









An Advanced Approach of Local Counter Synchronization to Timestamp Ordering Algorithm in Distributed Concurrency Control
DOI
摘要:并发控制是数据库管理系统(DBMS)特别是分布式DBMS遇到的困难问题。有两种主要的并发控制方法,例如基于锁定和基于时间戳。每种方法都有其自身的缺点,但基于锁定的方法通常在大多数分布式 DBMS 中实现,因为它的可行性和严格性减少了分布式环境中的危险。否则,由于分布式环境中站点之间的本地计数器同步问题,时间戳排序算法仅在中央DBMS中实现。常见的解决方案是通过分布式网络广播有关本地计数器(在一个站点)更改的消息,以便所有剩余站点“知道”更新自己的计数器。然而,这种解决方案带来了一些性能低下的缺点。因此,提出了一种先进的方法来克服这些缺点,方法是给出另一种称为活动数的措施,该措施负责协调分布式站点之间的本地计数器。此外,还提出了另一种方法来应用最小生成树来降低在分布式网络上广播消息的成本。
关键词:分布式并发控制、时间戳排序算法、本地计数器同步
学科领域:分布式计算、信息与通信理论与算法
1 介绍
并发控制保证了事务的一致性和可靠性属性。在讨论主要内容之前。我们应该浏览一些重要性定义。请注意,该研究是一种改进知名算法的建议方法。所以,定义和方法都被简单地提到了;有关分布式并发控制的更多详细信息,请参阅 [1]。调度 S 是一组事务:S={T1,T2,…,T3};每个事务 T i 都有数据操作 O ij (读或写)。如果其中一个是写入,则访问同一数据项 x 的两个操作会发生冲突。

如果一个调度与串行调度冲突等效并且串行执行称为序列化顺序,则它是可串行化的。所有并发控制算法都专注于生成可序列化的调度来归档两个目标:
- 执行事务的顺序是确保事务执行结果良好的序列化顺序。
- 利用并行处理。
有两种基本的并发控制方法,例如基于锁定和基于时间戳。两者各有优缺点,但基于时间戳的方法是本文的关键,因为该方法不存在死锁问题,并且在某些情况下比基于锁定的方法更有效。现在已经介绍了有关并发控制方法的一些主要方面,但是很难将这些方法从非分布式数据库“移动”到分布式数据库。当然,基于锁定的方法被修改以适应分布式环境,但我建议在分布式环境中对基于时间戳的方法进行一些改进。第 2 节讨论了基于时间戳的算法,第 3 节提出了它的改进。第 4 节是结论。
2 时间戳排序算法
与通过互斥保持可序列化的基于锁定的方法不同,基于时间戳的并发控制算法试图通过下列方案来维护可序列化:
- 为每个事务分配唯一的时间戳。
- 根据时间戳对事务进行排序。因此,有一个可序列化的事务顺序。
- 根据此顺序执行事务。
时间戳是每笔事务的标识符,用于允许排序。时间戳有两个基本属性:唯一性和单调性。单调性是指由同一事务管理器 ™ 生成的时间戳的值单调递增。该属性允许区分时间戳和事务标识符。
生成时间戳的方法有两种:
- 使用单调递增的全局计数器,但在分布式环境中维护全局计数器非常困难。
- 每个站点都可以自由地在本地计数器上自行分配时间戳。为了保持唯一性,每个站点都将其标识符附加到本地计数器。因此,时间戳采用两部分形式 <local-counter-value, site-identifier> 或 <local-system-clock, site-identifier> [1]。站点标识符被放在最不重要的位置,以避免来自一个站点的一个时间戳总是大于或小于另一个站点的情况。
当事务已经被分配了时间戳时,对事务的操作(读、写)进行排序必须遵守时间戳排序(TO)规则“给定属于事务 T i 和 T 的两个冲突操作 O ij(x) 和 O kl(x) k 分别,如果 T i 的时间戳小于 T k 的时间戳,则 O ij(x) 在 O kl(x) 之前执行" [1]。这意味着较旧的事务首先执行。
一般来说,TO 算法通过两个主要步骤在下面简要描述 [1]:
- TM 接收来自应用程序的事务并为其分配时间戳值。之后,TM 将这些事务的操作(读、写)O ij 传递给调度程序(SC)。
2)SC按TO规则调度数据操作。它检查每个新操作与已安排的冲突操作。如果新操作属于比所有冲突事务更年轻(晚)的事务,则接受它;否则拒绝它并使用新的时间戳重新启动整个事务。
可以断言,TO算法是按照时间戳顺序来维护执行顺序的。
3 本地计数器同步的一种高级方法
假设在每个站点的本地计数器上生成时间戳,则存在本地计数器同步的问题。请注意,如果安排了另一个较年轻的事务,SC 将重新启动事务。如果有网站不活跃或定期没有收到任何事务,这种情况会多次发生。在这种情况下,这些站点的本地计数器比其他站点小得多,大多数进入这些站点的事务将多次重新启动,直到它们的计数器与其他站点的本地计数器近似。此后,图 1 [1] 描述了一个关于如何在站点之间维护时间戳的示例。
站点 2 的事务 T 尝试读取存在于站点 1 并具有读写时间戳的数据项 x:rts(x) 和 wts(x)。如果 T 的时间戳记为 ts(T) 小于 wts(x),则拒绝读取并重新启动 T 并从站点 2 的计数器获取新的更大时间戳。当站点 2 的计数器太小时,T 没有机会被执行。
有必要在所有站点同步本地计数器。每当一个站点的 TM 因接受事务而增加其自己的计数器时,它就会广播一条消息,即更新其他站点的所有 TM 的计数器。之后,其他 TM 会将其本地计数器与即将到来的计数器进行比较,并将其计数器调整为比即将到来的计数器多 1(= 即将到来的计数器 + 1)。这是广播有关更新本地计数器的信息的机制。它确保没有运行太快或太慢的本地计数器。提出了计数器同步的两个改进:
- 改进了更新本地计数器的广播消息的方式。
- 降低了更新本地计数器的广播消息的数据传输开销。
3.1 改进更新本地计数器的广播消息方式
在分布式网络上广播更新本地计数器的消息是计数器同步中考虑最多的问题。给定站点 i 的事务管理器 TMi 在接收新事务时增加其自己的计数器。因此,TMi 有新的计数器计数器 (TM i) = 200,它分别向 TM1、TM2 和 TM3 发送三个消息,即 m1、m2 和 m3。
- TM1 具有旧的本地计数器计数器 (TM1) = 1。
- TM2 具有旧的本地计数器计数器 (TM2) = 150。
- TM3 具有旧的本地计数器计数器 (TM3) = 170。
因为计数器 (TMi) 比计数器 (TM1) 大得多,所以计数器 (TM1) 得到新值 201 = 计数器 (TMi) + 1。通常情况下,剩余的计数器 (TM2)、计数器 (TM3) 也都重新计算分配新值 201。此时,计数器 (TMi) 被视为“里程碑”。然而,在 TM2 和 TM3 处于活动状态的情况下,请注意“活动”一词暗示 TM 收到了更多交易。如果我们选择计数器(T i)作为增加TM2和TM3计数器的“里程碑”,那么其他站点拒绝事务的频率就会变高,因为TM2和TM3收到的事务越来越多,而且它们的锁越来越快。结果,站点 2、3 的新事务的时间戳得到如此高的值,因此站点 2、3 的数据项 xk 的 rts(xk) 和 wts(x k) 突然升高。访问 x k 的事务(在其他站点具有低时间戳)将更频繁地被拒绝。当然,分布式数据库管理系统的性能明显下降。然而,忽略计数器(TM i)的“里程碑”角色几乎是不可能的,因为这将导致在其他情况下,TM2 和 TM3 不活动的情况下会导致错过结果。在这种情况下有什么解决方案?
我建议时间戳以 <site-identifier, local-counter, active-number> 的三部分形式表示。零件的位置与其重要性相对应,例如第二个位置的 local-counter 比第三个位置的 active-number 更重要。因此,站点 i 的每个 TM i 都有一个新的活跃数,该活跃数负责衡量站点 i 的活跃程度。接收到的事务站点 i 越多,活跃数量就越高,因此给定站点的活跃数量可以通过到达该站点的事务频率来更新。假设站点即 TM1、TM2 和 TM3 在 TM i 具有新计数器 (TMi) 并分别向 TM1、TM2、TM3 发送三个消息 m1、m2、m3 的情况下更新自己的本地计数器,我的建议有两个以下步骤给定两个整数参数 α > 0 和 β > 0:

例如,我们有计数器 (TMi) = 200,计数器 (TM1) = 1,计数器 (TM2) = 150,计数器 (TM3) = 170,活动数 (TM1) = 10,活动数 (TM2) = 60 , 有效数 (TM3) = 100, α = 50 和 β = 80。应用上述算法,我们有:
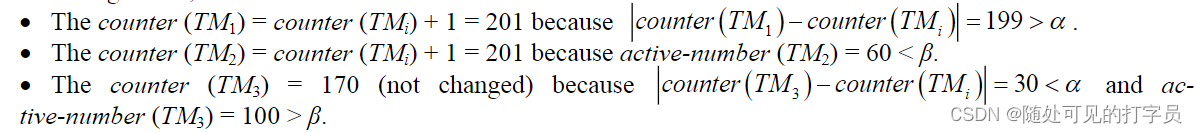
最后,如果该站点处于活动状态,则该站点的本地计数器的增加率将降低。换句话说,在活动站点增加的锁定被延迟。很容易推断,使用活跃数的目的是为了协调本地计数器的增加。如果给定站点的活动号丢失,则将其重置为零。请注意,时间戳 <site-identifier, local-counter, active-number> 的三元组仅由 local-counter 和 site-identifier 标识。活动号码是辅助部分。当事务重新启动时,active-number 也被重置为零。
3.2 减少广播消息中的数据传输费用
假设分布式数据库中的所有站点组成网络,包括与 TM (s) 对应的节点。每当一个节点调整自己的计数器时,它就会在整个网络上发布消息。所以这会消耗很多系统资源。如何减少消息传输的开销,同时保证消息必须到达每个节点?
我们将 TM 网络视为一个图,其中每个节点都是一个 TM,并且每条边都附加到权重,该权重表示从源 TM 节点到目标 TM 节点的传输费用。通过应用一些算法,如 PRIM 和 Krussal [2],不难找到此类图的最小生成树 [2]。最后,在这棵树上广播消息。因此,所有 TM 节点都以最低的传输费用接收到消息。图 2 描绘了 TM 图和以粗线绘制的最小生成树。
4 结论
本地计数器同步是并发控制中基于时间戳的方法的本质。在本文中,对这种同步提出了如下两个改进:
- 时间戳以三部分的形式表示:<site-identifier, local-counter, active-number>。本地计数器是否更新取决于活动数量和其他两个参数 α 和 β。其思想是延迟站点本地计数器的增加,直到完全满足由活动数α和β组成的条件,这样如果站点处于活动状态,则该站点的本地计数器的增加率将降低。
- 降低费用通过将TM网络视为图并在该图的最小生成树上广播消息来实现消息传输。
当然,我的技术并没有彻底解决通过网络广播消息时性能较低的缺点。它只是改进了基于时间戳的方法。总的来说,本文是对众所周知的时间戳排序算法进行改进的一个正在进行中的研究。如果与现有的方法相比,它需要大量的评估,而不仅仅是一个提案。
参考文献
[1] Ozsu, M.T. and Valduriez, P. (2011) Principles of Distributed Database Systems. 3rd Edition, Springer, Berlin.
[2] Wikipeadia (2014) Minimum Spanning Tree. http://en.wikipedia.org/wiki/Minimum_spanning_tree















 837
837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











