




 本文探讨了APPNP和GCNII这两种图神经网络模型的原理与实现。APPNP利用PageRank传播节点特征,而GCNII在此基础上引入残差连接与非线性变换,以缓解过平滑问题并提高模型表达能力。
本文探讨了APPNP和GCNII这两种图神经网络模型的原理与实现。APPNP利用PageRank传播节点特征,而GCNII在此基础上引入残差连接与非线性变换,以缓解过平滑问题并提高模型表达能力。
APPNP

其中 predict 指的是 采用 neural network 降维得到 hi。 hi 进行propagate得到zi(通过PageRank)
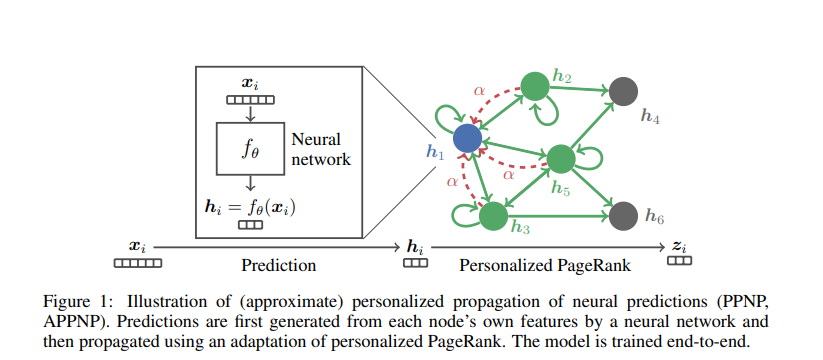
1. 方法一(PPNP) PageRank计算对于每个节点其他节点的 score,从而一次传播得到结果,这样做的坏处,求解 矩阵A的逆 很复杂 会导致一个n*n的 dense矩阵

2. 方法二(APPNP) 通过幂迭代 多次 来逼近这个 PPR矩阵,从而使得问题可以解决 APPNP 另外的角度就是 randomwalk with restart。 PR就是通过随机游走来获得其余的节点对于节点的重要性,teleport使得 节点下一次的状态 都有一定的概率到达 自身的状态

GCNII
layer:传播公式
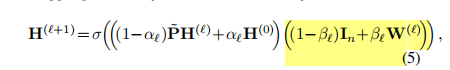
对比GCNII的 公式和 APPNP 公式4的第二行。 可以发现 GCNII就是 给APPNP 乘了(1-β)In + βW,同时加上了激活函数,成为了 非线性。
根据矩阵乘法分配律, 单位矩阵I和参数矩阵W分别 和左边相乘。 单位矩阵的效果就是 APPNP的Z , W就是增加了参数量,使得表征 在不断的 交互。 β足够小的时候,模型就是 APPNP+非线性
Note: 作者说 appnp 若采用多次非 线性来处理 特征矩阵会 过拟合,因此采用了 线性组合 从而推出------- appnp还是一个 shallow的模型。 ???? 不加激活函数的非线性就是 浅层吗

公式5 作者说 借鉴了 Resnet的思想,给W增加一个I,使得模型 至少和 浅层版本(appnp)效果一样,同时这个单位矩阵的好处,使得最优的参数矩阵W 有很小的范数,因此避免了过拟合(相当于给W加了正则),同时 唯一关键点是 全局最优

对于APPNP和GCNII相似的model来说。 GPRGNN也是APPNP的变分,他是 每层的H 采用了 不同的系数,其实也可以 在GPRGNN上增加这个 单位映射非线性
有关GCN过平滑和参数矩阵W的关系,好几篇文章 都对于 W进行正则项约束,EGNN那篇通过迪利克雷能量 也对W做了约束。 下面这篇文章 说出 GCN的收敛速率 决定于 W的最小奇异值。 通过(1-β)I+ βW,两个矩阵相加的范数小于两个矩阵范数的和(三角不等式),因此,使得W的范数 = 整体的范数- 单位矩阵的范数。

这里就是 通过 resnet和这个W+I的范数 两个角度 为这个 简单模型奠定了理论基础 。
Code — APPNP (pytorch)
包含ppnp和appnp。ppnp: PPRExact,通过calc_ppr_exact来计算 原文公式3. PPRPowerIteration 就是通过幂迭代求解 下一层=这一层传播+最初

Code ---- GCNII
pyG的代码:

其中 x.mul_(1-self.alpha) 计算出 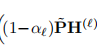
下面采用 torch.addmm(input,mat1,mat2,beta,alpha) : res = betainput+alpha(mat1mat2)
这里是将 左边括号 PH+H0 拆开计算
第一个 torch.addmm 计算了 传播后的表征PH 和 单位矩阵(没有显式写出来,矩阵单位=自身,因此只有 x*1-beta)相乘, 同时加上 传播后的表征 和 参数矩阵weight1 相乘再乘以beta。
第二个 torch.addmm 计算了 H0 和单位矩阵和参数矩阵的结果
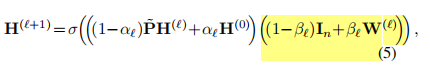
两个整体就是一层的表征
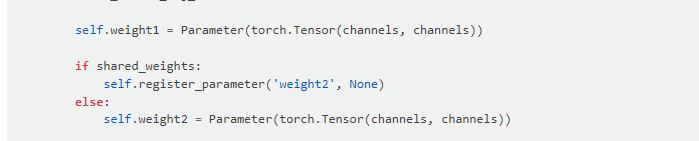
Note 这里有一个 weight2 矩阵。就是 如果没有第二个参数矩阵,就对应的 原论文 公式5. 左边两个表征求和,在和右边的矩阵进行 带参数的乘法。 weight2矩阵是 对于 传播后的表征和 原始残差分别学习参数, 即:把 左边括号拆开。 右边W是W1,W2.
默认情况下 shared_weight 默认的是 True,就是一个矩阵,和论文一样
GCNII Code 作者自己的pytorch版本 有太多不同的tricks,看起来挺恶心的, 还是PyG的版本最符合论文
重新定义Graphconv : 这里又提出了 两种,variant1,2 分别是 探究了 括号左边两个 表征如何结合,采用拼接,或者加法,其中 加法版本就是 论文的版本,计算出的support 为左边括号整体,但这里r 永远又是 加法的版本。 左边整体和右边括号里面的两个矩阵相乘 拆开 ,一个和weight相乘 一个和单位阵(隐式)

而且,这里又有一个 residual的参数,来对所融合的表征再加一个x。。。 相当于在原有的公式基础上 还增加了上一层表征 。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









