









论文地址:SMACv2
背景:
大部分SMAC图上pymarl2的QMIX版本代码都能达到100%胜率,SMAC对于如今的MARL算法可能不再是一个合适的benchmark。并且现在缺少一种合作MARL benchmark同时具备局部视野、复杂的动态模型、高维状态空间、支持规模比较大的智能体数量。因此Deepmind升级版SMAC为SMACv2,希望为MARL提供一个新的、更难的benchmark。
原SMAC不足:
1、随机性不足:SMAC的初始状态以及状态转移方程相对确定,智能体很可能只需要学习到每一个时间步的最优动作而不需要关注太多其他与时间序列相关的观测信息。论文进行对比试验,对多智能体算法只输入agent_id和time_step的方式(open-loop)以及输入SMAC原始的特征方式(closed-loop)进行算法的对比训练。
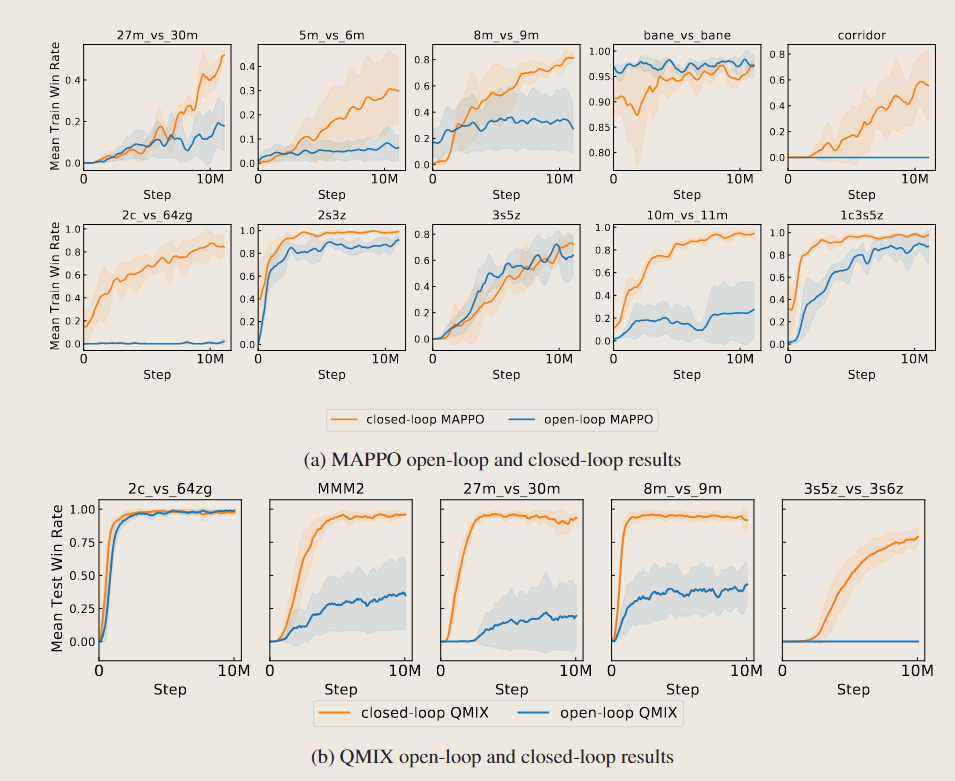
实验结果表明,两个基于Q值以及策略学习的MARL的sota算法,如QMIX和MAPPO依然能在SMAC很多地图上达到不错的性能。
2、原始SMAC存在部分冗余且可推断的特征:SMAC原始特征中部分特征可以由其他特征推断出来,而MARL学习的特征信息之间需要尽可能保持不相关性。SMACv2通过对部分特征信息的mask进行对比试验,证明了原始的SMAC特征中存在一些冗余且很多特征是可推断的。
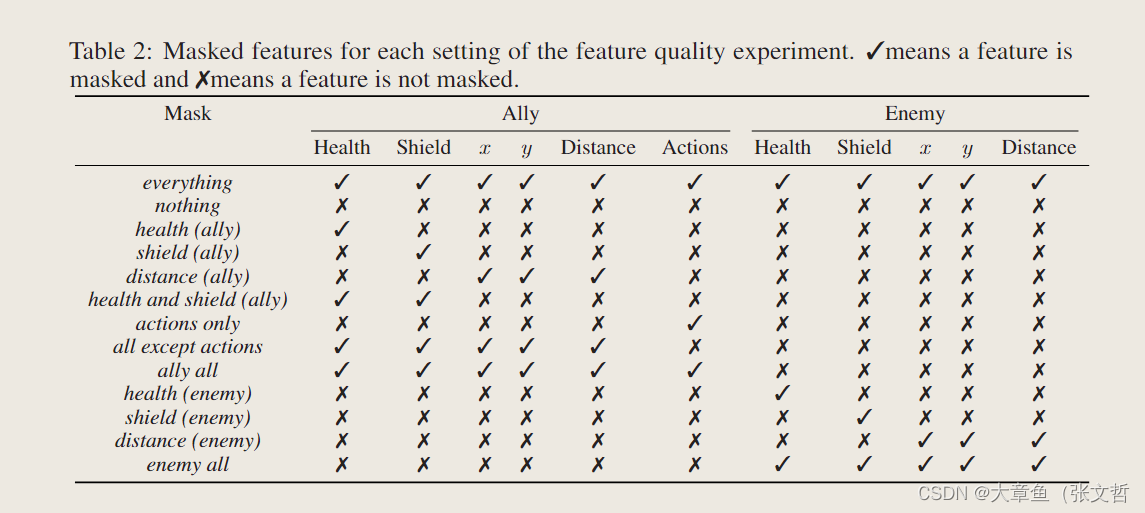
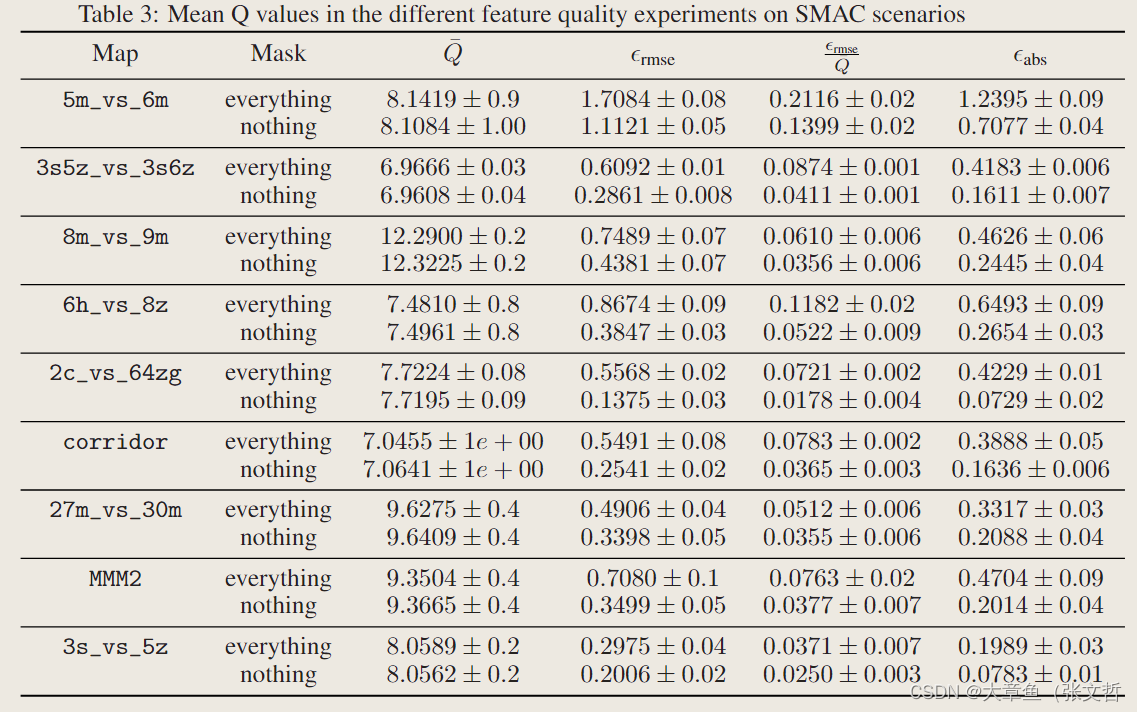
SMACv2改进:
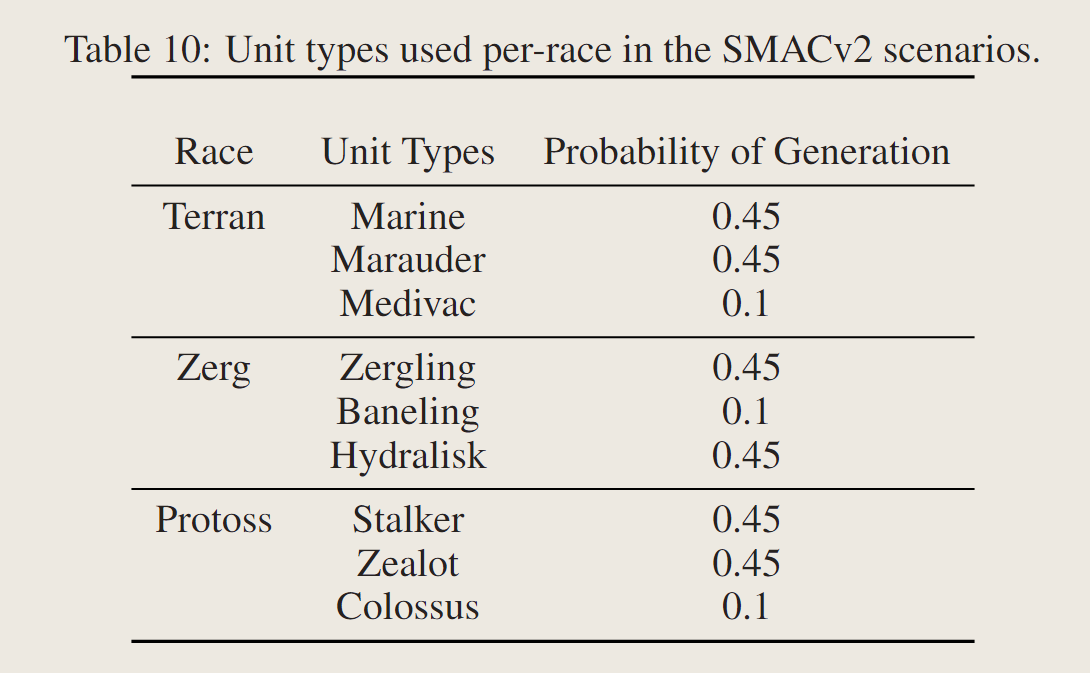
1、智能体的unit type随机生成:原始SMAC的每个智能体的unit type都是固定的,为了增大随机性,SMACv2对于每个智能体以一个固定的概率分布随机生成unit type。具体地,SMACv2对每个种族(神族、人族、虫族)都设置了3种unit type,使得智能体学习到的策略具有适配性。
2、智能体出生位置随机:原始SMAC中智能体在一个episode的初始位置是固定的。SMACv2则随机选择以下两种不同的进攻方式(对称式以及中心围捕式)的一种,进行随机生成对应方的智能体。
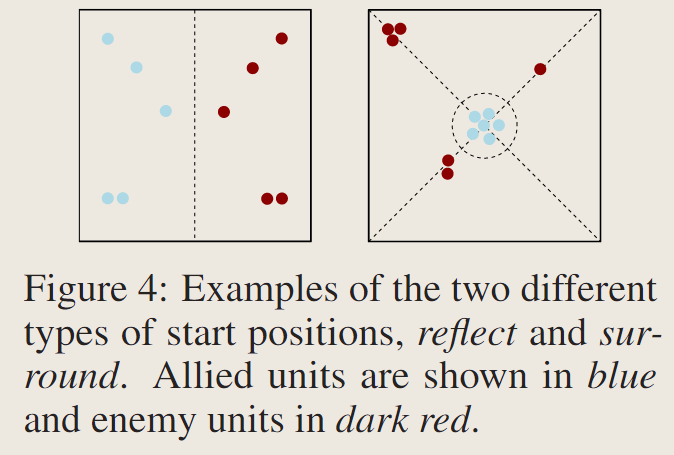
3、视野范围和攻击范围变化:都由原来的360°的圆限制为一个30°的扇形,同时增加12个离散动作来让智能体选择观察的视野区域。
消融结果:
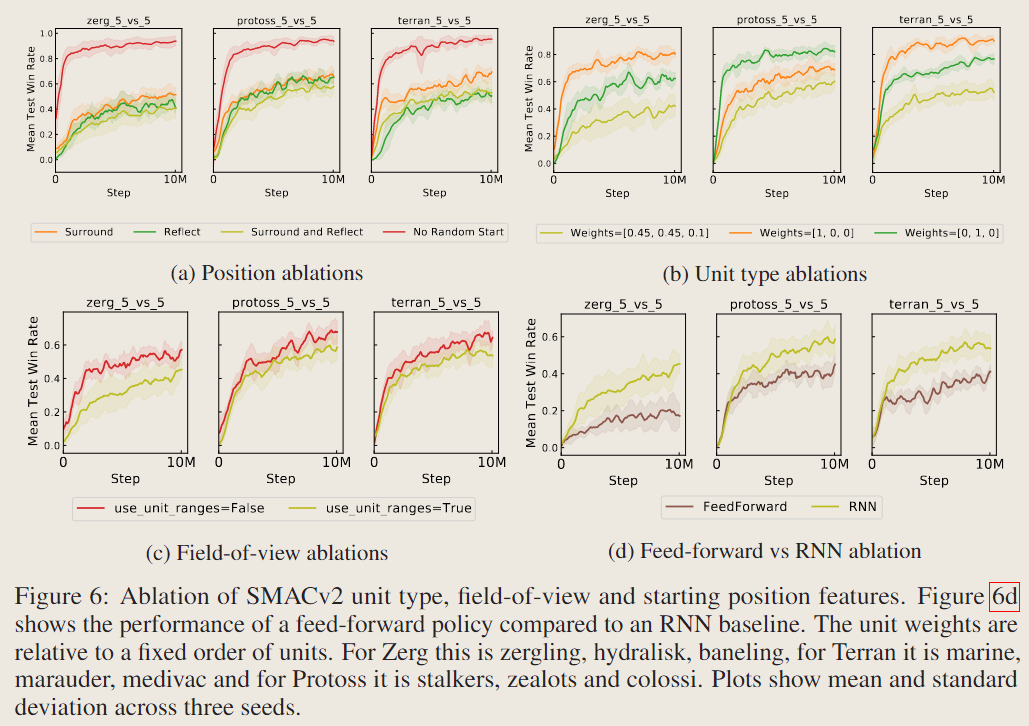
论文实验结果:
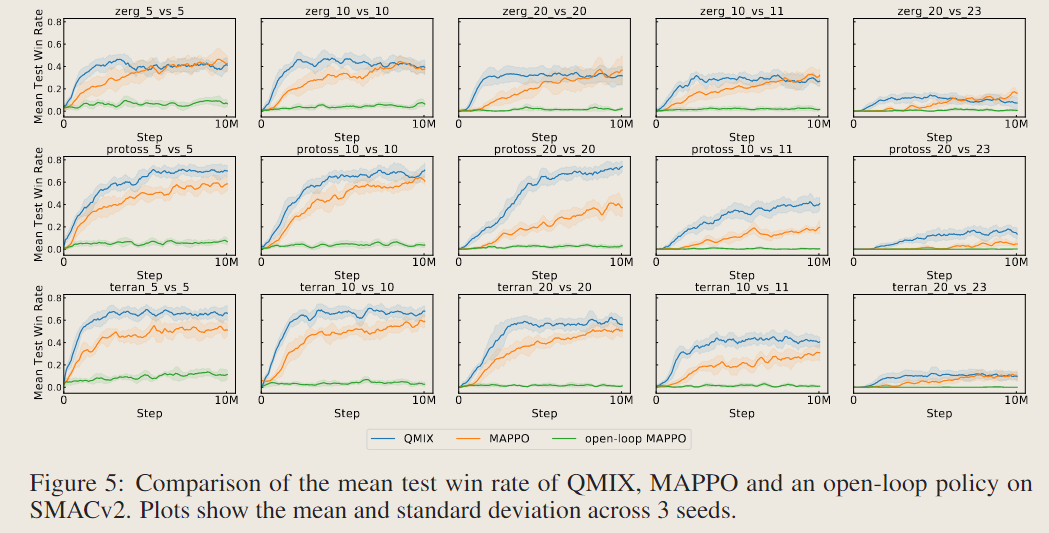
从上面可以看到,sota的MARL算法在所有的地图上都没有达到1.0的性能,SMACv2增大了随机性并加强了部分可观测,很大程度上增大了难度,可作为后续MARL的研究环境。


















 2401
2401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











