卷积核应用在所有的layers层中表现的最好;
- C3D模型的表现优异在实验的任务中。
作者认为有效的视频描述符应该具有四个属性(C3D具有的)
- 良好的泛化性(generic):可以很好的表示不同类型的视频的同时具有区分性;
- 很好的压缩性(compact):结构精简但功能健壮;
- 高效性(efficient);
- 结构简单(simple);
二、网络结构:
首先我们来看一下3D卷积和2D卷积的区别,下图为论文中的原图:
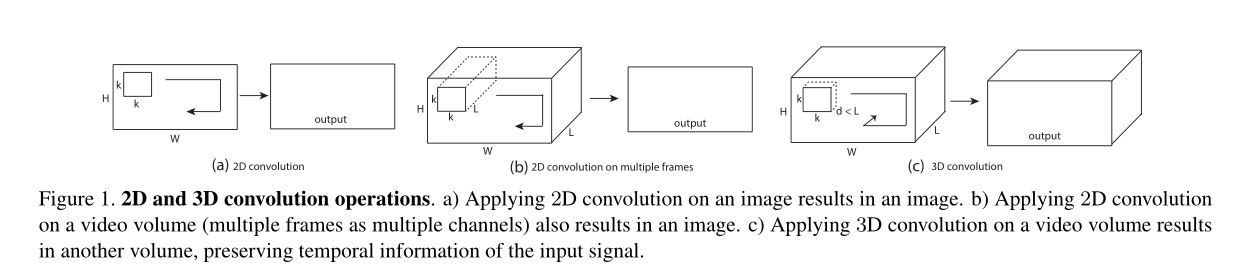
论文中的图片似乎不是很清晰的明白3D卷积是如何工作的,下图引用自知乎上的图片,左图为2D卷积,右图为3D卷积:
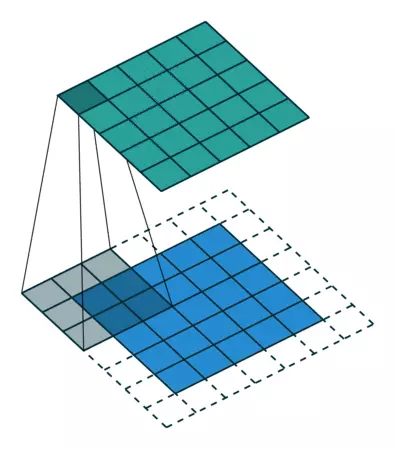
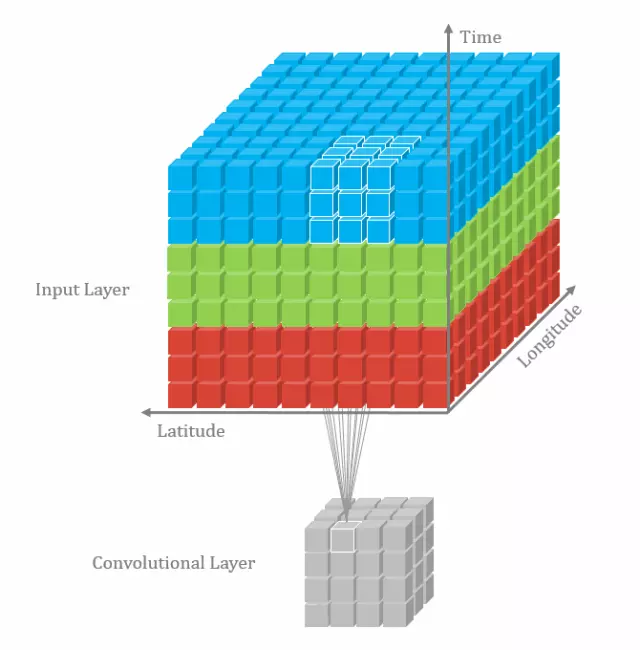
从图中可以看出,3D卷积比2D卷积多一个时间深度,3D卷积的步骤是可以在时间维度上滑动而2D卷积则没有时间维度。上面进行卷积操作的时间维度为3,即对连续的三帧图像进行卷积操作,上面的 3D卷积是通过堆叠多个连续的帧组成一个立方体,然后在立方体中运用3D卷积核。在这个结构中,卷积层中每一个特征map都会与上一层中多个邻近的连续帧相连,因此捕捉运动信息,有一点要注意的是3D卷积在时间的维度上是共享权重的,而不要由于卷积核是3维的就类比多通道(RGB)的2D卷积,3D的卷积核是在时间维度上滑动的,因此共享权重。
至于为什么3D卷积有效,作者指出2D ConvNets在每次卷积运算后都会丢失输入信号的时间信息,而3D卷积这保留了时间的信息。
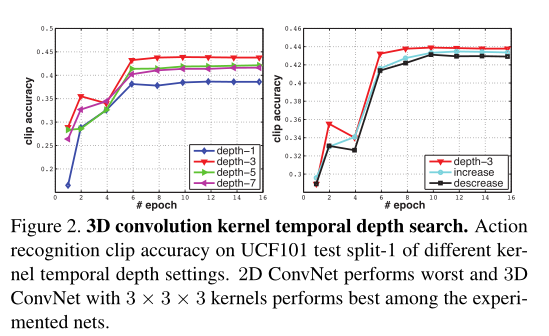
之后作者通过实验分别对时间depth-1(相当于2D)depth-3、depth-5、depth-7做实验对比探究何种时间深度以及epoch是最为高效的,随后发现depth-3是最为有效,由此确定卷积核的大小为3x3x3,下图为实验对比:
C3D的网络结构:

网络设置:
-
首先从每一个视频中随机抽取5个2秒长的视频段;
-
所有的视频帧下采样到128×171,大概是原始视频分辨率的一半;
-
视频分割为不重叠的16帧视频片段,作为网络的输入;
-
输入维度为3×16×128×171,训练阶段再对图像进行随机裁剪,得到尺寸为 3×16×112×112的数据输入;
-
网络有5层卷积层,5层下采样层(连接在5层卷层),2层全连接层,1层softmax层。卷积层的卷积核数量如上图所示;
-
每一个卷积核 d ∗ k ∗ k d*k*k d∗k∗k , d d d 表示核的时域深度,卷积核的步长设置为1,所有的pooling层尺寸为2×2×2(第一层pooling除外,第一层为1×2×2);
-
所有的全连接层有2048个单元,mini-batch为30,初始化的学习率为0.003;每4个epoch过后,学习速率除以10,迭代16个epoch后结束。
之后的篇幅就是反卷积实现可视化以此来观察3D卷积的描述符,以及在动作识别等任务上的实验对比,如果感兴趣的话可以阅读原文,并且作者给出了代码地址: http://vlg.cs.dartmouth.edu/c3d

















 1616
1616

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









