






kafka发布通知
kafka是消息队列,kafka采用发布订阅模式进行消息的生产与消费。在项目中,我们采用spring来整合kafka,
通过定义事件event来封装 点赞、关注、评论三类事件,event实体中有 事件主题topic,当前用户id(hostholder),实体类型 实体id,该实体的用户id(帖子,评论才有,因此只有 点赞 评论的 事件中会查出,关注的时候,因为只能关注用户 其实就是 用户id,也就是 实体id)。分别当用户评论、点赞、关注时,进行event数据的封装。
生产者采用kafkatemplate中的send方法进行消息的生产,其中send方法参数通过获取event实体的topic将 消息生产到指定的 topic中。
@kafkaListListerner(topics = {})注解。 监听这些主题,自动封装成为ConsumerRecord传入。
消费者 通过 kafkaListener注解进行某个主题消息的消费。项目中,消费所有的三类主题消息,获取消息之后存到message表中。message表也是私信列表,不同于私信时候谁给谁发,私信这里 messsage表中的conversationid存的是 fromid_toid ,而通知 存的是 event的topic字段,表明是 like comment 还是follow。
消息发布之后,我们需要给用户展示消息,这里只是展示 三类通知 最新的一条,通过 message表中的conversionid字段,controller通过传递参数 是否是 like comment 还是 follow 查询 message表中conversationid字段相符合的最新一条,展示 用户*** 关注(评论点赞)了你
kafka:高吞吐,消息持久化(永久保存到介质中,blockinngqueue在内存,kakfa存在硬盘,因此可以处理大批量数据,误解:读写硬盘的高低,是根据使用方法来看的,对硬盘的顺序读写比对内存的随机读取效率更高!!! ;此外分布式服务器来保证高可靠性;集群配置方便具有高可扩展性)
kafka是框架,是对基本的阻塞队列的封装。
阻塞队列就是一个接口,就是BlockingQueue,解决的是线程通信问题。线程通信我们还可以采用 object里面的wait notify,但是更加原始。所以通常直接采用这个api实现:通过put和take阻塞方法。如线程1put到队列(生产者),线程2从队列中take(消费者)。blockingQueue就是在两个线程之间建立了一个桥梁,一个缓冲。避免的现象:生产的快,消费的慢,导致一直生产,浪费系统资源;反正,生产慢,消费快,很快被消费完了,线程2一直请求获取,但没有,同样也占用了系统资源。如果有blockingqueue,当阻塞队列满了,put方法就被阻塞了;反之没有数据,线程2的take也被阻塞,不影响cpu的性能,避免了cpu资源的浪费。
为什么要采用生产者消费者啊,生产的时候 为什么采用队列进行生产,而不是直接插入到 message表中呢? ---- 应用解耦,发布通知成功之后,不考虑数据库,消费者进行 拉的方式,进行相关主题 队列中消息的 数据库操作
异步处理,当 评论 点赞 关注 (频发事件)发生时, 只需要通过生产者将 消息 发布到 broker(kafka的服务器),之后 消费者异步读取消息队列,这是在后台进行,通过消费者进行 数据库的写入及封装。 而不是 和之前一样,事件发生时,去进行数据库写入,封装数据,查询返回给客户端,同时进行。 为了实现高性能。
评论后 点赞后 关注后 发布通知 通知给被评论点赞关注的人
频繁的行为,要考虑性能,为此,用kafka。
采用消息队列,这三类不同的事情,可以定义三类不同的主题,一旦事情发生时候,包装成为一条消息,放到队列中,生产者就可以继续发,处理别的事情,后续消息处理由消费者去处理,即并发-异步-同时进行
消费者 就是 存到message表里
事件驱动的形式,以事件为目标。基于事件 对方法进行封装,而不是消息,三个事件的触发时机。对于事件发生时候,对数据进行封装,创建一个事件对象,来进行处理,而不是简单的一个字符串,事件里面包含了一些信息。
生产事件,消费事件。消费的时候是 把 事件转为消息存入
Redis 进行 点赞,关注,网站信息统计,以及通过id缓存用户
nosql数据库 not only sql。 非关系型数据库 采用键值对 进行 数据检索。
在项目中,我们 多个地方采用了 Redis进行性能优化
Redis的一些数据类型 String hash list set sortedset
通过 spring整合redis 配置文件指定 redis中哪一个库被使用 ,通过 redistemplate进行开发 opsfor
点赞
点赞是经常发生的事件,存储到 redis中进行统计,采用 Redis中的 set进行 点赞数据的存储,key是 like:entity:entityType:enityId 来 确定是 哪一个 实体的赞(帖子,评论) 。 set中存储的是 userId,一方面 可以通过id进行查询,查出是谁点了赞,另外set也可以进行数据的统计,得到赞的数目。用户进行 该实体的点赞时,如果用户id存在set中,那么点一下就是取消赞。通过size方法进行数据的统计
关注
采用zset 以关注的时间进行排序
关注这里 有两个地方, 一个是 用户关注了 多少个其他的用户, 另外是 用户拥有多少个粉丝。 这个项目比较基础, 都是 人关注人, 没有用户 关注 帖子 之类的 功能。 但是为了项目后续的 可扩展性,将 用户 抽象为实体
用户的关注 : 用户关注了哪个类型 : 将这个类型所有关注实体id存入
redis的key是 followee:userId:entityType -> zset (entityId,now)
用户拥有的粉丝 : 实体(用户)哪个(id) 拥有的粉丝 : 将粉丝id 存入 (粉丝肯定都是人)
follower: entityType:entityId -> zset(userId, now)
网站信息统计
这里是 是用了 hyperLogLog 和 bitmap 来统计 独立访客 和 日活跃用户
HyperLogLog : 基数算法,用于完成独立总数的统计,占用空间小,无论统计多少个数据,只存12k的内存空间
不精确,但是误差为 0.81%
Bitmap: 不是一种独立的数据结构,就是字符串,特殊字符串,按照位存取,每位存0或者1
适合存储大量大量连续数据的布尔值
比如:每天的 签到,第一位第一天,第二位第二天。0没到1到 365位bit =约等于 40个字节,很小
Unique Visitor 独立访客 UV : key是(两种,方法重载,一种是一个date,就表明统计当天时间的独立访客,两个date是 这个时间段的) value是 ip 数据结构 hyperloglog, 通过size()统计
独立访客是通过ip地址进行统计,没注册 没登录的也算。
采用HyperLogLog进行存储 性能好,存储空间小
Daily Active User 日活跃用户, DAU key(1. 当日是否活跃, 2. 开始时间:结束时间 是否是活跃的,只要7天有一个就行,采用 or 逻辑 运算 七天单日的活跃), value是当前用户id
本项目认为只要访问了一次 就认为是 活跃的用户。 这里排重 通过 userid。对于没有注册的用户 不加关注。要求结果精确,采用bitmap
网站的userid是整数,记录是否访问过,1表示活跃,0表示不活跃。id这个整数作为bit 索引来存储 , 比如 101 的user 存到 bitmap的101位,这样 就只用 一个bitmap(多个位)存储上万的用户
性能优化 一个是 4.7节登录优化redis 分布式 一个是 7.10 优化网站性能 本地缓存 caffeine
4.7 三者都是 采用 opsforValue,即 value的数据结构
1.采用Redis存储验证码(验证码点击很频繁,验证码不需要永久保存,之前存到session里面,session分布式共享有问题,redis这边直接可以设置过期时间,redis也是一个数据库,那么分布式部署时候,也就没有session的问题了)
2. 采用redis存储loginticket。之前是存在mysql中,拦截器每次都要进行查询后拦截。不优化,每次都查,性能受影响。
3. redis缓存用户的信息,每次都要根据凭证查用户,效率低。user表还需要保留,只不过将user对象缓存到redis中,过段时间就过期,符合实际业务,实际上用户也登录一段时间。但是loginticket表就丢弃不用了。
第三个业务通过用户id查询用户,之前是从数据库中进行查询,Redis修改之后,当通过id查询用户时,先从缓存查,查不到,才会去数据库。修改用户的信息时候,要么更新缓存,要么删掉缓存。本项目采用删除,因为更新可能产生并发问题,俩用户都去改。
1)先从缓存取
2)缓存取不到,初始化缓存
3)数据变更时,删除缓存
7.10 优化热门的帖子 进行缓存 提高性能
我们的帖子 有两种 排序方式,一种是按照 时间排序,一种是根据 计算出的score,来进行热门帖子排序
不去考虑 按照时间顺序的帖子进行缓存。缓存 一般要考虑 那些 更新较少的数据 ,热门是按照分数,隔一段时间 更新一下,能够保持很长时间不变,采用缓存。而按照时间,变化很快,一直更新缓存,反而浪费资源。
缓存 热门帖子 + 总行数 。采用 caffeine核心接口 CacheLoadingCache :排队等(采用这个,不并发)
JMeter 模拟多个请求访问服务器 关注吞吐量:没开缓存前视频上是10/sec, 开了缓存后是 188/sec
拦截器以及 security进行权限控制
拦截器 (1.用户登录时候拦截获取cookie 设置hostholder 2. 用户要访问修改用户页面时候,必须登录,需要用户有且 上面方法加了注解)
- 创建拦截器 实现 handlerInterceptor接口 重写 preHandle postHandle afterCompletion方法
- 创建配置类 WebMvcConfig 实现 WebMvcConfigurer 接口 重写addInterceptors方法 ,在这个方法中,进行拦截器的添加,并进行路径的排除exclude
第一次出现: 是在登录凭证处,浏览器访问了服务器之后,服务器在http报文中携带cookie,传给浏览器,浏览器之后的访问就都携带这个cookie,cookie中包含着用户的信息,项目中,首次访问后,传回ticket,这是为了保证数据的安全性,cookie容易被窃取,直接保存用户信息不安全,这里只是随机生成了一个 string的 ticket,之后访问,拦截器通过拦截获取cookie,判断登陆状态,如果ticket有效,且没有过期,通过ticket字段,查询 loginticket 表,获取用户id。通过用户id来进行 user的获取,将这个user保存到 hostholder中,hostholder是threadlocal类,对于 不同的 线程(浏览器),将线程作为key, user作为value保存,从而避免 多线程中 操作 单例对象线程不安全问题。
之后会采用 redis 直接 缓存 ticket : id,因此 loginTicket会作废,使用nosql 替换了 查表,提升了性能
自定义loginTicketInterceptor,在WebMvcCongif中进行配置,排除对静态资源的拦截
这里从cookie中获取到了 ticket,进而获取loginticket来获取id,通过id查到user,放到hostholder中,方便在这个线程中后续 getuser取出用户
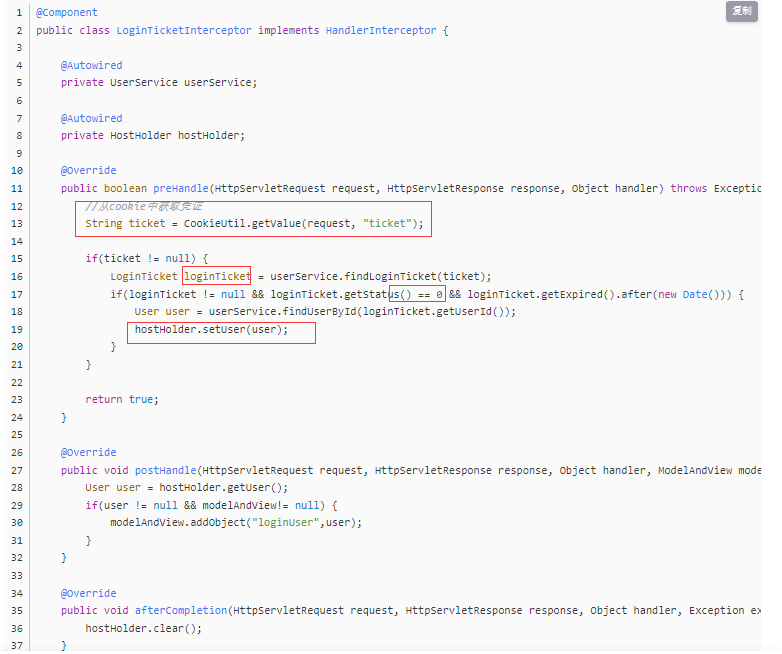
这个拦截器,对于大多数请求都进行拦截,只是配置时候排除了静态资源。即 如果 ticket没有到期,后面我们继续访问登录,拦截器会获取到cookie,识别到用户,将user注入hostholder,方便使用。
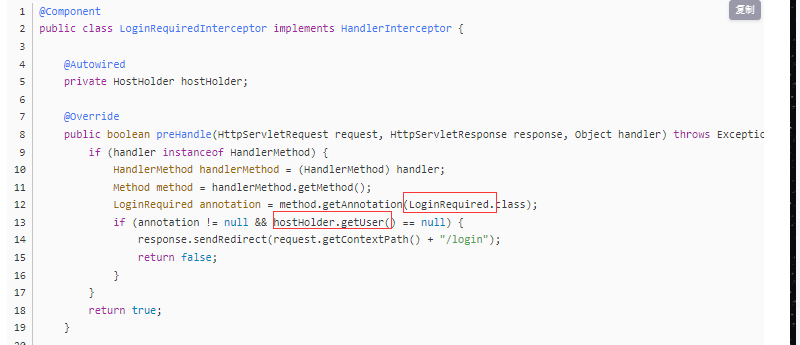
而下面第二次出现的拦截器,目的是 用户登录时候才能进行修改用户的信息,我们可以对于每个方法都进行用户登录状态的判断,暴力但太麻烦,可以采用拦截器进行拦截。但是 每次创建一个要被拦截的类时,就要修改拦截器源码,或者些不需要拦截的类时也要修改源码,排除这些类,这时你会想这岂不是比暴力法还麻烦。 这里采用注解开发, 之后要是有 别的方法也需要 被拦截,就自定义注解进行配置
第二次出现:
这里是出现在 用户 头像上传修改信息这里, 要确保用户登录,才能进行修改。 项目中采用 自定义注解,采用四个元注解中的 @Target 指定范围(方法ElementType.METHOD) @Retention 指定保留时间(运行时 RetentionPolicy.RUNTIME )
开发中,只需要在被拦截的方法上面添加这个注解就行 防止用户未登录,但是知道资源访问地址进行资源访问
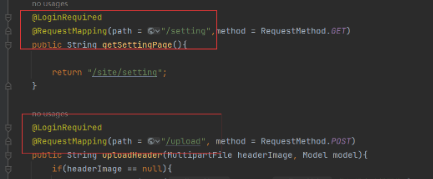
自定义 LoginRequiredInterceptor 拦截器实现 接口,对方法上面有 注解 且 用户登录过 进行拦截,没有登录就跳转到登录页面
Spring security
能够对用户的身份认证(判断是否登录)和授权(认证之后,进一步判断是否有访问该功能的权限:比如只有管理员才能干**)提供支持。
spring security的底层就是多个(11)filter,每个filter都有属于自己的功能。filter即spring security是在最前面进行拦截
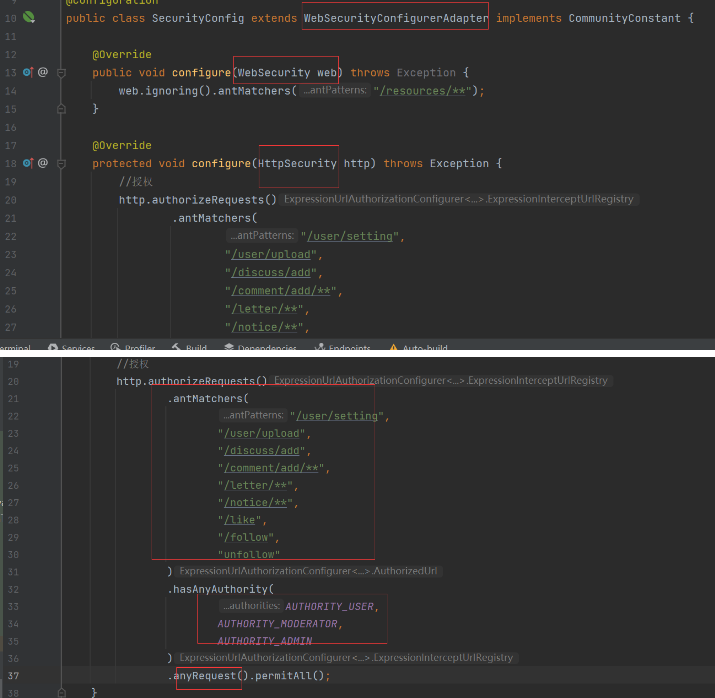
继承于 WebsecurityConfigureAdapter 重写父类的多个方法

AuthenticationManagerBulider用于构建AuthenticationManager接口对象的工具,默认实现类ProviderManager
ProviderManager持有一组authenticationProvider,每个authenticationProvider负责一种认证(指纹,刷脸,qq微信等)ProviderManager自己不去负责认证,包含的这么多authenticationProvider去干。 这就是一种模式:委托模式
牛客就只有一种 账号密码。 authentication是封装认证信息的接口,不同的实现类,代表不同类型的认证信息(我们采用账号密码)里面的support返回支持的哪种认证类型,我们采用usernamePasswordAuthenticationToken:即我们使用的是 账号密码认证模式。
如何认证呢?从authentication获取账号密码,之后就判断是否存在+密码是否对不对,返回值(主要信息-用户,密码,权限)
当我们登录的时候,spring security就会调用该接口,进行认证。
授权处理,接口Httpsecurity。设置登录表单相关的配置,有登录页面/loginpage,登录处理的路径/login,结果,成功失败都可以跳转(转发)某个页面。另一种方法:实现成功handler和失败handler接口。接口里面实现相关逻辑,成功重定向首页。错误回到登陆页面,给提示,不能够重定向,这就两个请求了,需要绑定request,通过转发进行返回。
授权:
authorizeRequest,配置路径+权限(user admin),表明拥有哪种权限才能访问哪些页面
spring security 可以做 认证(登录) + 授权(权限访问),我们项目中,登录,也就是 认证 绕过了 spring security, 仍然采用我们之前的 逻辑,即账号密码进行判断, 而授权,这里是 注释掉了 loginrequired那个拦截器,就是 修改上传用户那个。 采用 security 进行认证,继承了 类,进行简单的配置, 即 设置 哪些权限的用户 可以 访问哪些 资源
ES
高亮功能 + 搜索
搜索的时候, 需要向ES服务器 存入 帖子数据 (ES中之前已经存了已有数据,之后 发生新的 事件, 继续往服务器中加入数据)
生产者:
即 发布帖子时候,触发事件 publish,放到阻塞队列中, 当评论时,触发事件,放到阻塞队列中。
消费者:
当监听到 插入 评论或者帖子(publish)就向es服务器插入数据。
es就同步了数据库中的新数据,确保能检索
事务在项目中的应用 采用声明式事务 即注解进行开发
@Transactional(isolation = , propagation = )
项目中的体现有: 增加评论add comment时,不仅要插入一个 comment,同时还要更新评论的数目,即 insert + update
包含了两个 DML操作,要么全成功,那么全失败 !!!!!!
这时候就要保证 两者 状态一致, 满足acid
AOP的体现
统一日志管理 + 统一异常处理















 4232
4232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









