







一个嵌入式Linux系统从软件的角度看通常可以分为四个层次:
1、 引导加载程序:包括固化在固件(firmware)中的boot代码(可选),和BootLoader两大部分。
2、Linux内核:特定于嵌入式板子的定制内核以及内核的启动参数。
3、 文件系统:包括根文件系统和建立于Flash内存设备之上文件系统。通常用ramdisk来作为rootfs。
4、 用户应用程序:特定于用户的应用程序。有时在用户应用程序和内核层之间可能还会包括一个嵌入式图形用户界面。常用的嵌入式GUI有:MicroWindows和MiniGUI等。
uboot
uboot是用来干什么的,有什么作用?
uboot属于bootloader的一种,是用来引导启动内核的,它的最终目的就是,从flash中读出内核,放到内存中,启动内核。所以,UBOOT需要具有读写flash的能力。
uboot是怎样引导启动内核的?
uboot刚开始被放到flash中,板子上电后,会自动把其中的一部分代码拷到内存中执行,这部分代码负责把剩余的uboot代码拷到内存中,然后uboot代码再把kernel部分代码也拷到内存中,并且启动,内核启动后,挂着根文件系统,执行应用程序。
手机的 Bootloader 启动过程与计算机系统有些许不同。下面是一个典型的手机 Bootloader 启动过程:
- 加载 Bootloader:当手机上电后,Bootloader 被加载到内存中执行。一般来说,手机的 Bootloader 存放在闪存中,而不是在硬盘上。
- 初始化环境:在 Bootloader 开始执行后,它会初始化基本的硬件环境,例如 CPU、内存、屏幕、摄像头等。
- 加载引导程序:此时,Bootloader 会从闪存中读取引导程序,把它加载到内存中运行。引导程序会负责进一步的初始化动作,如设置与操作系统相关的参数和数据结构。
- 加载内核镜像:在引导程序运行之后,Bootloader 开始加载操作系统内核镜像。内核镜像是一个包含了操作系统核心代码的文件,通常位于闪存中或者通过网络下载。
- 启动内核:最后,Bootloader 把操作系统内核映像的控制权交给内核,启动操作系统。内核会进一步初始化系统,完成各种驱动程序的加载,然后启动 Shell 或图形用户界面。
总之,手机 Bootloader 启动分为加载 Bootloader、初始化硬件环境、加载引导程序、加载内核镜像和启动内核这五个主要阶段。每个阶段都有着自己的任务和目的,都是启动过程中必不可少的一部分。
大多数Bootloader都包含两种不同的操作模式:
(1)启动加载模式
在这种模式下,Bootloader从目标机的某个固态存储设备上将操作系统加载到RAM中运行,整个过程并没有用户的介入。这种模式是Bootloader的正常工作模式,因此在嵌入式产品发布时,Bootloader必须工作在这种模式下。
(2)下载模式
在这种模式下,目标机上的Bootloader将通过串口或网络等通信手段从开发主机(Host)上下载内核映像和根文件系统映像等到RAM中,然后可再被Bootloader写到目标机上的固态存储媒质中,或者直接进行系统的引导。
启动加载模式通常用于第一次烧写内核与根文件系统到固态存储媒质时或者以后的系统更新时使用;下载模式多用于开发人员在前期开发的过程中,工作于这种模式下的Bootloader通常都会向它的终端用户提供一个简单的命令行接口。
linux内核
head.S 是操作系统内核的第一个汇编文件,主要用于设置 CPU 状态、堆栈、跳转到 C 代码中的启动函数等,以便能够顺利地将控制权转移给操作系统内核。
主要功能包括:
-
清空 bss 段:清空操作系统内核中的 bss 段,避免未初始化变量的问题。
-
设置基础寄存器:设置操作系统内核的基础寄存器,包括栈、堆等。
-
加载内核代码:加载操作系统内核代码到内存中,并跳转到内核代码的入口处开始执行。
start.S 则是内核启动过程中的第二个汇编文件,它在 head.S 完成初始化后,进一步设置内核的运行环境、MMU、缓存等,并调用 C 代码中的启动函数 start_kernel。
start.S 文件主要负责执行以下任务:
-
清空 bss 段:start.S 文件会在启动时清空操作系统内核中未初始化的 bss 段,这样就可以避免未初始化变量带来的问题。
-
设置初始内核栈:该文件还会设置初始的内核栈,用于处理操作系统内核启动期间的各种中断和异常。
-
调整 CPU 模式和特权级:start.S 文件还会将 CPU 的模式调整为特权级模式,并将特权级设置为最高级别,以便能够访问所有的内存和硬件资源。
-
启动 MMU 和缓存:start.S 文件还会启动内存管理单元(MMU)和 CPU 缓存,以提高操作系统内核的运行速度。
start_kernel 是 Linux 操作系统内核的一个主要函数,它包含了操作系统内核在启动时的大部分初始化代码和任务,是整个内核启动过程的起点。
具体来说,start_kernel 函数主要完成以下工作:
- 初始化内核的全局变量:首先,start_kernel 函数会初始化内核的全局变量,包括 CPU ID、操作系统内核版本、内核命令行参数等。
- 设置内核的基本参数:该函数还会设置内核的一些基本参数,包括时钟参数、中断控制器参数、内存管理参数等。
- 初始化内核的子系统:start_kernel 函数还会初始化内核的各个子系统,例如进程管理子系统、文件系统子系统、网络协议栈子系统等。
- 启动 idle 进程:该函数还会启动 idle 进程,这是操作系统内核唯一的用户进程,当系统没有其他任务需要运行时,idle 进程会占用 CPU,并执行空循环等待下一个任务的到来。
- 启动 init 进程:最后,start_kernel 函数会启动 init 进程,这是操作系统内核用户模式下执行的第一个进程。init 进程会读取系统配置文件,并启动其他用户进程和服务。
总之,start_kernel 是 Linux 操作系统内核的主函数之一,它完成了内核的启动和初始化。当 start_kernel 函数执行完毕后,操作系统内核就已经准备好了,可以开始处理用户的请求,并提供各种功能和服务。
原文链接:https://blog.csdn.net/m0_74282605/article/details/128132589
rootfs根文件系统
首先要明白的是“什么是文件系统”,文件系统是对一个存储设备上的数据和元数据进行组织的机制。这种机制有利于用户和操作系统的交互。
根文件系统首先是内核启动时所mount的第一个文件系统,内核代码映像文件保存在根文件系统中,而系统引导启动程序会在根文件系统挂载之后从中把一些基本的初始化脚本和服务等加载到内存中去运行。
根文件系统之所以在前面加一个”根“,说明它是加载其它文件系统的”根“,既然是根的话,那么如果没有这个根,其它的文件系统也就没有办法进行加载的。它包含系统引导和使其他文件系统得以挂载(mount)所必要的文件。根文件系统包括Linux启动时所必须的目录和关键性的文件,例如Linux启动时都需要有init目录下的相关文件,在 Linux挂载分区时Linux一定会找/etc/fstab这个挂载文件等,根文件系统中还包括了许多的应用程序bin目录等,任何包括这些Linux 系统启动所必须的文件都可以成为根文件系统。
Linux启动时,第一个必须挂载的是根文件系统;若系统不能从指定设备上挂载根文件系统,则系统会出错而退出启动。成功之后可以自动或手动挂载其他的文件系统。因此,一个系统中可以同时存在不同的文件系统。
在 Linux 中将一个文件系统与一个存储设备关联起来的过程称为挂载(mount)。使用 mount 命令将一个文件系统附着到当前文件系统层次结构中(根)。在执行挂装时,要提供文件系统类型、文件系统和一个挂装点。根文件系统被挂载到根目录下“/”上后,在根目录下就有根文件系统的各个目录,文件:/bin /sbin /mnt等,再将其他分区挂接到/mnt目录上,/mnt目录下就有这个分区的各个目录,文件。
Linux根文件系统中一般有如下的几个目录:
1./bin目录
该目录下的命令可以被root与一般账号所使用,由于这些命令在挂接其它文件系统之前就可以使用,所以/bin目录必须和根文件系统在同一个分区中。
/bin目录下常用的命令有:cat、chgrp、chmod、cp、ls、sh、kill、mount、umount、mkdir、[、test等。其中“[”命令就是test命令,我们在利用Busybox制作根文件系统时,在生成的bin目录下,可以看到一些可执行的文件,也就是可用的一些命令。
2./sbin 目录
该目录下存放系统命令,即只有系统管理员(俗称最高权限的root)能够使用的命令,系统命令还可以存放在/usr/sbin,/usr/local/sbin目录下,/sbin目录中存放的是基本的系统命令,它们用于启动系统和修复系统等,与/bin目录相似,在挂接其他文件系统之前就可以使用/sbin,所以/sbin目录必须和根文件系统在同一个分区中。
/sbin目录下常用的命令有:shutdown、reboot、fdisk、fsck、init等,本地用户自己安装的系统命令放在/usr/local/sbin目录下。
3、/dev目录
该目录下存放的是设备与设备接口的文件,设备文件是Linux中特有的文件类型,在Linux系统下,以文件的方式访问各种设备,即通过读写某个设备文件操作某个具体硬件。比如通过"dev/ttySAC0"文件可以操作串口0,通过"/dev/mtdblock1"可以访问MTD设备的第2个分区。比较重要的文件有/dev/null, /dev/zero, /dev/tty, /dev/lp*等。
4./etc目录
该目录下存放着系统主要的配置文件,例如人员的账号密码文件、各种服务的其实文件等。一般来说,此目录的各文件属性是可以让一般用户查阅的,但是只有root有权限修改。对于PC上的Linux系统,/etc目录下的文件和目录非常多,这些目录文件是可选的,它们依赖于系统中所拥有的应用程序,依赖于这些程序是否需要配置文件。在嵌入式系统中,这些内容可以大为精减。
5./lib目录
该目录下存放共享库和可加载(驱动程序),共享库用于启动系统。运行根文件系统中的可执行程序,比如:/bin /sbin 目录下的程序。
6./home目录
系统默认的用户文件夹,它是可选的,对于每个普通用户,在/home目录下都有一个以用户名命名的子目录,里面存放用户相关的配置文件。
7./root目录
系统管理员(root)的主文件夹,即是根用户的目录,与此对应,普通用户的目录是/home下的某个子目录。
8./usr目录
/usr目录的内容可以存在另一个分区中,在系统启动后再挂接到根文件系统中的/usr目录下。里面存放的是共享、只读的程序和数据,这表明/usr目录下的内容可以在多个主机间共享,这些主要也符合FHS标准的。/usr中的文件应该是只读的,其他主机相关的,可变的文件应该保存在其他目录下,比如/var。/usr目录在嵌入式中可以精减。
9./var目录
与/usr目录相反,/var目录中存放可变的数据,比如spool目录(mail,news),log文件,临时文件。
10./proc目录
这是一个空目录,常作为proc文件系统的挂接点,proc文件系统是个虚拟的文件系统,它没有实际的存储设备,里面的目录,文件都是由内核
临时生成的,用来表示系统的运行状态,也可以操作其中的文件控制系统。
11./mnt目录
用于临时挂载某个文件系统的挂接点,通常是空目录,也可以在里面创建一引起空的子目录,比如/mnt/cdram /mnt/hda1 。用来临时挂载光盘、移动存储设备等。
12. /tmp目录
用于存放临时文件,通常是空目录,一些需要生成临时文件的程序用到的/tmp目录下,所以/tmp目录必须存在并可以访问。
总结如下:
什么是rootfs,为什么需要rootfs?
内核启动后会开启三个进程,分别是:
进程0(idle进程),空闲进程,也就是死循环
进程1(init进程),挂载根文件系统,并执行Linuxrc这个应用程序从内核态转为用户态,开启用户态的进程1(init进程),逐步开启其他进程
进程2(kthread进程)linux内核的守护进程,负责提供操作系统的核心功能(进程调度、内存管理、设备管理、文件系统)的实现
根文件系统的作用:
(1)init进程的应用程序(Linuxrc)在根文件系统上
(2)根文件系统提供了根目录/
(3)内核启动后的应用层配置(etc目录)在根文件系统上。几乎可以认为:发行版=内核+rootfs
(4)shell命令程序在根文件系统上。譬如ls、cd等命令
(5)/lib目录下的库文件等
所以:一套linux体系,只有内核本身是不能工作的,必须要rootfs
原文链接:https://blog.csdn.net/gysmmzh/article/details/53422731
从整个嵌入式软件架构层次看,rootfs是属于Linux基础运行环境的一部分,属于BSP负责范围。从产品开发角度看,为了减少组件的维护成本,BSP一般只维护uboot和kernel image两个组件,将rootfs以initramfs的方式打入到kernel image里面,也自然需要BSP负责。另外,如果交给应用层开发人员维护rootfs,就要求他们掌握更多关于系统启动、系统参数配置、设备节点管理、文件系统、分区挂载等嵌入式底层相关细节,不利于专业分工。
所以,rootfs应该由BSP来负责,而且要尽可能保证不同产品、平台、单板上BSP组件调用APP组件的接口(挂载应用分区、验证并启动应用程序引导启动脚本)一致。
原文链接:https://www.zhihu.com/topic/25400639/top-answers
devicestree文件配置及makefile语法
术语介绍:
1,DTS(Device Tree Source):设备树源码。为方便阅读和修改,设备树源文件遵循一定的格式,采用文本方式存放。
2,DTB(Device Tree Blob):设备树对象。DTS的二进制对象表示形式,通过DTC将DTS编译成DTB。
3,DTC(Device Tree Compiler):设备树编译器。kernel提供的一个小工具,可以将 DTS 编译成 DTB。
DTS为什么需要转换成DTB?kernel在初始化阶段需要从设备树读取平台的各种硬件信息(如,bootargs/cpu/memory/devices等),bootloader在加载kernel image的同时,也需要加载设备树信息。bootloader将加载后的设备树物理地址传递给kernel,kernel再去配置各种硬件信息。因此,需要定义出DTB的二进制格式,通过DTC将DTS编译成DTB,经bootloader加载,kernel解析DTB,最终在kernel中形成一套完整的device tree。
devicetree 是由 DTC(Device Tree Compiler)编译成二进制文件DTB(Ddevice Tree Blob)的,然后在系统上电之后由bootloader加载到内存中去,这个时候还没有device tree,而在内存中只有一个所谓的 DTB地址,这只是一个以某个内存地开始的一堆原始的dt数据,没有树结构。kernel的任务需要把这些数据转换成一个树结构然后再把这棵树的根节点的地址赋值给allnodes就行了。这个过程一定是非常重要,因为没有这个 device tree 那所有的设备就没办法初始化,所以这个 dt 树的形成一定在kernel 刚刚启动的时候就完成了。
问题:相同的dtsi文件配置,在同一批次的硬件上会不会出现效果或者性能有所差异?
在同一批次的硬件上,相同的dtsi文件配置理论上应该不会出现效果或者性能有所差异的情况。因为同一批次的硬件应该是由同样的生产工艺、原材料和生产设备制造生产的,因此硬件特性、功能和性能应该是相同的。
当然,如果同一批次的硬件存在质量问题,如制造过程中出现了误操作、材料选择不当或工艺不正确等错误,那么可能会导致相同的dtsi文件配置在这些硬件上产生差异,例如某些设备不能正常工作、性能下降或出现异常等情况。但这种情况应该是非常罕见的,只有在生产出现重大问题或者硬件本身存在缺陷时才会发生。
因此,在设计嵌入式系统时,需要仔细考虑硬件平台的稳定性和可靠性,确保在同一批次的硬件上可以获得一致的性能和功能表现。另外,也需要进行充分的测试和验证工作,以发现潜在的硬件问题,保证系统的稳定性和可靠性。
原文链接:https://blog.csdn.net/xiaopangzi313/article/details/52331931
https://blog.csdn.net/weixin_33850015/article/details/91871179
通讯协议(UART、SPI、I2C、TCP\IP)

SPI接口可以一个一个字节的传输,也可以一次性传输多个字节。这取决于SPI设备与主机之间交互数据的方式。
在单字节传输模式下,SPI主机向从设备发送一个字节数据,并且同时接收一个字节数据,完成一次串行通信操作。这种通信方式需要不断地发送和接收数据,来实现完整的数据传输。在每次数据传输之前,需要通过片选信号(CS)进行设备的选中操作。
而在多字节传输模式下,SPI主机可以一次性发送多个字节数据,并且同时接收从设备返回的多个字节数据,完成一次高速的数据传输。这种通信方式使用了先进的DMA(Direct Memory Access)技术,可以大大提高数据传输的效率。
原文链接:https://xiefor100.blog.csdn.net/article/details/65445338
https://blog.csdn.net/chenpuo/article/details/81023882
交叉编译
为什么需要交叉编译呢?
有时是因为目的平台上不允许或不能够安装我们所需要的编译器,而我们又需要这个编译器的某些特征;有时是因为目的平台上的资源贫乏,无法运行我们所需要编译器;有时又是因为目的平台还没有建立,连操作系统都没有,根本谈不上运行什么编译器。
交叉编译的基本流程如下:
- 配置交叉编译工具链:交叉编译工具链包括编译器、链接器、头文件和库等,需要根据不同的目标平台和开发平台进行相应的配置。
- 编写源代码:在开发平台上使用适合交叉编译器的编程语言(如C、C++、汇编等)编写源代码。
- 交叉编译:使用交叉编译工具链对源代码进行编译、连接和优化,生成适合目标平台的可执行文件。
- 调试和测试:在目标平台上进行调试和测试,以确保软件能够正常运行并满足需求。
需要注意的是,在进行交叉编译时,需要考虑到不同平台之间的差异性,如字节序、寄存器结构、库文件等,避免因为平台差异而导致编译出的可执行文件无法在目标平台上运行。因此,在进行交叉编译前,需要仔细考虑目标平台和开发平台的差异,并根据实际情况进行相应的配置和调整。
常见的交叉编译例子有:
1. 在PC上编译ARM嵌入式系统的应用程序:使用arm-none-linux-gnueabi-gcc交叉编译工具。
2. 在PC上编译MIPS嵌入式系统的应用程序:使用mipsel-linux-gnu-gcc交叉编译工具。
3. 在Windows上编译Linux应用程序:使用MinGW交叉编译工具。
4. 在Windows上编译Android应用程序:使用Android NDK交叉编译工具。
5. 在Mac上编译iOS应用程序:使用Xcode IDE中的Clang编译器和SDK进行交叉编译。
交叉编译需要在开发者所在的平台上安装相应的交叉编译工具链,并进行配置后才能进行。交叉编译在嵌入式系统、移动设备、云计算等领域中得到广泛应用,可以快速地生成可在目标平台上运行的程序,提高了软件开发的效率和代码的可移植性。
中断
中断是计算机处理器(CPU)中的一种机制,用于实现异步事件的响应和处理。当外部设备需要通知处理器发生了某个事件时,会采用中断方式向处理器发送信号,使处理器暂停当前正在执行的进程,转而去执行与中断相对应的中断处理程序。中断可以让计算机实现多任务处理,提高计算机系统的效率和响应速度。
在Linux系统中,中断分为硬件中断和软件中断两种类型。
硬件中断通常是来自外部设备的信号,例如键盘、鼠标、网卡等设备。当外部设备执行某个操作时,会向处理器发送中断请求信号。处理器接收到中断请求后,停止当前的任务运行,并执行与中断相关联的中断处理程序。中断处理程序会对设备进行处理,处理完成后将程序控制权交还给原始的进程,恢复进程执行。
硬件中断的实现是通过中断控制器和中断向量表来完成的。中断控制器负责接收和管理中断请求,中断向量表则记录了每个中断源的中断处理程序地址。当处理器接收到中断请求时,中断控制器会将中断请求发送给处理器,并根据中断号查找中断向量表中相应的中断处理程序执行。
硬件中断通常可以分为外部中断、内部中断和异常中断三种类型。
- 外部中断:来自计算机系统外部设备的信号所引起的中断,例如键盘、鼠标、网卡等外设发生了一些特定的事件时会产生外部中断。这种中断是由中断控制器负责管理和分配的,是计算机系统与外部设备之间进行通信的重要途径。
- 内部中断:来自CPU内部的信号引起的中断,例如时钟中断、I/O端口中断等。这种中断不需要外部设备产生中断请求信号,而是由计算机本身内部的硬件部件或者外部硬件设备的指令序列产生的,是计算机硬件组件之间协调工作的必要手段。
- 异常中断:也称为特殊中断,是由于执行指令过程中遇到意外的情况(如算术溢出、非法指令、内存地址越界等)而产生的中断。这种中断是CPU内部的错误处理机制,当CPU遇到异常情况时会停止正常执行流程,并转而执行异常处理程序进行处理。
软件中断是由软件程序触发的中断,例如系统调用、定时器中断等。在Linux系统中,软件中断通常被称为“内核中断”,它们是由内核线程触发和处理的。内核线程会在固定的时间间隔内启动定时器中断程序,以在特定时间执行一些任务,例如更新系统运行状态、进行内存管理等。
需要注意的是,软件中断和硬件中断不同,它不是由外部设备产生的中断信号,而是由内核自身发起的中断请求。因此,在触发软件中断时,不需要像硬件中断那样通过中断控制器进行中断分发和管理,而是直接通过中断向量表查找和执行中断处理程序。
软件中断通常分为系统调用、软中断和定时器中断三类。
- 系统调用:是由用户空间的应用程序向内核发出的请求,请求内核完成某些特定的操作,例如打开、关闭文件、读写文件等。系统调用可以看作是用户空间与内核空间之间的接口,提供了一种安全、可靠的方式让应用程序访问底层系统资源和服务。
- 软中断:是由内核内部的软件组件产生的一种中断,用于实现内核线程之间的通信和协调。软中断通常会在内核的上下文中触发,并执行一些短暂的任务,例如更新内存管理信息、处理网络数据包等。软中断相对于硬中断来说,具有更低的延迟和更高的效率,因此在内核编程中被广泛使用。
- 定时器中断:是由定时器硬件产生的一种中断,可以周期性地触发内核中的任务,例如更新系统状态、删除过期进程等。定时器中断通常会在内核上下文中被处理,因此可以保证高效和精确。
除了这三种常见的软件中断之外,还有一些其他类型的软件中断,例如信号中断、IRQ(Interrupt Request)线程、workqueue等都是在Linux内核中常见的软件中断处理机制。
总之,中断是Linux系统中非常重要的机制之一,用于处理外设事件和操作系统内部事件,提高计算机的响应速度和效率。
当CPU接收到中断请求时,它会进行以下操作:
- 中断处理器暂停当前正在执行的进程,将控制权转移到中断处理程序。
- 保存当前进程的上下文信息,包括程序计数器、寄存器等,以备恢复时使用。
- 确定中断源,并查找与之相关联的中断处理程序。
- 执行中断处理程序,对中断源进行处理。
- 恢复被中断的进程的上下文信息并继续执行。这个过程称为中断返回。
中断向量表(Interrupt Vector Table)是一个固定长度的数据结构,用于存储中断处理程序的入口地址,以响应和处理硬件中断和软件中断。
在x86架构的计算机系统中,中断向量表是一个长度为256个元素的数组(0-255),其中每个元素都包含了一个指向中断处理程序的函数指针。具体而言,中断向量表中存储了如下内容:
- 中断处理程序入口地址:每个元素都包含一个指向中断处理程序的C函数指针,该函数用于响应和处理对应中断号的中断请求。当中断请求发生时,CPU会根据中断号查询中断向量表,并跳转到对应的中断处理程序入口地址开始执行相应的处理代码。
- 中断门描述符:中断门描述符是一种特殊的数据结构,用于描述中断处理程序的属性和状态。它包含了中断类型、DPL(Descriptor Privilege Level)、代码段选择子、中断处理程序入口等重要信息,用于实现安全和可靠的中断处理。
- 系统调用号:在Linux系统中,中断向量表中还包含了一些用于系统调用的特定中断号,例如sysenter和int 80h等,用于实现用户空间与内核空间之间的接口。
由于中断向量表的内容非常重要,因此在操作系统的设计和开发中需要特别注意其正确性和安全性,以确保系统的稳定和可靠运行。
问题:中断能不能进行大数据量的传输?
中断不适合进行大数据量的传输,因为中断是一个异步的、无法预测的事件响应机制,它的执行时间是不可控的,而且频繁地触发中断会对系统性能产生较大影响。如果在中断处理程序中执行大数据量的传输,将会导致中断处理时间过长,从而影响系统的响应速度和稳定性。
相对于中断,数据传输应该放在系统的正常运行流程中完成。操作系统通常采用I/O端口、DMA(直接内存访问)等机制来实现大数据量的传输。其中,DMA可以在不占用CPU时间的情况下,通过直接访问内存进行数据传输,具有高效、稳定的特点,适合用于大数据量的传输。
当然,在某些场景下,中断也可以用于进行少量数据的传输,例如一个字符或一个单词等。但对于大数据量的传输,还是需要采用其他的机制来进行,以保证系统的性能和稳定性。
Linux用户空间与内核空间交互的几种方式
对于进程来说,它既有内核空间(与其他进程共享),也有用户空间(进程私有私有)。不
管是内核空间还是用户空间,它们都处于虚拟地址空间。
内核空间和用户空间交换数据的方式有很多。用户空间发起的有系统调用、proc、虚拟文
件系统等。内核空间主动发起的有get_user/put_user、信号、netlink等。
Linux应用程序与内核程序交互主要有以下几种通信方式:
(1)系统调用
Linux系统下,设备即文件,也因此大部分设备驱动程序都实现了标准的系统接口,如:
● open(),read(),write(), ioctl(), mmap()
● get_user(x,ptr):在内核中被调用,获取用户空间指定地址的数值并保存到内核变量x中。
● put_user(x,ptr):在内核中被调用,将内核空间变量x的数值保存到到用户空间指定地址处
● Copy_from_user() / copy_to_user():主要应用于设备驱动读写函数中,通过系统调用触发
(2)虚拟文件系统
● proc文件系统
● sysfs文件系统
● debugfs文件系统
很多内核程序细节,如中断等,都在proc/目录下有所体现,虚拟文件系统提供了一种便捷的
用户空间和内核空间的交互方式;
(3)内存映像
mmap共享内存。Linux通过mmap的把内核中特定部分的内存空间映射到用户级程序的内存
空间去,从而提供了用户程序对内存直接访问的能力。该方式尤其适合在那些内核和用户空间需要
快速大量交互数据的情况下,如framebuffer设备。
(4)内核程序使用信号通知应用程序
信号在内核里的用途主要集中在通知用户程序出现重大错误,强行杀死当前进程,这时内核
通过发送SIGKILL信号通知进程终止。
信号发送必须要事先知道进程序号(pid),所以要想从内核中通过发信号的方式异步通
知用户进程执行某项任务,那么必须事先知道用户进程的进程号才可以(可以让应用程序通过oictl
函数,把自己的PID主动告诉驱动程序)。而一般内核运行时搜索特定进程的进程号是个费事的工
作,可能要遍历整个进程控制块链表。所以用信号通知特定用户进程的方法很糟糕,一般在内核不
会使用。内核中使用信号的情形只出现在通知当前进程(可以从current变量中方便获得pid)做某
些通用操作,如终止操作等。因此对内核开发者该方法用处不大。类似情况还有消息操作。
(5)从内核空间回调用户程序。
(6)netlink
原文链接:https://blog.csdn.net/lpwsw/article/details/121924000
设备驱动分为三大类:字符设备、块设备、网络设备
1.字符设备
对数据的处理按照字节流的形式进行的,支持顺序访问(是有时间的概念),也可以支持随机访问
典型的字符设备:串口、键盘、触摸屏、摄像头、I2C、SPI、声卡、帧缓冲设备
顺序访问的设备:串口、键盘、触摸屏
随机访问的设备:帧缓冲设备
2.块设备
对数据的处理按照若干个块来进行的。一个块的固定大小512字节、4096字节。这类设备支持随机访问,这种以块和随机访问能够提高数据存储效率。
块设备往往是面向于存储类的设备: nand flash、SD卡、U盘、eMMC、硬盘
3.网络设备
网络设备是比较特殊的,在/dev没有设备文件,它就是专门针对网络设备的一类驱动,其主要作用是进行网络的数据收发。
网络类设备:有线网卡、无线WiFi网卡(RT3070)、无线GPRS网卡、无线4G网卡
应用程序:socket套接字
原文链接:https://blog.csdn.net/qq_45698138/article/details/128506897
字符设备驱动开发的流程
字符设备驱动开发步骤:
1. 驱动模块的加载和卸载
module_init(xxx_init); //注册模块加载函数
module_exit(xxx_exit); //注册模块卸载函数module_init函数用来向 Linux内核注册一个模块加载函数,参数 xxx_init就是需要注册的具体函数,当使用“ insmod”命令加载驱动的时候 xxx_init这个函数就会被调用,一般在xxx_init函数里进行一些驱动的初始化工作。
module_exit()函数用来向 Linux内核注册一个模块卸载函数,参数 xxx_exit就是需要注册的具体函数,当使用“ rmmod”命令卸载具体驱动的时候 xxx_exit函数就会被调用,在xxx_exit里面就需要对驱动程序的卸载做一些回收工作。
2. 字符设备注册与注销
static inline int register_chrdev(unsigned int major, const char *name, const struct file_operations *fops)
static inline void unregister_chrdev(unsigned int major, const char *name)register_chrdev函数用于注册字符设备,此函数共有三个参数:
- major:主设备号,linux每个设备都有一个设备号,设备号分为主设备号和次设备号。
- name:设备名字,指向一串字符串。
- fops:结构体file_operations类型指针。
unregister_chrdev函数用于注销字符设备,此函数共有两个参数:
- major:要注销的设备对应的主设备号。
- name:要注销的设备对应的设备名。
3. 实现设备的具体操作函数
对具体设备驱动功能实现需要分析其需求,也就是构造file_operation结构体,对file_operations结构体成员进行实例化。
//初始化file_operations结构体
static struct file_operations test_fops=(void)
{
.owner = THIS_MODULE,
.open = chrtest_open,
.read = chrtest_read,
.write = chrtest_write,
.release = chrtest_release,
};4. 设备号的分配
为了方便管理, Linux中每个设备都有一个设备号,设备号由主设备号和次设备号两部分组成,主设备号表示某一个具体的驱动,次设备号表示使用这个驱动的各个设备。 Linux提供了一个名为 dev_t的数据类型表示设备号, dev_t定义在文件 include/linux/types.h里面,定义如下:
typedef __u32 __kernel_dev_t;
typedef __kernel_dev_t dev_t;可以看出 dev_t是 __u32类型的,而 __u32定义在文件 include/uapi/asm-generic/int-ll64.h里面,定义如下:
typedef unsigned int __u32;综上所述, dev_t其实就是 unsigned int类型,是一个 32位的数据类型。这 32位的数据构成了主设备号和次设备号两部分,其中高12位为主设备号, 低 20位为次设备号。因此 Linux系统中主设备号范围为 0~4095,所以大家在选择主设备号的时候一定不要超过这个范围。
4.1静态分配设备号
静态分配号,可以由开发者自己确定设备号,但是会有可能指定到一个正在使用的设备号,这是静态分配设备号的缺点。在确定设备号前,可以先查看设备号是否被使用,可以用cat /proc/devices查看。
int register_chrdev_region(dev_t from, unsigned count, const char *name)- from:要释放的设备号
- count:表示从from开始,要释放的设备号数量
- name:设备名字
4.2动态分配设备号
动态分配设备号有系统分配一个未被使用的设备号,这样也就不会造成冲突了,但是缺点就是分配之后的设备号到底是多少,是不确定的。
int alloc_chrdev_region(dev_t *dev,unsigned baseminor,unsigned count,const char *name)- dev: 保存申请到的设备号
- baseminor:此设备号的起始地址,alloc_chrdev_region可以申请到一端连续的多个设备号,这些设备号的主设备号都一样,但是次设备号不同,次设备号以baseminor为起始地址开始递增。一般baseminor为0,所以说此设备号从0开始。
- count:要申请的设备号数量。
void unregister_chrdev_region(dev_t from,unsigned count)原文链接:https://blog.csdn.net/DRAXY/article/details/126117144
块设备驱动的编写
块设备驱动开发步骤:
块设备驱动程序的编写流程同字符设备驱动程序的编写流程很类似,也包括了注册和使用两部分。但与字符驱动设备所不同的是,块设备驱动程序包括一个request请求队列。它是当内核安排一次数据传输时在列表中的一个请求队列,用以最大化系统性能为原则进行排序。
1. 块设备驱动程序注册
块设备要想被内核知道其存在,必须使用内核提供的一系列注册函数进行注册。驱动程序的第一步就是向内核注册自己,提供该功能的函数是
int register_blkdev(unsigned int major, const char *name);- 参数是该设备使用的主设备号及其名字,name通常与设备文件名称相同,但也可以是任意有效的字符串。
- 如果传递的主设备号是0,内核将分派一个新的主设备号给设备,并将该设备号返回给调用者。
- 使用该函数,块设备将会显示在/proc/devices。
对应的注销函数为
int unregister_blkdev(unsigned int major, const char *name);2. 磁盘注册
通过注册驱动程序我们获得了主设备号,但是现在还不能对磁盘进行操作。内核对于磁盘的表示是使用的gendisk结构体, gendisk结构中的许多成员必须由驱动程序进行初始化。
gendisk结构是一个动态分配的结构,它需要一些内核的特殊处理来进行初始化;驱动程序不能自己动态分配该结构,而是必须调用alloc_disk(),参数是该磁盘使用的次设备号数目。
分配一个gendisk结构并不能使磁盘对系统可用。为达到这个目的,必须初始化结构,并调用add_disk。Gendisk中包含了一个指针struct block_ device_ operations * fops ;指向对应的块设备操作函数,接下来看一下block_ device_ operations都有哪些函数需要驱动程序来实现。
3. 块设备操作
字符设备使用file__operations结构告诉系统对它们的操作接口。块设备使用类似的数据结构,在<linux/fs.h>中声明了结构block_ device_ operations。同时块设备在VFS层也提供了统一的标准操作结构file_ operations。
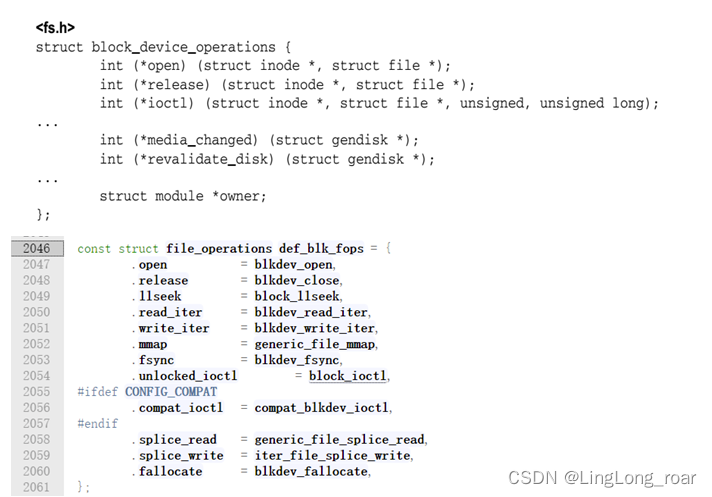
open、release和ioctl 与file_ operations中 等价函数的语义相同, 分别用于打开、关闭文件以及向块设备发送特殊命令(查询设备物理信息,扇区,磁头数)。
4. 请求队列
块设备的读写请求放置在一个队列上,称之为请求队列。gendisk结构包括了一个指针,指向这个特定于设备的队列,由以下数据类型表示。
queue_ head是该数据结构的主要成员,是一个表头,用于构建一个I/O请求的双链表。 链表每个元素的数据类型都是request,代表向块设备读取数据的一个请求。

我们需要为gendisk创建并初始化对应的请求队列,函数如下:

该函数的参数是一个需要驱动实现的函数,用来处理该队列中的request和控制访问队列权限的自旋锁。
5. 请求处理
请求队列创建初始化如下所示:

其中request的处理函数my_request编写如下: 主要实现的功能有:
- 使用blk_fetch_request函数获取队列中的request,循环处理队列中的request。
- 获取请求的起始地址与读写扇区数。
- 根据读写的请求不同,分别处理。(因为是用内存模拟的设备,使用memcpy函数直接拷贝数据)
6. 编译加载驱动
编写对应的Makefile文件,使用make命令,编译生成.ko文件。
7. 格式化磁盘
使用ext4文件系统格式化设备myramdisk,格式化的过程中可以看到打印出的每一次request处理的信息。
8. 挂载设备
最后使用mount命令将设备挂载到/mnt目录下,就可以像其他设备一样进行数据的读写操作。 为什么一个设备已经被系统识别在/dev下,为什么不能直接访问,而需要继续mount。 原因在于,设备文件只能读取设备自身的一些基本信息。 如果读取内部数据的话,由于块设备支持文件系统,很多设备的文件系统并不一样没法直接读取。 必须得按照一定的格式去解析设备里的文件。而mount就按照你指定的格式去读取设备里的数据。
原文链接:http://kerneltravel.net/blog/2020/io_sys_szp_no5/
存储
1、ROM(Read Only Memory,只读存储器)和RAM(Random Access Memory,随机存取存储器)指的都是半导体存储器,ROM在系统停止供电的时候仍然可以保持数据,而RAM通常都是在掉电之后就丢失数据。
2、RAM分为两大类:SRAM和DRAM。
SRAM为静态RAM(Static RAM/SRAM),SRAM速度非常快,是目前读写最快的存储设备,但是它也非常昂贵,所以只在要求很苛刻的地方使用,譬如CPU的一级缓冲,二级缓冲。
DRAM为动态RAM(Dynamic RAM/DRAM),DRAM保留数据的时间很短,速度也比SRAM慢,不过它还是比任何的ROM都要快,但从价格上来说DRAM相比SRAM要便宜很多,计算机内存就是DRAM的。RAM价格相比ROM和FLASH要高。
3、FLASH存储器又称闪存,它结合了ROM和RAM的长处,不仅具备电子可擦除可编程(EEPROM)的性能,还不会断电丢失数据同时可以快速读取数据(NVRAM的优势),U盘和MP3里用的就是这种存储器。
问题:目前手机用的是哪种DDR?
目前手机主要使用的是 LPDDR4(Low Power DDR4) 和 LPDDR3(Low Power DDR3)两种类型的内存,它们都是基于 DDR4 和 DDR3 标准设计的低功耗型内存,能够为手机等移动设备提供更高的带宽和更低的能耗。
相对于 LPDDR3,LPDDR4 内存的主要区别在于以下几个方面:
- 更高的带宽:LPDDR4 内存采用了更高频率的时钟,从而实现了更高的数据传输速率,其理论峰值带宽达到了 4266 MB/s。这比 LPDDR3 内存的峰值带宽提高了很多。
- 更低的功耗:LPDDR4 内存采用了更加先进的制程技术,能够在低电压下运行,从而降低了功耗。此外,LPDDR4 内存还支持更多的低功耗模式,能够在手机等移动设备的待机等场景下,进一步降低功耗,延长续航时间。
- 更强的稳定性:LPDDR4 内存采用了更加严格的校验和纠错机制,能够检测和修复更多的内存错误,从而提高系统稳定性和可靠性。
- 更大的容量支持:LPDDR4 内存能够支持更大的内存容量,最高可达到 16GB,这意味着手机等移动设备能够运行更加复杂和庞大的应用程序。
总之,相较于 LPDDR3,LPDDR4 内存在带宽、功耗、稳定性和容量支持等方面都有了明显的提升,能够为手机等移动设备提供更好的性能和用户体验。
1. 内存映射
由于所有用户进程总的虚拟地址空间比可用的物理内存大很多,但实际上大多数程序只占用实际可用内存的一小部分,因此只需要将最常用的部分与物理页帧关联。在将磁盘上的数据映射到进程的虚拟地址空间的时,内核必须提供一个数据结构,以建立虚拟地址空间和实际物理地址空间的相关数据所在位置之间的关联,linux软件系统多级页表映射机制由此诞生。
注:上图中的最右侧page,代表软件层面的页帧率,并非真正的物理内存。真正的物理内存也会分页,名称为页框,页帧到页框的转换则是由MMU自动完成的。以下讨论均不考虑MMU(MMU完成的工作作为黑箱看待)
Linux的页表实现
问题:页表的存放在哪?
页表存放在物理内存中
问题:每个页表项存储了哪些内容?
每个页表项存储了一个虚拟页号与物理页号之间的映射关系,通常包含以下信息:
- 有效位(Valid Bit):用于标识该页表项是否有效。如果该位为0,则表示该页表项无效,对应的虚拟页并未在物理内存中分配;如果该位为1,则表示该页表项有效,对应的虚拟页已经在物理内存中分配。
- 物理页号(Physical Page Number):用于记录该虚拟页所对应的物理页的页号。物理页是指实际分配给进程的物理内存页面,它的大小通常为4KB或2MB。
- 访问权限(Access Control):用来指定进程对该物理页的访问权限,包括读、写、执行等操作。这些权限是由操作系统在创建一级页表时进行设置的,以保证进程的数据和代码的安全性。
- 脏位(Dirty Bit):用于记录该物理页是否被修改过。如果该位为1,则表示该页被修改过;如果该位为0,则表示该页未被修改过。脏位通常用于虚拟内存管理,当物理页面需要被替换出去时,操作系统可以根据脏位的值来决定是否需要将其写回到磁盘上。
- 保留位(Reserved Bit):用于未来扩展。
总之,页表项是一种用于管理虚拟地址和物理地址之间映射关系的数据结构,每个页表项中存储了虚拟页号和物理页号之间的对应关系,以及其他一些与页面访问、管理相关的控制信息。
问题:映射方式有哪些?
直接映射,全相联映射,组相联映射。原文链接:https://blog.csdn.net/qq_36334929/article/details/108587172
1. 一级页表
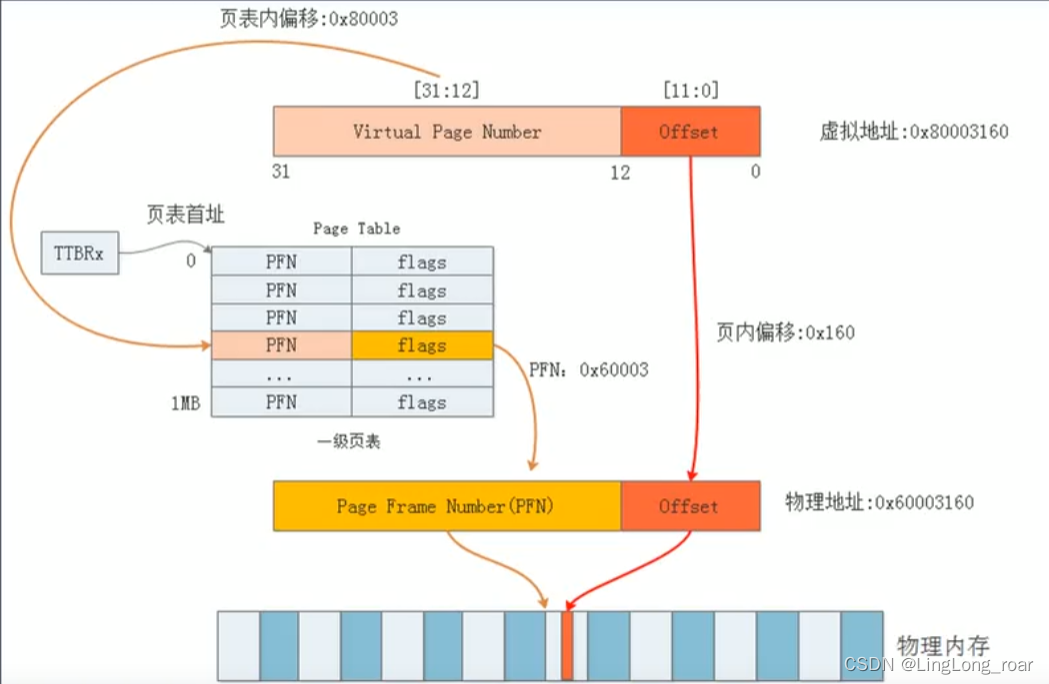
一个32位逻辑地址空间的计算机系统,一个进程分配的虚拟地址空间总大小为4G字节,一个物理页大小为4KB,一级页表的本质就是一个物理页用一个虚拟页做映射,则有4G/4K = 1M个页,那么需要存放1M个条目(一个页需要对应一个条目)。假设每个条目占4B(32位线性地址),则需要4M字节内存来存放页表。
每个进程都需要管理所有4G内存,所以每个进程都要4M来存放页表,极其浪费。
问题1:为什么一级页表在程序开始时要创建所有的页表?
如果分配的页表项不足,那么进程的部分虚拟地址空间就无法映射到物理地址空间上,进程将无法正常运行。所以,在使用一级页表时,需要提前创建好所有的页表项,以确保进程能够正确地使用其完整的虚拟地址空间。
2. 二级页表

虚拟地址到物理页地址的转换过程如下:
- 结合在CR3寄存器中存放的页目录(Page Directory Entry, PDE)的这一页的物理地址,再加上从虚拟地址中抽出高12位叫做页目录表项(内核也称这为PDE)的部分作为偏移, 即定位到可以描述该地址的PDE;
- 从该PDE中可以获取可以描述该地址的页表的物理地址,再加上从虚拟地址中抽取中间8位作为偏移, 即定位到可以描述该地址的PTE;
- 在这个PTE中即可获取该地址对应的页的物理地址, 加上从虚拟地址中抽取的最后12位,即形成该页的页内偏移, 即可最终完成从虚拟地址到物理地址的转换。
其中 虚拟地址的组成:
DIRECTORY [20:31] 可表示4096个页目录(PDE)
TABLE[12:19] 可表示256个页表(PTE)
OFFSET[11:0] 可表示4096个物理内存
因此最大映射物理内存大小为 4096*256*4096 = 4G Byte
二级页表所占用的物理内存:
一级页表PDE: 一共4096项,一个entry 4字节,共4096*4 = 16KB
二级页表PTE: 一共4096个PTE页表,一个PTE页表包含256个页表项Entry,一个entry 4字节,共4096*256*4 = 4MB
所以一共是4MB + 16KB。
但是由于如上所说,一个进程不会映射所有的地址空间,所以二级页表PTE不会全部进行创建,所以实际上不会占用这么多物理内存,但是一级页表的所有页表都需要进行创建。
二级页表的优势:
- 不需要大量连续的物理内存(从PDE寻址到PTE是起始地址+偏移实现的,所以PDE的地址必须是连续的)
- 一个进程不会映射所有的虚拟地址空间,也就不会创建所有的PTE页表。
- 随着页表级数增加,可以节省物理内存。
3. 三级页表
当X86引入物理地址扩展(Pisycal Addrress Extension, PAE)后,可以支持大于4G的物理内存(36位),但虚拟地址依然是32位,原先的页表项不适用,它实际多4 bytes被扩充到8 bytes,这意味着,每一页现在能存放的pte数目从1024变成512了(4k/8)。相应地,页表层级发生了变化,Linus新增加了一个层级,叫做页中间目录(page middle directory, PMD)
办法是针对使用2级页表的架构,把PMD抽象掉,即虚设一个PMD表项。这样在page table walk过程中,PGD本直接指向PTE的,现在不了,指向一个虚拟的PMD,然后再由PMD指向PTE。这种抽象保持了代码结构的统一。
该方法其实就是在原有虚拟地址组成中的几位作为PMD索引:
|31| -----PGD-----|29|-----PMD-----| 20|-----PTE-----|11|----OFFSET|-----|0|
4. 四级页表
硬件在发展,3级页表很快又捉襟见肘了,原因是64位CPU出现了, 比如X86_64, 它的硬件是实实在在支持4级页表的。它支持48位的虚拟地址空间(不过Linux内核最开始只使用47位)。如下:
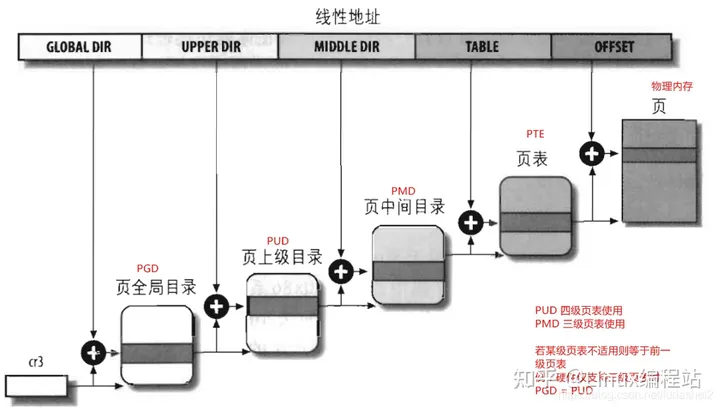
需注意软件的页表映射依赖于硬件所支持的映射级别,目前ARM64支持2/3/4 级映射,假如ARM配置的映射级别为3级,那么linux的映射表中 PGD=PUD,即实际为三级映射。
原文链接:
https://www.cnblogs.com/LyShark/p/15781225.html
2.cache
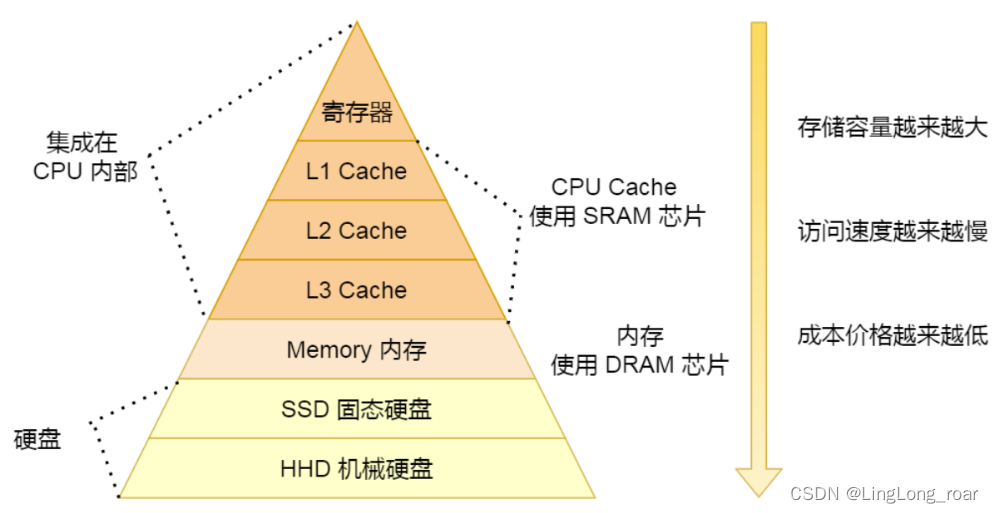
2.1 一二三级缓存(L1\L2\L3)
- L1、L2、L3都是SRAM,即Static RAM,静态RAM,速度很快
- L1、L2、L3速度依次递减,容量依次递增,价格依次递减
- L1、L2、L3都是集成在CPU内部
- 我们常用的内存是DRAM,即dynamic RAM,动态RAM,速度较慢
Cache中存放的是地址和物理地址中的数据(虚拟地址到物理地址的映射表+物理地址中的数据或者物理地址+物理地址中的数据,即虚拟缓存或物理缓存,下文会讲),用来弥补CPU和内存之间的速度鸿沟。因为CPU执行一条指令只需要1ns,而从内存中获取数据需要100ns,这显然拉低了CPU的处理速度,所以提前CPU提前把可能需要用到的数据放入缓存中,需要查找数据的时候先从缓存中查找,查找不到再从内存中查找。而CPU查找数据都是通过虚拟地址进行查找,所以缓存中存放的是虚拟地址到物理地址的映射表和物理地址中的数据。
Cache存储数据是固定大小为单位的,称为一个Cache entry,这个单位称为Cache line或Cache block。给定Cache容量大小和Cache line size的情况下,它能存储的条目个数(number of cache entries)就是固定的。因为Cache是固定大小的,所以它从DRAM获取数据也是固定大小。对于X86来讲,它的Cache line大小与DDR3、4一次访存能得到的数据大小是一致的,即64Bytes。对于ARM来讲,较旧的架构(新的不知道有没有改)的Cache line是32Bytes,但一次内存访存只访问一半的数据也不太合适,所以它经常是一次填两个Cache line,叫做double fill。
每个 Cache line 存储了从主存中传输过来的若干连续字节的数据块,通常的大小为 64 字节,这是因为 CPU 处理器在读取内存时通常会一次性读取 64 字节的数据,将这些数据缓存到 Cache 中,以提高访问效率。
在一个 64 字节的 Cache line 中,包含了以下几个部分:
- 标记(Tag):用于存储该 Cache line 对应的主存地址的高位,通常是由主存地址的高几位进行组合得到的一个标识符。当 CPU 需要访问某个主存地址时,会将该地址的高位与 Cache 内已存在的所有标记进行比较,以判断该地址是否已经被缓存到了 Cache 中。
- 数据(Data):用于存储主存中该 Cache line 对应的数据块,在访问内存时,如果该数据块已经被缓存到 Cache 中,CPU 可以直接从 Cache 中读取数据,而不必再次访问主存,这样可以大大提高访问速度。
- 状态位(Valid Bit & Dirty Bit):用于记录当前 Cache line 的状态信息。其中 Valid Bit 表示该 Cache line 是否有效,Dirty Bit 表示该 Cache line 的数据是否已经被修改过。当 CPU 对 Cache line 进行写操作时,Dirty Bit 会被设置为 1,表示该缓存行中的数据已经被修改过,需要在某个时刻将其写回到主存中。
CPU从Cache拿数据的最小单位是1Byte,Cache从Memory拿数据的最小单位是64Byte,Memory从硬盘拿数据通常最小是4092Byte。
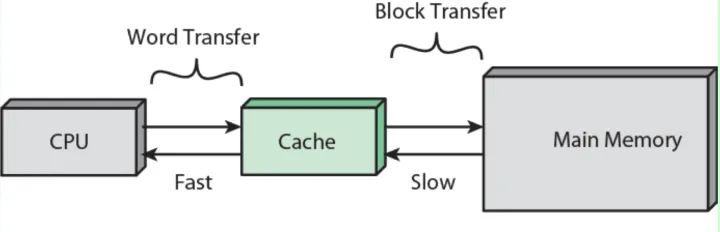
L1缓存通常也分为两种方式,分为指令缓存和数据缓存。指令高速缓存处理有关CPU必须执行的操作的信息,而数据高速缓存则保留要在其上执行操作的数据。
在大多数现代CPU中,L1和L2高速缓存位于CPU内核本身,每个内核都有自己的高速缓存。而L3高速缓存放在CPU裸片上,所有内核共享,并且占用了很大一部分空间。

2.2 TLB(Translation Lookaside Buffer,转译后备缓冲器)
由于CPU首先接到的是由程序传来的虚拟内存地址,所以CPU必须先到物理内存中取页表,然后对应程序传来的虚拟页面号,在表里找到对应的物理页面号,最后才能访问实际的物理内存地址,也就是说整个过程中CPU必须访问两次物理内存(实际上访问的次数更多)。因此,为了减少CPU访问物理内存的次数,引入TLB。
TLB(Translation Lookaside Buffer)是一种高速缓存,用于加速虚拟地址到物理地址的转换过程。在处理器访问内存时,如果需要进行虚拟地址(输入)到物理地址(输出)的转换,则首先会在 TLB 中查找对应的项,以快速确认物理地址。TLB 中主要存储了以下内容:
- 虚拟页号(VPN):指用于识别虚拟地址所属的虚拟页的位字段。TLB 中会记录多个虚拟页号,以便快速找到与之对应的物理页。
- 物理页号(PPN):指虚拟页号最终转换为的物理页号,表示该虚拟页所映射到的物理地址的起始位置。处理器访问内存时,会将虚拟页号替换为对应的物理页号。
- 访问权限位:指用于描述虚拟地址的访问权限的标志位,例如读、写、执行等。
- 超级用户标志位:指用于标识当前内存访问是否属于超级用户特权级别的标志位。
- TTL(Time-to-Live)计数器:指用于记录 TLB 缓存项的存活时间的计数器。当计数器减为零时,表示对应的 TLB 缓存项已过期,需要重新加载。
总之,TLB 中主要存储了虚拟地址到物理地址的映射信息,以及与之相关的访问权限和超级用户标志位。通过提供高速的地址转换服务,TLB 可以显著提高内存访问效率,加速计算机的运行速度。
虚拟地址转换物理地址的过程
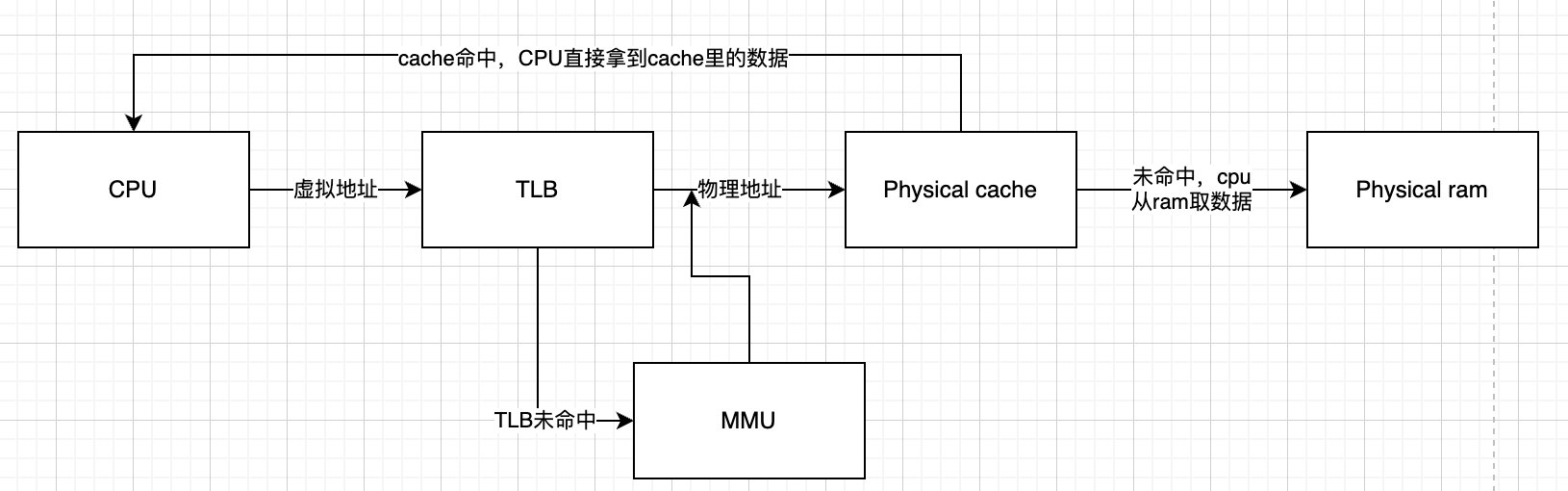
打开mmu后,cpu访问的都是虚拟地址,当cpu访问一个虚拟地址的时候,会通过cpu内部的mmu来查询物理地址,mmu首先在TLB中根据虚拟地址查找物理地址,如果找到相应表项,直接获得物理地址;如果在TLB没有找到,就会通过虚拟地址从页表基地址寄存器保存的页表基地址开始查询多级页表,最终查询到找到相应表项,会将表项缓存到TLB中,然后从表项中获得物理地址,获得物理地址中的数据后,一方面拿走使用,另一方面会放入缓存中,以便再次使用。

TLB可介于CPU和CPU缓存之间,或在 CPU缓存和主存之间,这取决于缓存使用的是物理寻址或是虚拟寻址。如果缓存是虚拟定址,定址请求将会直接从 CPU 发送给缓存,然后从缓存访问所需的 TLB 条目。如果缓存使用物理定址,CPU 会先对每一个存储器操作进行 TLB 查寻,并且将获取的物理地址发送给缓存。两种方法各有优缺点。
物理高速缓存
什么是物理高速缓存?得到物理地址后,使用物理地址查询高速缓存。缺点是CPU只有在查询TLB和MMU后才能访问cache,流水线时间延迟时间相对来说增加了。
缺点:使用物理高速缓存的缺点就是处理器在查询MMU和TLB后才能访问高速缓存,增加了流水线的延迟时间。
虚拟高速缓存
什么是虚拟高速缓存?使用虚拟地址进行寻址cache,无需访问TLB和MMU。
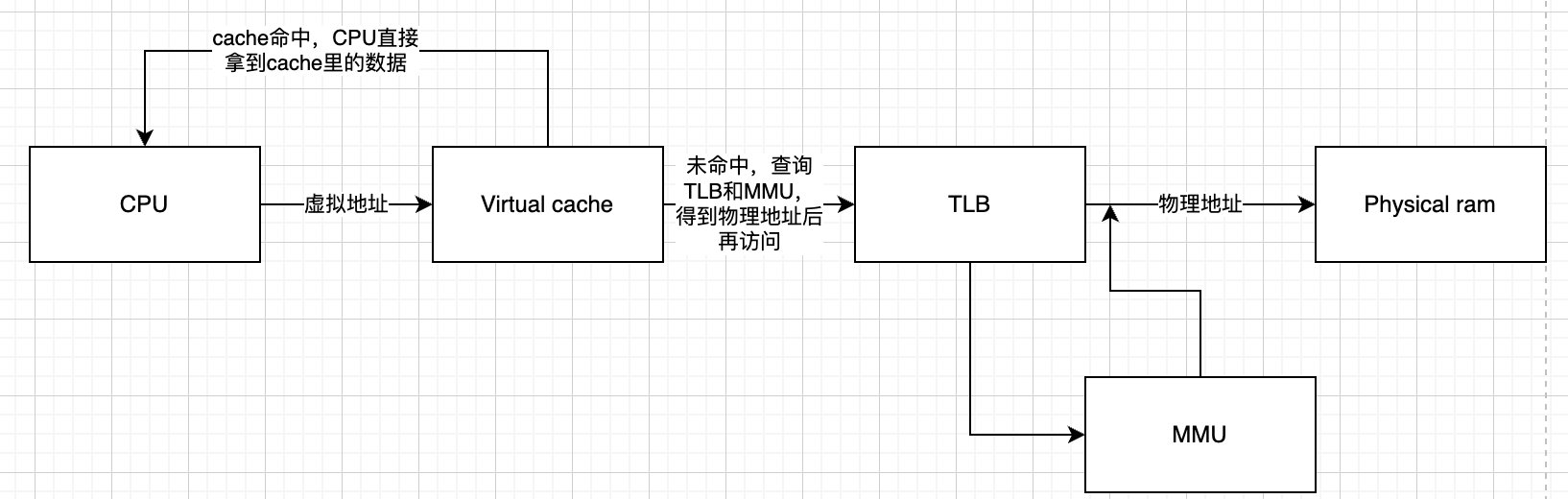
缺点:会引入问题:1.重名(aliasing)问题,2.同名(homonyms)问题
同名问题指的是,在虚拟地址空间中,不同进程或线程可能使用相同的虚拟地址,它们相互独立但使用的是同一个虚拟地址,但是在虚拟缓存中相同的虚拟地址如何找到正确的数据块,以及如何避免冲突,就成了同名问题。
解决同名问题的常用方法是使用标签(tag)来标识不同数据块,标签是一个唯一的、与数据块相关的值,通过查找标签可以快速定位到相应的数据块。在虚拟缓存中,每个数据块通常都有一个相应的标签,标签中包含了数据块所在的物理地址等信息。当发生冲突时,虚拟缓存会根据标签的匹配情况,判断数据块是否存在于缓存中,并进行相应的操作。
重名问题指的是,在不同的虚拟地址空间中,可能存在相同的虚拟地址,而这些地址所对应的物理地址可能是不同的,但是在虚拟缓存中如何找到需要的虚拟地址,以及如何避免冲突,就成了重名问题。
解决重名问题的常用方法是使用虚拟页号(VPN)或者进程标识符等信息来唯一标识不同的地址空间。虚拟缓存通常会为每个地址空间分配独立的缓存区域,即虚拟缓存的“组”,在虚拟地址转换时,根据地址空间标识符和虚拟页号等信息,将相应的数据块保存到对应的组中,并进行快速查找和定位。
总之,同名和重名问题是虚拟缓存中常见的问题,在实现虚拟缓存时需要考虑这些问题,并采取相应的解决方案,以保证虚拟缓存的正确性和性能。
原文链接:https://blog.csdn.net/dai_xiangjun/article/details/120178369
原文链接:https://blog.csdn.net/m0_56561130/article/details/118405261
3. GDT和LDT
GDT和LDT是操作系统中内存管理的两个重要概念,它们都用来描述内存中段的属性和限制。下面分别介绍一下 GDT 和 LDT 的含义和作用:
GDT(全局描述符表)是一个存储在内存中的数据结构,用于描述整个系统范围内的段属性和访问权限。在操作系统启动期间,操作系统会将 GDT 加载到 CPU 的 GDTR 寄存器以便 CPU 访问。GDT 中包含了一组段描述符(Segment Descriptor),用于描述各个段的基地址、大小、属性等信息。通过这些描述符,操作系统可以对不同程序访问内存的行为进行限制,同时还可以实现内存保护和隔离等功能。
GDT是一个系统级别的数据结构,存储着系统中所有段的基本信息,包括:
- 段描述符(Segment Descriptor):每个段描述符包含了该段的基地址、大小、访问权限、段类型等信息,用于描述各个段的属性和限制。
- 选择子(Selector):选择子是用来唯一标识一个段的,每个选择子由一个16位的段选择符和一个指向GDT中对应段描述符的偏移量构成。
- GDTR寄存器:GDTR寄存器是一个48位的寄存器,存储GDT的起始地址和限长信息,通过它可以让CPU访问GDT。
LDT(局部描述符表)是一种用户级别的描述符表,用于描述当前进程的数据和代码段的属性和限制。LDT 类似于 GDT,但是只用于描述当前进程所拥有的段。在进程切换时,操作系统会将新进程的 LDT 加载到 CPU 的 LDTR 寄存器以便 CPU 访问。每个进程都有自己的 LDT,这样可以避免不同进程之间相互干扰或者破坏对方代码或数据段的情况出现。
LDT是一个进程级别的数据结构,存储着当前进程所拥有的段的信息,包括:
- 段描述符(Segment Descriptor):与GDT中的段描述符类似,每个LDT中的段描述符也包含了该段的基地址、大小、访问权限、段类型等信息,用于描述进程中各个段的属性和限制。
- LDT寄存器(LDTR):LDTR寄存器是一个16位的寄存器,存储当前进程的LDT在GDT中的选择子,通过它可以让CPU访问LDT。
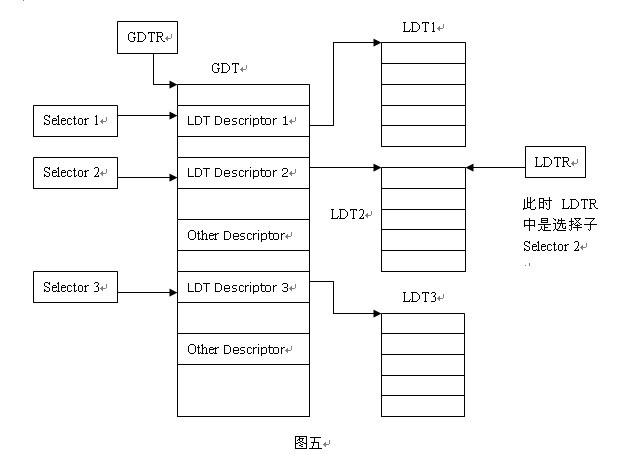
总之,GDT和LDT都是用于描述内存中段的属性和限制,并且都是通过描述符来实现的。GDT描述全局段信息,而LDT描述局部(进程)段信息。通过使用 GDT 和 LDT,操作系统可以更加灵活地管理内存资源,从而提高安全性和可靠性。
参考链接:https://blog.csdn.net/qq_42762094/article/details/120423812
4. DMA buffer
DMA(Direct Memory Access,直接内存访问)是一种计算机系统中的数据传输方式,它可以在不占用CPU的情况下,直接将数据从外设传输到内存或从内存传输到外设。
DMA主要由以下几个部分组成:
- DMA控制器:负责控制DMA传输的开始、停止和中断等操作。
- DMA通道:每个DMA通道都可以连接一个外设,负责与外设进行数据传输。
- DMA缓冲区:用于存储传输的数据,可以是内存中的一段区域或者是专门的DMA缓存器。
DMA的工作流程如下:
- CPU把需要进行数据传输的内存地址、大小、方向等信息写入DMA控制器的寄存器中,并向DMA控制器发送DMA请求,请求指定的DMA通道进行数据传输。
- DMA控制器接收到DMA请求后,判断是否有空闲的DMA通道可用,如果有则分配给CPU请求的DMA通道,开始控制系统总线,进入DMA模式。
- DMA通道连接到外设,DMA控制器通过总线直接访问系统内存,并将数据传输到指定的目的地址。
- 数据传输完成后,DMA通道向DMA控制器发送中断请求,通知CPU数据已经传输完成。
- CPU接收到中断请求后,处理中断并继续执行其他任务。
需要注意的是,DMA传输过程中不需要CPU参与,因此可以大大提高数据传输的效率。同时,DMA传输也有一定的局限性,比如只能进行简单的数据传输,不能进行复杂的数据处理等。
DMA技术的应用广泛,比如在视频处理、音频处理、网络传输、磁盘存储等领域都有着重要的作用。但同时,由于DMA可以直接访问内存,如果没有进行有效的安全和隔离措施,可能会导致数据泄露或篡改等问题。因此,在使用DMA技术时,必须采取相应的安全措施来保护系统安全。
具体来说,高通框架中通过硬件DMA引擎来管理主机与设备之间的数据传输。在传输数据时,CPU会将数据缓存在指定的内存区域中,然后通过DMA引擎控制器将数据直接从内存传输到设备,或者从设备读取数据并直接写入内存,避免了CPU参与的繁琐工作,提高了系统效率和响应速度。
高通框架中的DMA引擎支持多个DMA通道,每个通道可以控制一个特定的设备进行数据传输,同时还提供了高速缓存、DMA链表和中断处理等功能,以满足不同场景下的数据传输需求。同时,在安全性方面,高通框架中还采用了诸如内存保护、IOMMU内存映射、DMA流控等技术来保障系统的安全性和可靠性。
问题:DMA分配的内存在物理地址上是连续的吗?
DMA 分配的内存地址是否连续,取决于具体的实现方式。
在一些简单的实现中,DMA 分配的内存可以是连续的物理内存空间,也就是说,DMA 可以像普通 CPU 写入内存一样,线性顺序地写入数据到分配的这段连续物理内存中。
但是,在一些更复杂的或者安全性要求更高的实现中,DMA 分配的内存并不一定连续。例如,为了保障安全性,系统可能会在 DMA 操作时使用内存映射 I/O(MMIO)技术,在主机物理内存和设备 I/O 端口之间建立虚拟地址映射,将 DMA 访问的内存区域映射到不同的物理内存页上,从而提高安全性,并且防止恶意设备访问非法内存区域。
总之,DMA 分配的内存是否连续,取决于具体的实现方法、系统架构和安全策略。
问题:在使用DMA技术时,一般采取哪些安全措施来保护系统安全?
DMA 可能被恶意软件利用进行非法读写内存,或者窃取机密信息等。
为了保护系统安全,可以采取以下一些技术:
- IOMMU(Input-Output Memory Management Unit,输入输出内存管理单元)技术:IOMMU 可以将设备访问地址映射到虚拟地址空间,从而防止 DMA 访问到非法物理地址。通过 IOMMU,可以控制 DMA 操作所涉及的物理地址范围,保护系统中关键数据和代码区域。
- 内存隔离:将不同设备所使用的内存区域进行隔离,防止 DMA 访问到意外的内存区域,避免对操作系统和应用程序造成影响。例如,可以为每个设备分配专门的内存区域,限制它们对其他设备所使用的内存区域的访问。
- 内存加密:对系统内存进行加密,防止 DMA 等攻击手段获取敏感数据。可采用硬件实现或软件实现的加密方式,将敏感数据在内存中加密存储,只有在需要使用时才进行解密操作。
- 及时更新系统补丁:及时更新操作系统和硬件设备的驱动程序以及固件,修补已知的漏洞。
- 启用审计和监控:对系统进行定期审计和监控,检查是否存在异常的 DMA 访问活动。同时,在系统中安装防火墙和入侵检测等安全工具,增强系统的安全性能,保护系统免受恶意攻击。
以上是一些常用的技术来保护系统安全,针对不同场景可以采取不同的措施。
5. ION Buffer
ion buffer是指用于Linux内核Android系统中的一种物理内存管理方法,是基于DMA的一种内存管理方案。Ion(Input Output Memory Management Unit)是一个内存管理器,可以帮助在Android系统中对物理内存进行管理以及共享。Ion能够跨平台地管理内存,降低了内存管理的复杂度和开发难度。
在Android系统中使用ion buffer可以实现以下功能:
- 内存分配:ion buffer可以帮助在Android系统中进行物理内存分配。开发者可以通过调用ion buffer提供的API实现内存的动态分配、回收等功能。
- 内存映射:ion buffer还可以帮助在物理内存和虚拟内存之间建立映射关系,即将物理内存映射到虚拟内存中,从而使得应用程序可以直接操作物理内存,更加高效地管理内存资源。
- 内存共享:ion buffer还支持多个进程之间共享物理内存资源,例如多媒体应用场景下常见的音视频数据共享等。
总之,ion buffer可以帮助开发者更加高效地管理内存资源,从而提高Android系统的性能和稳定性。同时,ion buffer也为开发者提供了较为简单的API,使得内存管理变得更加容易和便捷。
ion buffer提供了多种API来实现动态分配内存的功能。以下是其中几个核心API介绍:
1. ion_alloc:申请连续一段内存空间,并返回物理地址和虚拟地址。函数原型为:
struct ion_handle *ion_alloc(int fd, size_t len, size_t align, unsigned int heap_mask, unsigned int flags);其中,fd是ion设备文件描述符,len是需要申请的内存大小,align是对齐方式,heap_mask是内存类型掩码,flags是内存分配标志位。
2. ion_free:释放已申请的内存,函数原型为:
int ion_free(int fd, struct ion_handle *handle);其中fd是ion设备文件描述符,handle是内存句柄。
3. ion_map:将分配的物理内存映射到用户空间,函数原型为:
void *ion_map(int fd, struct ion_handle *handle, size_t length, unsigned int prot, unsigned int flags, off_t offset);其中fd是ion设备文件描述符,handle是内存句柄,length是映射内存的大小,prot是访问权限,flags是映射标志位,offset是偏移量。
通过这些API,开发者可以方便地实现动态分配内存的功能,并对分配的内存进行管理、操作和释放等操作。同时,在Android系统中,ionbuffer还可以支持多进程之间共享内存资源,极大地提高了应用程序的效率和灵活性。
MMU和IOMMU
IOMMU(Input/Output Memory Management Unit)和MMU(Memory Management Unit)都是用于管理内存映射的设备。
MMU是在CPU内部实现的硬件,主要负责将虚拟地址转换为物理地址,以便CPU能够正确地访问内存。在操作系统中,MMU通常由内核来管理,通过页表等数据结构维护虚拟地址和物理地址之间的映射关系。
IOMMU则相当于是一个专门针对I/O设备的MMU,是一个集成在南桥芯片中的硬件模块,在处理器和外设之间传输数据时使用。IOMMU主要负责管理DMA(Direct Memory Access)操作,确保每个DMA操作只能访问到被授权的内存区域,并防止恶意程序通过DMA接口修改了任意内存位置的数据。这一过程是硬件层面的,因此可以提供高效的内存保护和隔离。
需要注意的是,并不是所有计算机系统都支持IOMMU技术,而且即使支持,也需要在BIOS或UEFI中进行相应的设置才能启用IOMMU功能。
因此,IOMMU和MMU的最大区别就在于它们所管理的内存区域不同:MMU主要管理CPU与内存之间的映射,而IOMMU则主要负责管理外设与内存之间的映射,但它们的基本工作原理是类似的。
mmap
mmap函数原型:
void *mmap{
void *addr; //映射区首地址,传NULL
size_t length; //映射区的大小
//会自动调为4k的整数倍
//不能为0
//一般文件多大,length就指定多大
int prot; //映射区权限
//PROT_READ 映射区比必须要有读权限
//PROT_WRITE
//PROT_READ | PROT_WRITE
int flags; //标志位参数
//MAP_SHARED 修改了内存数据会同步到磁盘
//MAP_PRIVATE 修改了内存数据不会同步到磁盘
int fd; //要映射的文件对应的fd
off_t offset; //映射文件的偏移量,从文件的哪里开始操作
//映射的时候文件指针的偏移量
//必须是4k的整数倍
//一般设置为0
用户空间mmap调用
用户空间读写文件时,需经过内核,数据拷贝多了一次。通过mmap函数,可以建立用户虚拟空间到文件所在物理页的直接映射,建立该映射后,用户操作虚拟地址空间,其实就是直接操作物理地址空间,减少一次用户到内核的数据拷贝。
fd = open(argv[1], O_RDWR);
/* 将文件映射至进程的地址空间 ,mmaped 为文件所在物理页对应的虚拟内存地址*/
mmaped = (char *)mmap(NULL, sb.st_size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
/* 映射完后, 关闭文件也可以操纵内存 */
close(fd);
mmaped[5] = '$';
msync(mmaped, sb.st_size, MS_SYNC)
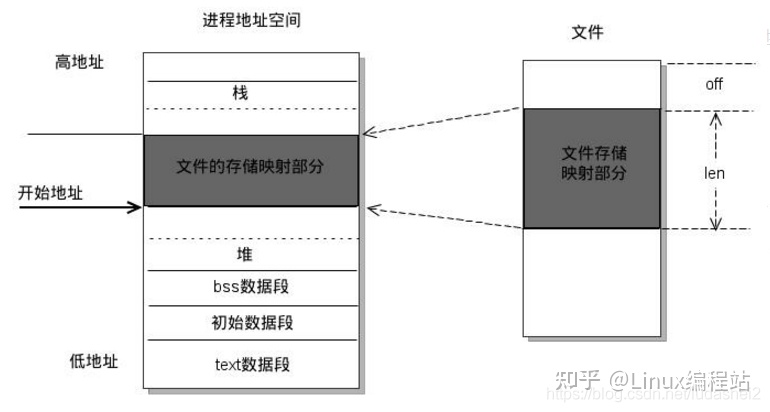
内核空间mmap实现
如framebuffer这种设备需要较高频率大数据读写,因此不能容忍内核空间到用户空间的数据拷贝,因此驱动需开发自己的mmap函数供用户进程调用,驱动mmap实现流程大致为:
- 通过kmalloc, get_free_pages, vmalloc等分配一段虚拟地址。
- 如果是使用kmalloc, get_free_pages分配的虚拟地址,那么使用virt_to_phys()将其转化为物理地址,再将得到的物理地址通过”phys>>PAGE_SHIFT”获取其对应的物理页面帧号。或者直接使用virt_to_page从虚拟地址获取得到对应的物理页面帧号。如果是使用vmalloc分配的虚拟地址,那么使用vmalloc_to_pfn获取虚拟地址对应的物理页面的帧号。
- 对每个页面调用SetPageReserved()标记为保留才可以。
- 通过remap_pfn_range为物理页面的帧号建立页表,并映射到用户空间。
//内存分配
buffer = (unsigned char *)kmalloc(PAGE_SIZE,GFP_KERNEL);
//将该段内存设置为保留
SetPageReserved(virt_to_page(buffer));
//得到物理地址
phys = virt_to_phys(buffer);
//将用户空间的一个vma虚拟内存区映射到以page开始的一段连续物理页面上
remap_pfn_range(vma,
vma->vm_start,
phys >> PAGE_SHIFT,//第三个参数是页帧号,由物理地址右移PAGE_SHIFT得到
vma->vm_end - vma->vm_start,
vma->vm_page_prot)
mmap函数并非实现用户空间与内核空间的交互,而是用户空间试图绕过内核空间,直接操作物理页。
原文链接:https://zhuanlan.zhihu.com/p/536690570
kernel里面有哪些分配内存的方式,又是怎么给到用户态使用的?
Linux内核中实现的内存分配函数有很多,下面列举几个常用的:
1. kmalloc:分配小块连续物理内存。kmalloc调用内核的伙伴算法(Buddy System)来管理物理页面,以保证分配的内存是物理上连续的。虚拟内存地址与真实的物理地址只有一个固定的偏移,因为存在较简单的转换关系,所以对申请的内存大小有限制,不能超过128KB。
2. vmalloc:分配大块的虚拟地址空间。vmalloc将分配的内存映射到虚拟地址空间中的一页页框上,虽然这些页框可能不是物理上连续的,因此对申请的内存大小没有限制,如果需要申请较大的内存空间就需要用此函数了。vmalloc()相比较于kmalloc()效率较低,因为获得的页必须转换为虚拟地址空间上连续的页,必须专门建立页表项。该函数可能睡眠,因此不能从终端上下文中调用,也不能从其他不允许阻塞的情况下进行调用。
3. kzalloc:在kmalloc的基础上用0填充新分配的内存。它在分配时与kmalloc相同,但会自动将新分配的内存清零。
4. krealloc:重新分配一个已经分配的内存块。它可以增加、缩小或移动内存块的大小,并且会保留原内存块中的数据。
除了上述内存分配函数外,Linux内核还提供了一些特殊的内存分配函数,包括:
1. ioremap:将设备物理地址映射到内核虚拟地址空间上。这种内存分配通常用于驱动程序中对设备寄存器的访问,它可以将设备硬件地址映射到内核虚拟地址空间中,并将返回的虚拟地址用于访问设备寄存器。这样就能够避免在内核中直接访问物理设备地址所带来的安全问题。
需要注意的是,使用ioremap时需要小心,因为它会绕过内存保护机制,可能导致系统的安全性问题。因此,在使用ioremap时应该特别注意安全问题,并且只有在需要直接访问硬件寄存器时才使用它。
2. dma_alloc_coherent:为设备分配连续物理内存区域。这种内存分配通常用于驱动程序中进行DMA操作。
一般情况下,内存只有在要被 DMA 访问的时候才需要物理上连续,但为了性能上的考虑,内核中一般使用 kmalloc(),而只有在需要获得大块内存时才使用 vmalloc()。例如,当模块被动态加载到内核当中时,就把模块装载到由 vmalloc() 分配的内存上。
v4l2设备架构
v4l2(Video4Linux2)是一个开源的视频设备驱动程序框架,具有高度的灵活性和可扩展性,能够支持各种视频设备的操作和管理。v4l2框架是Linux内核中一个重要的子系统,在多媒体应用、图像处理等领域得到广泛应用。其主要特点包括:
- v4l2_device:这个是整个输入设备的总结构体,可以认为它是整个 V4L2 框架的入口,充当驱动的管理者以及入口监护人。由该结构体引申出来 v4l2_subdev。用于视频输入设备整体的管理,有多少输入设备就有多少个v4l2_device抽象(比如一个USB摄像头整体就可以看作是一个 V4L2 device)。再往下分是输入子设备,对应的是例如 ISP、CSI、MIPI 等设备,它们是从属于一个 V4L2 device 之下的。
- media_device:用于运行时数据流的管理,嵌入在 V4L2 device 内部,运行时的意思就是:一个 V4L2 device 下属可能有非常多同类型的子设备(两个或者多个 sensor、ISP 等),那么在设备运行的时候我怎么知道我的数据流需要用到哪一个类型的哪一个子设备呢。这个时候就轮到 media_device 出手了,它为这一坨的子设备建立一条虚拟的连线,建立起来一个运行时的 pipeline(管道),并且可以在运行时动态改变、管理接入的设备。
- v4l2_ctrl_handler:控制模块,提供子设备(主要是 video 和 ISP 设备)在用户空间的特效操作接口,比如你想改变下输出图像的亮度、对比度、饱和度等等,都可以通过这个来完成。
- vb2_queue:提供内核与用户空间的 buffer 流转接口,输入设备产生了一坨图像数据,在内核里面应该放在哪里呢?能放几个呢?是整段连续的还是还是分段连续的又或者是物理不连续的?用户怎么去取用呢?都是它在管理。

总之,v4l2框架是一个功能强大的视频设备驱动程序框架,在Linux系统中得到了广泛的应用。通过v4l2框架,开发者可以方便地对接不同类型的视频设备,并实现各种视频数据的获取、处理和显示,从而为多媒体应用和图像处理等领域提供了稳定、高效的支持。
在v4l2框架中,缓存管理是通过数据缓存队列来实现的。具体来说,视频设备通过DMA等方式将视频帧数据传输到缓存队列中,应用程序则从该队列中读取数据进行处理或显示。v4l2提供了一组API来管理缓存队列,包括:
- VIDIOC_REQBUFS:此命令可设置设备请求缓存队列,也就是告诉设备需要多少个缓存空间。
- VIDIOC_QUERYBUF:此命令可查询缓存区,获取缓存区的地址、长度、是否被使用等信息。及从设备端获取数据缓存的指针和大小,以便于开发者在应用程序中进行处理或显示。
- VIDIOC_QBUF:此命令可把已经被应用程序处理后的缓存放回缓存队列。
- VIDIOC_DQBUF:此命令则可以从设备队列中取出一个缓存,以便设备把视频帧数据DMA传输到该缓存中,交由应用程序进行后续处理或显示。
通过这些API,开发者可以方便地进行视频帧数据的缓存管理,使得数据传输效率更高,同时也可以有效地减轻系统负担,提高了多媒体应用和图像处理等领域的运算性能。
原文链接:https://blog.csdn.net/u013904227/article/details/80718831
GPIO用法
GPIO(General Purpose Input Output),通用输入输出。有时候简称为“IO口”。通用,就是说它是万金油,干什么都行。输入输出,就是说既能当输入口使用,又能当输出口使用。端口,就是元器件上的一个引脚。怎么用?写软件控制。
常见用法:
1. GPIO做开关控制,是最常见的应用场景。
2. GPIO做中断
3. 用作按键输入
4. 用作I2C接口,通过软件控制GPIO口拉高拉低来模拟I2C的波形和时序
5. GPIO口输出PWM波,跟当作I2C使用的性质上是一样的。控制GPIO口 定时拉高拉低,就可以输出PWM波形。
6.GPIO用作ADC采样,采集电池电压
原文链接:https://zhuanlan.zhihu.com/p/80096604
CSI与CCI
CSI(Camera Serial Interface)和 CCI(Camera Command Interface)都是与相机图像采集相关的接口协议。但是它们之间有一些区别,下面对它们做一简要介绍:
1. CSI:CSI是一种用于连接图像传感器和处理器(如 SoC 或 GPU)的串行接口协议。它主要负责图像数据的传输,包括同步信号、像素数据、控制信号等。CSI接口可以提供高带宽、低功耗的串行数据传输方式,支持多路并行数据传输。
2. CCI:CCI是一种用于配置和控制相机模块的接口协议。它通过 I2C 总线发送指令来配置相机模块的各项参数,如曝光时间、白平衡、增益等,用于对图像进行预处理或者后处理。
在实际应用中,CSI 接口常常被用于连接 CMOS 摄像头或者 ISP 芯片,而 CCI 接口则用于与 CMOS 摄像头上的芯片进行通讯和控制。例如,在运行 Android 操作系统的移动设备中,CSI 接口通常用于连接摄像头 CMOS 传感器和处理器,而 CCI 接口则用于向 CMOS 芯片发送控制指令,以调整相关参数。

总之,CSI 和 CCI 都是与相机图像采集相关的接口协议,其各自有不同的作用和应用场景。CSI主要用于图像数据传输,CCI主要用于相机控制和参数调整。
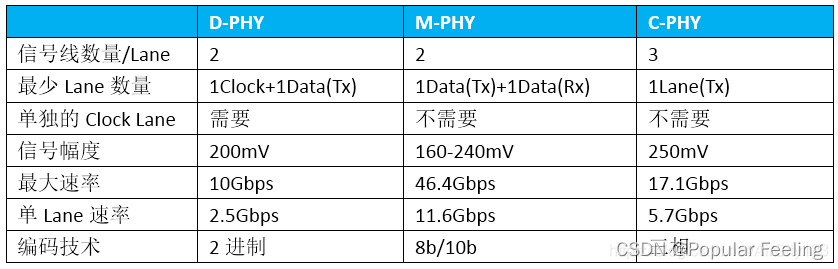
C-PHY 和 D-PHY 是 CSI 协议实现的两种物理层接口。
C-PHY 和 D-PHY 的区别在于工作频率和功耗。
-
传输速率:C-PHY 的最高传输速率可以达到 4.5 Gbps per lane,而 D-PHY 的最高传输速率通常为 2.5 Gbps per lane。因此,C-PHY 的传输速率更快。
-
常用场景:由于 C-PHY 具有传输速率更快、功耗更低、抗干扰性能更好等优势,因此适用于高速传输、低功耗、抗噪声、抗干扰性能要求较高的应用场景,如移动设备中的高分辨率拍照、视频采集和显示等。而 D-PHY 则适合于传输速率要求不高、但相对实现较为简单的场景,如适用于低分辨率、低帧率的图像采集。
-
D-PHY采用DDR(double data rate)的数据传输方式方式,在时钟的上、下沿都有数据传输,它有一条专用的时钟通道;而C-PHY是不需要专用时钟通道,它的时钟信息嵌入在数据本身当中。
-
D-PHY 的时钟信号是单向的,只能由发送端产生并发送给接收端;而 C-PHY 的时钟信号是双向的,发送端和接收端都可以产生时钟信号,并能够实现时钟同步。
虽然 C-PHY 有很多优点,包括更高的传输速率、更低的功耗、更好的抗干扰性能等,但是 C-PHY 也存在以下一些缺点:
-
复杂度较高:C-PHY 的复杂度较高,需要更多的硬件和软件资源来支持它的实现。
-
更高的设计成本:相比 D-PHY,C-PHY 的设计成本更高,因为它需要更复杂的电路设计和更高级别的布线技术。
-
支持程度:目前 C-PHY 的支持程度不如 D-PHY 广泛,应用范围也相对较局限。

此外,C-PHY 和 D-PHY 还有一些其他的区别,包括信号编码方式、传输距离、噪声抑制技术等。具体来说:
1. 信号编码方式:C-PHY 采用多级线性编码技术,可以实现更低的功耗和更广泛的动态范围;而 D-PHY 则采用低压差分信号编码技术,可以实现更高的数据传输速率和更好的抗干扰能力。
2. 传输距离:C-PHY 和 D-PHY 的传输距离也略有不同。通常情况下,C-PHY 的传输距离比 D-PHY 更短,因为 C-PHY 的传输速率较低,对信号传输的损耗也比较小。
3. 噪声抑制技术:CSI 接口采用 C-PHY 或 D-PHY 作为物理层接口时,还需要采用一些噪声抑制技术来提高数据传输的可靠性。例如,在 CSI-2 中,采用了多路差分线和预先编码等技术来降低传输信号的噪声。
综上所述,C-PHY 和 D-PHY 都是 CSI 协议实现的不同物理层接口,它们在工作频率、功耗、信号编码方式、传输距离以及噪声抑制技术等方面具有不同的特点,可以根据不同的应用场景进行选择。
CSI(Camera Serial Interface)是一种串行接口协议,分为以下四层:
1. 物理层(Physical Layer):负责传输电信号和数据,并提供时钟同步、功耗管理等功能。CSI 的物理层包括两种信号编码方式,即 C-PHY和 D-PHY,分别支持不同的数据传输速率。
2. 数据链路层(Data Link Layer):负责数据的传输和接收,包括数据帧的组装、转发、差错检测及纠正等功能。CSI 的数据链路层使用基于字节填充的 8b/10b 编码方式,以确保数据的准确性和完整性。
3. 图像格式层(Image Format Layer):负责定义图像数据的格式和操作,包括图像大小、颜色格式、采样率、压缩方式等。CSI 支持多种图像格式,如 RGB、YUV 等。
4. 控制层(Control Layer):负责传输控制命令和状态信息,包括拍摄模式、曝光时间、白平衡、自动对焦、图像分辨率等参数的设置和查询。CSI 的控制层使用 I2C 接口进行通信,以实现设备之间的控制和配置。
总的来说,CSI 协议的每一层都有自己的作用和功能,通过这些层次的分工协同工作,CSI 协议可以实现高速、稳定、可靠的图像传输和控制。
参考链接:https://blog.csdn.net/daocaokafei/article/details/127825318
YUV420和YUV422的区别
YUV420 和 YUV422 都是数字视频中的色度子采样格式,它们的主要区别在于颜色分量的采样方式以及输出图像的质量和大小。
在 YUV420 中,色度(Cb 和 Cr)分量的采样率比亮度(Y)分量低,即每 4 个亮度样本只有 1 个 Cb 和 1 个 Cr 样本。具体来说,Cb 和 Cr 分量的采样方式是在水平和垂直方向上各隔一个亮度行或列进行采样,这种采样方式称为 4:2:0。由于色度分量的采样率较低,因此 YUV420 的数据量相对较小,适用于存储空间和传输带宽有限的应用场合。但其缺点是色彩信息的精度不如 YUV422,会导致图像细节损失或色块等视觉问题。
而在 YUV422 中,色度分量的采样率比 YUV420 更高,即每 2 个亮度样本只有 1 个 Cb 和 1 个 Cr 样本。具体来说,Cb 和 Cr 分量的采样方式是在水平方向上各隔一个亮度样本进行采样,这种采样方式称为 4:2:2。相比 YUV420,YUV422 的色彩信息更加精确,可以提供更高的图像质量和细节清晰度,但数据量也更大,适用于存储空间和传输带宽相对充足的应用场合。
总之,YUV420 和 YUV422 的区别在于色度分量的采样率不同,导致输出图像的质量和大小存在差异。选择哪种子采样格式应根据应用场景和要求来决定。
怎么从RGB转为灰度图?
从 RGB 转为灰度图有多种方法,其中比较常用的是加权平均法。该方法通过对 RGB 三个分量进行加权平均,得到一个单通道的灰度图像。通常采用下面的公式进行计算:
Gray = 0.299 * R + 0.587 * G + 0.114 * B
其中,R、G、B 分别表示红色、绿色、蓝色分量的值(一般范围在 0~255 之间),0.299、0.587、0.114 是经过调整的归一化系数,是通过对人眼对不同颜色的敏感度进行统计和调整得出的,可以较好地模拟人眼对颜色的感知。
具体转换的步骤如下:
1. 读入 RGB 图像的像素值,按顺序依次取出每个像素(包含 R、G、B 三个分量)。
2. 对于每个像素,使用上述公式计算出它的灰度值,即 Gray,注意需要将结果四舍五入取整后转换为整型数据类型。
3. 将计算得到的灰度值作为像素的值,存储在同样位置的灰度图像中。
4. 重复执行上述操作,直到遍历完整个 RGB 图像,并得到一个灰度图像。
需要注意的是,加权平均法只是一种常见的 RGB 到灰度图的转换方法,其它的转换方法也可以使用。例如,还可以使用亮度平均法、最大值法、最小值法等进行转换。此外,也可以使用现成的图像处理库或软件来实现 RGB 到灰度图的转换。

















 3210
3210

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









