







注:
Unimelb Comp90042 NLP笔记
相关tutorial代码链接
序列标注:隐马尔可夫模型
Sequence Tagging:Hidden Markov Models
目录
1 词性标注背景
1.1 Recap
标注前:Janet will back the bill.(珍妮特将支持该法案)
标注后:Janet/NNP will/MB back/VP the/DT bill/NN.
- 上一章我们提到局部分类器会更容易造成错误传播(error propagation)。
- 那如果我们将整句话(整段序列)当做一个类别会怎么样?
- 直接输出:“NNP_MB_VP_DT_NN”,作为单独一类
- 可能会造成以下问题:
- 指数级别的组合, ∣ T a g ∣ m |Tag|^m ∣Tag∣m,其中 m m m是句子单词的数量
- 怎么去标注长度不同的序列?因为 ∣ T a g ∣ m |Tag|^m ∣Tag∣m只能去分类长度为 m m m的句子,当有一个长度为 m − 1 m-1 m−1的句子出现,那就没有一个现有的tag能给它打上标签。
1.2 给出一个更好的方法
标注是一个句子层面的任务(标注一个词需要知道它的上下文),但是人们都是将它拆解成一个个小的单词层面的任务(对每一个单词进行词性标注)。
所以有这么一个解决方法:
- 定义一个模型,它可以把过程拆解成一个个独立的单词层面的任务
- 但同时它在预测和学习的过程中还会考虑到整个序列(整句话),这样就会避免错误传播。
这就是序列标注(sequence labeling)的核心思想,既考虑单词(个体)又考虑句子(整体)。更通俗来说,就是结构预测(structured prediction)。
2 隐马尔可夫模型
2.1 概率模型
- 目的:找到句子
w
w
w最好的句子标签
t
t
t (Tag sequence)
- t ^ = a r g m a x t P ( t ∣ w ) \hat{t} = argmax_tP( t | w) t^=argmaxtP(t∣w)
- 根据贝叶斯可以变换, t ^ = a r g m a x t P ( w ∣ t ) P ( t ) P ( w ) = a r g m a x t P ( w ∣ t ) P ( t ) \hat{t} = argmax_t\frac{P( w | t)P(t)}{P(w)}=argmax_tP(w|t)P(t) t^=argmaxtP(w)P(w∣t)P(t)=argmaxtP(w∣t)P(t)
我们将上述式子中的两个概率公式进行拆解:
P
(
w
∣
t
)
=
∏
i
=
1
n
P
(
w
i
∣
t
i
)
P(w|t)=\prod_{i=1}^nP(w_i|t_i)
P(w∣t)=∏i=1nP(wi∣ti)
- 其中, w w w是一句话, t t t是这句话的tag, w i w_i wi是句子里面的单词, t i t_i ti是每个单词对应的tag。
- 这里我们假设词之间相互独立,并且一个观察到的事件(这里是单词)仅仅依赖于它的 隐藏 状态(这里是tag)
P ( t ) = ∏ i = 1 n P ( t i ∣ t i − 1 ) P(t) = \prod_{i=1}^nP(t_i|t_{i-1}) P(t)=∏i=1nP(ti∣ti−1)
- 马尔可夫假设:当前状态(这里指tag)仅仅只依赖于它先前的状态。
上述两个公式即为 HMM的两个假设,也就是为什么叫 隐 马尔可夫 模型的原因。
2.2 HMM的训练
参数都是独立概率:
- P ( w i ∣ t i ) P(w_i|t_i) P(wi∣ti) 为发射概率(O)
- P ( t i ∣ t i − 1 ) P(t_i|t_{i-1}) P(ti∣ti−1) 为转移概率(A)
目前先简单理解一下:现实中,我们会有一些可见状态,也就是这些状态已经发生了,是确定的。而这些可见状态是依赖于一些隐藏状态,隐藏状态之间会存在转移概率,从隐藏状态到可见状态则存在发射概率。
最大似然估计(MLE)
对HMM的训练会用到最大似然估计,简单地根据单词的标签来统计词频(就像N-gram语言模型一样)
P
(
l
i
k
e
∣
V
B
)
=
c
o
u
n
t
(
V
B
,
l
i
k
e
)
c
o
u
n
t
(
V
B
)
P(like|VB) = \frac{count(VB,like)}{count(VB)}
P(like∣VB)=count(VB)count(VB,like)
P
(
N
N
∣
D
T
)
=
c
o
u
n
t
(
D
T
,
N
N
)
c
o
u
n
t
(
D
T
)
P(NN|DT)=\frac{count(DT,NN)}{count(DT)}
P(NN∣DT)=count(DT)count(DT,NN)
如何处理第一个标签?
因为转移概率中标签会依赖于上一个标签,所以我们需要考虑第一个标签。
假设我们有一个符号 <s> (就和之前文章提到的一样),来表示句子开始,那么就有:
P
(
N
N
∣
<
s
>
)
=
c
o
u
n
t
(
<
s
>
,
N
N
)
c
o
u
n
t
(
<
s
>
)
P(NN|<s>) = \frac{count(<s>,NN)}{count(<s>)}
P(NN∣<s>)=count(<s>)count(<s>,NN),其中分母就是数有多少句句子。
如何处理从未见过的(word, tag) 和 (tag, previous_tag)组合?
这里就用到上一篇提到的 平滑技巧 处理。
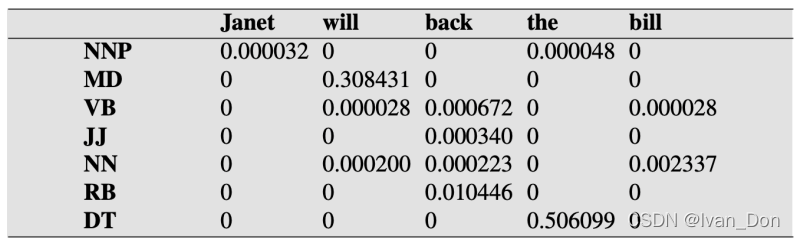
转移矩阵 和 发射矩阵
这是一个没有平滑过的转移矩阵,通过WSJ语料库算出的。第一行表头是当前标签,第一列是上一个标签,即
P
(
V
B
∣
M
D
)
=
0.7968
P(VB|MD)=0.7968
P(VB∣MD)=0.7968
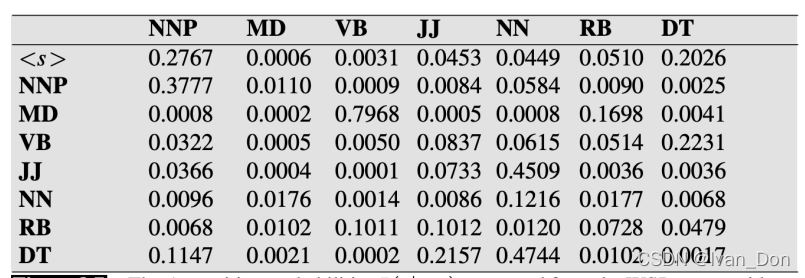
这是一个稍稍做过处理的、没有平滑过的发射(观察)矩阵,也是通过WSJ语料库算出的。
2.3 HMM的预测
t
^
=
a
r
g
m
a
x
t
P
(
w
∣
t
)
P
(
t
)
=
a
r
g
m
a
x
t
∏
i
=
1
n
P
(
w
i
∣
t
i
)
P
(
t
i
∣
t
i
−
1
)
\hat{t} =argmax_tP(w|t)P(t)=argmax_t\prod_{i=1}^nP(w_i|t_i)P(t_i|t_{i-1})
t^=argmaxtP(w∣t)P(t)=argmaxt∏i=1nP(wi∣ti)P(ti∣ti−1)
那怎么找到这个
t
^
\hat{t}
t^ ?如果我们用贪心算法,句子从左到右找到每一个
t
t
t使得
P
(
w
i
∣
t
i
)
P
(
t
i
∣
t
i
−
1
)
P(w_i|t_i)P(t_i|t_{i-1})
P(wi∣ti)P(ti∣ti−1)最大,是不是就可以了?
不可以! 因为我们想要找的是
t
t
t (可以理解为是一组
t
i
t_i
ti,而这组能让概率结果最大),而不是单个
t
i
t_i
ti。这只会是局部最优而不是整体最优,这也正是局部分类器犯的错误。
正确做法:考虑所有的标签组合,然后评估他们再选取最大的。
复杂度:句子长度为
N
N
N,标签数量
T
T
T,那如果考虑所有组合就会有
T
N
T^N
TN 个。
2.4 维特比算法(Viterbi)
为了实现上述寻找总体最大值,那我们就应该想到动态规划。
假设我们现在要对
c
a
n
p
l
a
y
can\ play
can play 做词性标注:
- 对于
c
a
n
can
can 来说,找到它最好的标签很容易:
a
r
g
m
a
x
t
P
(
c
a
n
∣
t
)
P
(
t
∣
<
s
>
)
argmax_tP(can|t)P(t|<s>)
argmaxtP(can∣t)P(t∣<s>)。
因为第一个“tag”总是 “<s>”。我们只需要尝试所有可能的 tags,然后选择使得概率乘积最大的 tag 作为单词 “can” 的 tag。 - 那现在假设 c a n can can 最好的标签是 N N NN NN(名词)。那为了得到 p l a y play play 的标签,我们找到 a r g m a x t P ( p l a y ∣ t ) P ( t ∣ N N ) argmax_tP(play|t)P(t|NN) argmaxtP(play∣t)P(t∣NN),但这是不对的,因为先前提到的局部分类器就是这样,根据前面得出的最优结果来做当前的结果。
- 取而代之,我们应该不断记录 c a n can can 的每一个标签的得分,这样我们可以知道 c a n can can 有不同的标签时, p l a y play play会受到什么样的影响。
例题:
这里可以先看懂,不用跟着计算,后面有小题目可以练手。
假设还是刚刚那句话 Janet will back the bill. 我们用维特比算法过一遍。
1.先看第一行第一列,按照
P
(
w
i
∣
t
i
)
P
(
t
i
∣
t
i
−
1
)
P(w_i|t_i)P(t_i|t_{i-1})
P(wi∣ti)P(ti∣ti−1)带入。
| Janet | will | back | the | bill | |
|---|---|---|---|---|---|
| NNP(专有名词) | P(Janet|NNP) * P(NNP|<s>) | ||||
| MD(情态动词) | |||||
| VB(动词不定式) | |||||
| JJ(形容词) | |||||
| NN(名词) | |||||
| RB(副词) | |||||
| DT(限定词) |
2.还记得前文提到的发射矩阵和转移矩阵吗,这里的概率值我们就可以从矩阵中找到。
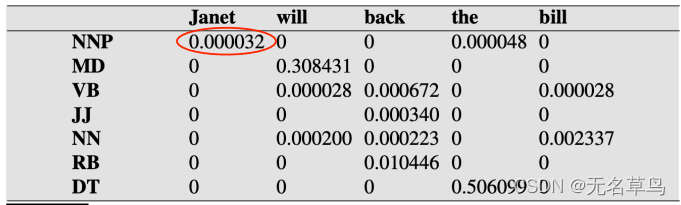
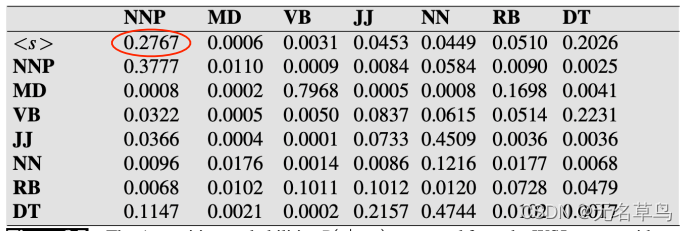
3.因此得出结果,然后我们同样的把第一列全部计算出,但是通过发射矩阵我们发现
J
a
n
e
t
Janet
Janet 除了与
N
N
P
NNP
NNP 的值不是0,其余都是0,所以说在这个表格中,第一列除了第一个其他也都是0:
| Janet | will | back | the | bill | |
|---|---|---|---|---|---|
| NNP(专有名词) | P(Janet|NNP) * P(NNP|<s>) =0.000032*0.2767=8.8544e-6 | ||||
| MD(情态动词) | P(Janet|MD) * P(MD|<s>) = 0 | ||||
| VB(动词不定式) | 0 | ||||
| JJ(形容词) | 0 | ||||
| NN(名词) | 0 | ||||
| RB(副词) | 0 | ||||
| DT(限定词) | 0 |
4.现在开始计算第二列,第二列的话就要考虑到
J
a
n
e
t
Janet
Janet 不同tag的情况下对
w
i
l
l
will
will 的影响会是什么样的。所以我们通过以下公式实现,
公式1:
m
a
x
(
P
(
w
i
l
l
∣
N
N
P
)
∗
P
(
N
N
P
∣
N
N
P
)
∗
s
(
N
P
P
∣
J
a
n
e
t
)
P
(
w
i
l
l
∣
N
N
P
)
∗
P
(
N
N
P
∣
M
D
)
∗
s
(
M
D
∣
J
a
n
e
t
)
…
P
(
w
i
l
l
∣
N
N
P
)
∗
P
(
N
N
P
∣
D
T
)
∗
s
(
D
T
∣
J
a
n
e
t
)
)
=
P
(
w
i
l
l
∣
N
N
P
)
∗
P
(
N
N
P
∣
N
N
P
)
∗
8.8544
e
−
6
\begin{aligned} max(& P(will|NNP)*P(NNP|NNP)*s(NPP|Janet)\\ & P(will|NNP)*P(NNP|MD)*s(MD|Janet)\\ & \dots \\ & P(will|NNP)*P(NNP|DT)*s(DT|Janet)\\ ) &=P(will|NNP)*P(NNP|NNP)*8.8544e-6\\ \end{aligned}
max()P(will∣NNP)∗P(NNP∣NNP)∗s(NPP∣Janet)P(will∣NNP)∗P(NNP∣MD)∗s(MD∣Janet)…P(will∣NNP)∗P(NNP∣DT)∗s(DT∣Janet)=P(will∣NNP)∗P(NNP∣NNP)∗8.8544e−6
从上式可以看到,我们考虑了
J
a
n
e
t
Janet
Janet 是NNP的情况、MD的情况…下,
w
i
l
l
will
will 是 NNP的得分是多少。
注意: 第二列和第一列相比,他还乘上了前一列各项得分。因为我们不能只考虑当前单词的转移和发射,还需要考虑前一个单词在不同tag下的结果如何。
但不巧,这里所有的
P
(
w
i
l
l
∣
N
N
P
)
P(will|NNP)
P(will∣NNP)都为0,所以最后值都为0
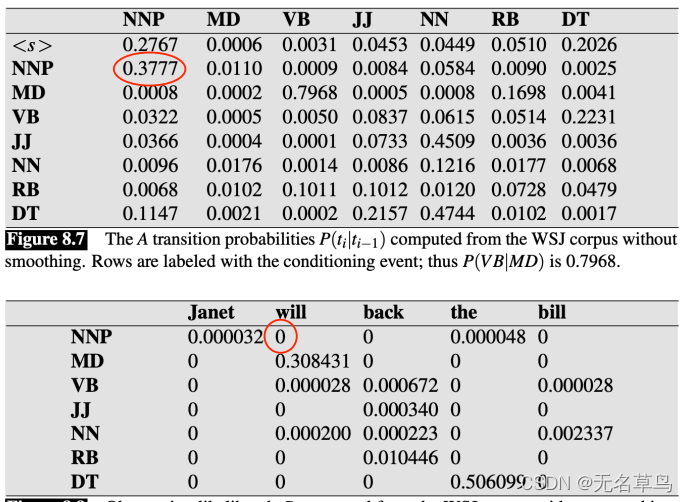
| Janet | will | back | the | bill | |
|---|---|---|---|---|---|
| NNP(专有名词) | 8.8544e-6 | 公式1 = 0 | |||
| MD(情态动词) | 0 | ||||
| VB(动词不定式) | 0 | ||||
| JJ(形容词) | 0 | ||||
| NN(名词) | 0 | ||||
| RB(副词) | 0 | ||||
| DT(限定词) | 0 |
5.接着往下计算,计算
w
i
l
l
will
will和
M
D
MD
MD的值,方法同上。
公式:
m
a
x
(
P
(
w
i
l
l
∣
M
D
)
∗
P
(
M
D
∣
N
N
P
)
∗
s
(
N
P
P
∣
J
a
n
e
t
)
P
(
w
i
l
l
∣
M
D
)
∗
P
(
M
D
∣
M
D
)
∗
s
(
M
D
∣
J
a
n
e
t
)
…
P
(
w
i
l
l
∣
M
D
)
∗
P
(
M
D
∣
D
T
)
∗
s
(
D
T
∣
J
a
n
e
t
)
)
=
P
(
w
i
l
l
∣
M
D
)
∗
P
(
M
D
∣
N
N
P
)
∗
8.8544
e
−
6
=
0.308431
∗
0.0110
∗
8.8544
e
−
6
=
3.004
e
−
8
\begin{aligned} max(& P(will|MD)*P(MD|NNP)*s(NPP|Janet)\\ & P(will|MD)*P(MD|MD)*s(MD|Janet)\\ & \dots \\ & P(will|MD)*P(MD|DT)*s(DT|Janet)\\ ) &=P(will|MD)*P(MD|NNP)*8.8544e-6\\ &=0.308431*0.0110*8.8544e-6 = 3.004e-8 \end{aligned}
max()P(will∣MD)∗P(MD∣NNP)∗s(NPP∣Janet)P(will∣MD)∗P(MD∣MD)∗s(MD∣Janet)…P(will∣MD)∗P(MD∣DT)∗s(DT∣Janet)=P(will∣MD)∗P(MD∣NNP)∗8.8544e−6=0.308431∗0.0110∗8.8544e−6=3.004e−8
| Janet | will | back | the | bill | |
|---|---|---|---|---|---|
| NNP(专有名词) | 8.8544e-6 | 0 | |||
| MD(情态动词) | 0 | 3.004e-8 | |||
| VB(动词不定式) | 0 | ||||
| JJ(形容词) | 0 | ||||
| NN(名词) | 0 | ||||
| RB(副词) | 0 | ||||
| DT(限定词) | 0 |
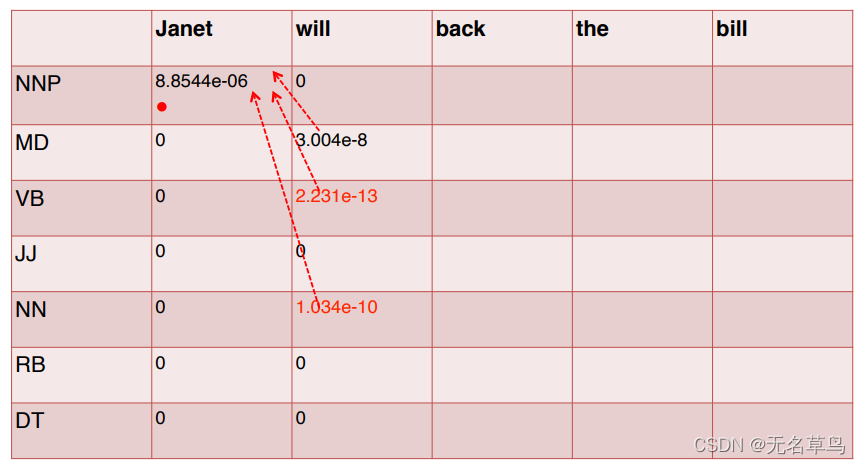
6.这一步很重要,我们要记录当前值是由前面哪一个tag得出来的,也就是
w
i
l
l
will
will和
M
D
MD
MD的值是由
J
a
n
e
t
Janet
Janet是
N
N
P
NNP
NNP得出来。所以我们要在表格上直观地用箭头表示。

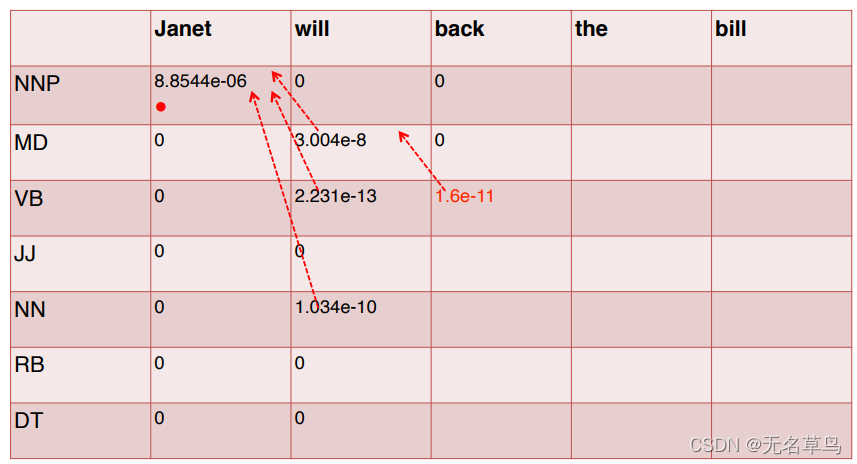
7.后面的计算流程都与上面一致,得出第二列的结果与和第一列的关系。这张图表明,目前使得
w
i
l
l
will
will 值最大的都是由
J
a
n
e
t
Janet
Janet是
N
N
P
NNP
NNP这件事导致的。
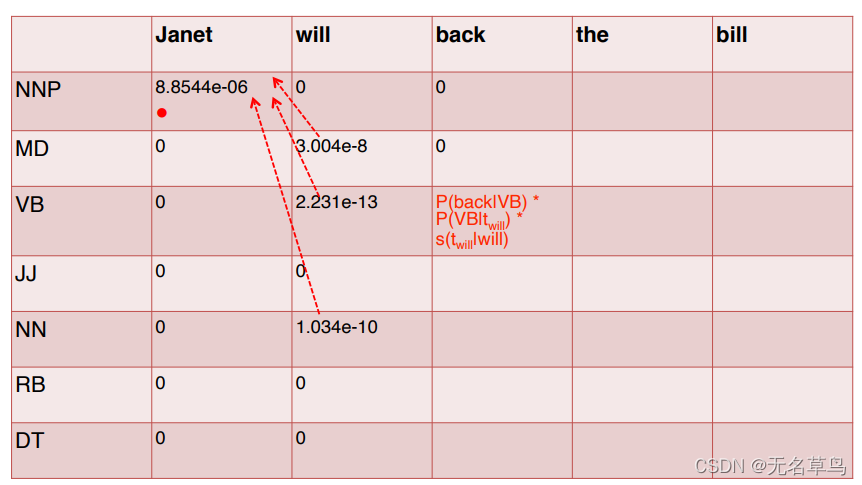
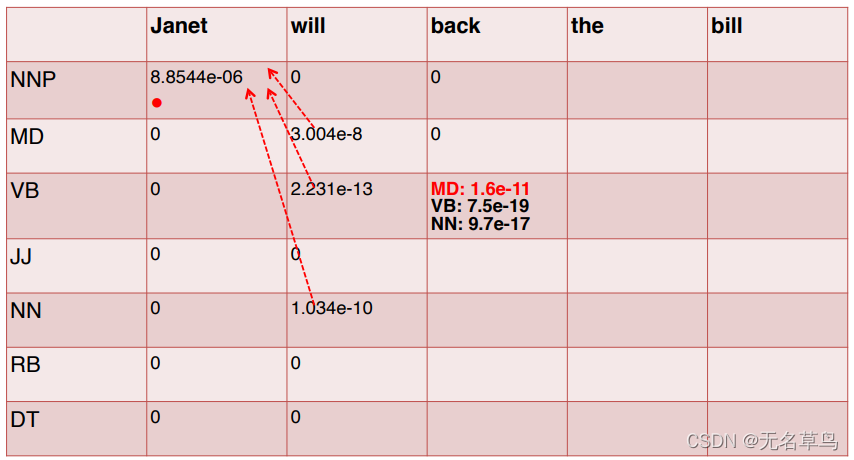
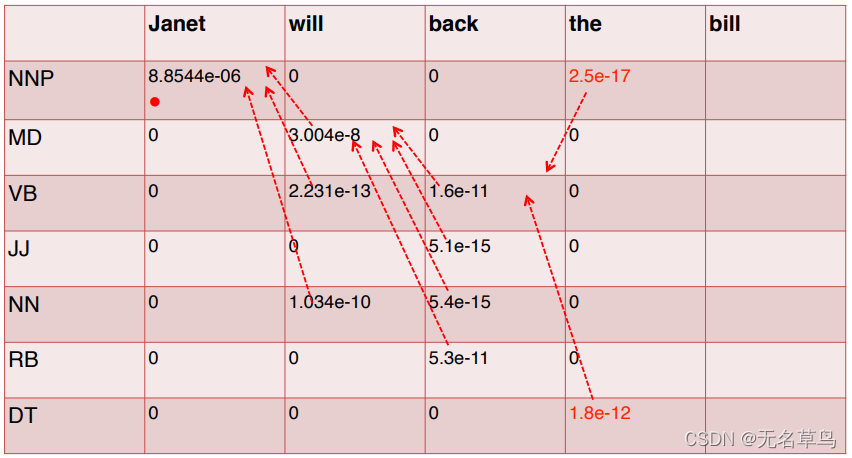
8.把表格填完:

最后一步完成!
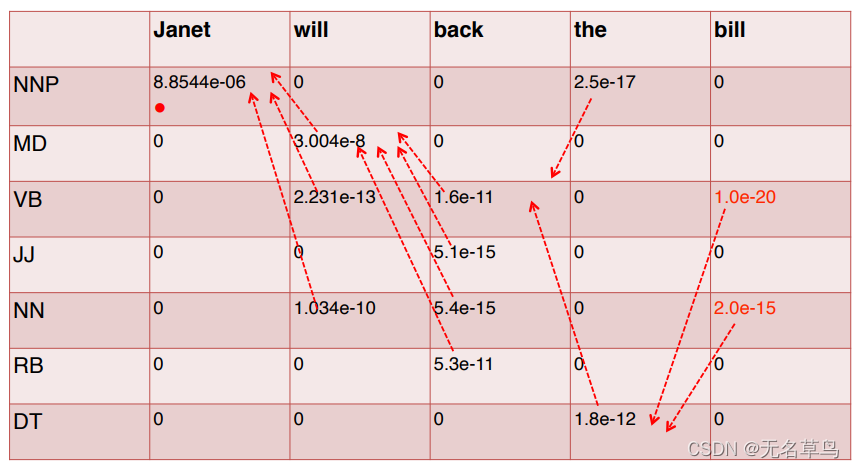
得到这张重要的表格之后,我们就要开始倒推,拿到最好的序列标签了!
很简单,就是从最后一个单词开始,选取最后一个单词中值最大的,然后记录其tag并且跟着箭头往前找。
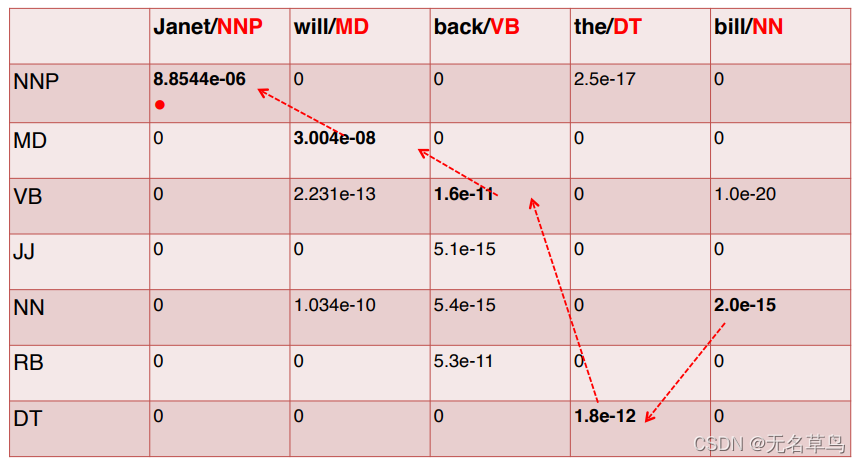
这样就得到了最优的序列标签 NNP, MD, VB, DT, NN
试一试:
对于句子 “They fish”,最优的词性标注是什么?
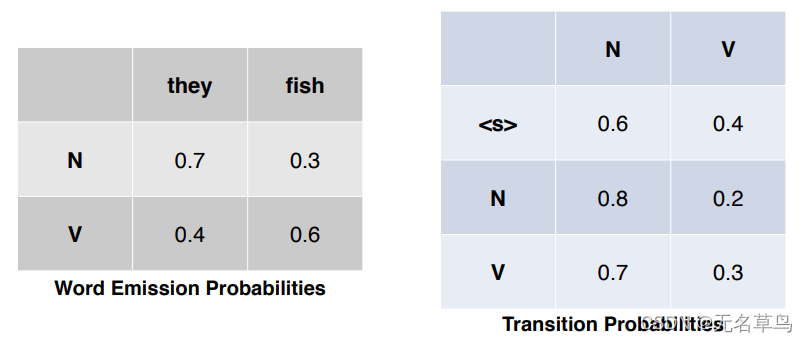
答:
they\N, fish\N

2.4.1 特性
- 复杂度:
O
(
T
2
N
)
O(T^2N)
O(T2N),其中
T
T
T是标签集大小,
N
N
N是句子长度。
T ∗ N T*N T∗N矩阵是发射矩阵大小,然而每个矩阵还要去前面一列最大的值是什么,所以还要遍历 T T T次。 - 为什么维特比可以实现best sequence tag?
因为相互独立的假设分解了问题,如果不是这个假设,我们根本没法实现动态规划。
2.4.2 伪代码

这里将行变成word,列变成tag。
- 在计算概率的时候我们要养成一个好的习惯就是用 log probability 来方式underflow。
- 计算时我们可以采用 向量化(Vectorisation),即用 矩阵-向量 操作替代循环操作,这样可以在一定程度上实现行列级别的并行计算,从而使计算过程加速。
2.4.3 代码
代码中,我们用简单的句子“Janet will back the bill” 和 tag NNP, MD, VB, JJ, NN, RB, DT 为例子。数据完全对应上面给的例子~
import numpy as np
tags = NNP, MD, VB, JJ, NN, RB, DT = 0, 1, 2, 3, 4, 5, 6
tag_dict = {0: 'NNP',
1: 'MD',
2: 'VB',
3: 'JJ',
4: 'NN',
5: 'RB',
6: 'DT'}
words = Janet, will, back, the, bill = 0, 1, 2, 3, 4
# 7 * 7 的 转移矩阵,即 tag和tag
A = np.array([
[0.3777, 0.0110, 0.0009, 0.0084, 0.0584, 0.0090, 0.0025],
[0.0008, 0.0002, 0.7968, 0.0005, 0.0008, 0.1698, 0.0041],
[0.0322, 0.0005, 0.0050, 0.0837, 0.0615, 0.0514, 0.2231],
[0.0366, 0.0004, 0.0001, 0.0733, 0.4509, 0.0036, 0.0036],
[0.0096, 0.0176, 0.0014, 0.0086, 0.1216, 0.0177, 0.0068],
[0.0068, 0.0102, 0.1011, 0.1012, 0.0120, 0.0728, 0.0479],
[0.1147, 0.0021, 0.0002, 0.2157, 0.4744, 0.0102, 0.0017]
])
pi = np.array([0.2767, 0.0006, 0.0031, 0.0453, 0.0449, 0.0510, 0.2026])
# 6 * 5 的 发射矩阵,即 tag * word
B = np.array([
[0.000032, 0, 0, 0.000048, 0],
[0, 0.308431, 0, 0, 0],
[0, 0.000028, 0.000672, 0, 0.000028],
[0, 0, 0.000340, 0.000097, 0],
[0, 0.000200, 0.000223, 0.000006, 0.002337],
[0, 0, 0.010446, 0, 0],
[0, 0, 0, 0.506099, 0]
])
def viterbi(params, words):
pi, A, B = params
N = len(words)
T = pi.shape[0]
# tag行 word列的score表格, 先初始化为负无穷
alpha = np.zeros((T, N))
alpha[:, :] = float('-inf')
backpointers = np.zeros((T, N), 'int')
# base case,也就是<s>的情况,score表格的第一列是不用考虑前面一列的score的
alpha[:, 0] = pi * B[:, words[0]]
# recursive case
# 遍历每一个单词
for w in range(1, N):
# 遍历当前每一个tag
for t2 in range(T):
# 遍历前一个单词的每一个tag
for t1 in range(T):
score = alpha[t1, w-1] * A[t1, t2] * B[t2, words[w]]
if score > alpha[t2, w]:
alpha[t2, w] = score
# 记录当前tag最大值是根据前面哪个tag算出来的
backpointers[t2, w] = t1
# now follow backpointers to resolve the state sequence
output = []
# 根据最后一列中最大的值,找到tag,然后再通过tag反推
output.append(np.argmax(alpha[:, N-1]))
for i in range(N-1, 0, -1):
output.append(backpointers[output[-1], i])
return list(reversed(output)), np.max(alpha[:, N-1])
2.5 实践中的HMM
- 上文讲述的是基于bigram的(也叫first order HMM),但现在最流行的是基于trigram(second order HMM)
- P ( t ) = ∏ i = 1 n P ( t i ∣ t i − 1 , t i − 2 ) P(t) = \prod_{i=1}^nP(t_i|t_{i-1},t_{i-2}) P(t)=∏i=1nP(ti∣ti−1,ti−2),这种情况的话时间复杂度就是 O ( T 3 N ) O(T^3N) O(T3N),因为要找到每一个 t i − 1 , t i − 2 t_{i-1},t_{i-2} ti−1,ti−2组合的最大值。
- 需要处理稀疏性(sparsity):一些标签的trigram序列在现有训练集可能没有,所以可以通过差值来避免
- backoff: P ( t i ∣ t i − 1 , t i − 2 ) = λ 3 P ^ ( t i ∣ t i − 1 , t i − 2 ) + λ 2 P ^ ( t i ∣ t i − 1 ) + λ 1 P ^ ( t i ) , 其 中 λ 1 + λ 2 + λ 3 = 1 P(t_i|t_{i-1},t_{i-2})=\lambda_3\hat{P}(t_i|t_{i-1},t_{i-2}) + \lambda_2\hat{P}(t_i|t_{i-1}) + \lambda_1\hat{P}(t_i),其中\lambda_1+\lambda_2+\lambda_3=1 P(ti∣ti−1,ti−2)=λ3P^(ti∣ti−1,ti−2)+λ2P^(ti∣ti−1)+λ1P^(ti),其中λ1+λ2+λ3=1
- 结合其他特征,HMM在 Penn Treebank上可以达到96.5%的准确率。
2.6 生成式标注器和判别式标注器
生成式模型与判别式模型:简单说,判别式直接计算条件概率,判别式通过联合概率求条件概率。
生成式标注器(Generative Taggers)
HMM是一种生成式标注器,最开始我们想知道当前句子它的最佳tag是什么,所以我们通过拟合
P
(
t
,
w
)
P(t,w)
P(t,w),即这一串tag和这句话的联合概率来求得。而
P
(
t
,
w
)
=
P
(
w
∣
t
)
P
(
t
)
P(t,w)=P(w|t)P(t)
P(t,w)=P(w∣t)P(t),所以才有的以下HMM公式。
t
^
=
a
r
g
m
a
x
t
P
(
t
∣
w
)
=
a
r
g
m
a
x
t
P
(
w
∣
t
)
P
(
t
)
=
a
r
g
m
a
x
t
∏
i
=
1
n
P
(
w
i
∣
t
i
)
P
(
t
i
∣
t
i
−
1
)
\hat{t} =argmax_tP(t|w)=argmax_tP(w|t)P(t)=argmax_t\prod_{i=1}^nP(w_i|t_i)P(t_i|t_{i-1})
t^=argmaxtP(t∣w)=argmaxtP(w∣t)P(t)=argmaxt∏i=1nP(wi∣ti)P(ti∣ti−1)
- 训练过的HMM可以生成数据(句子)
- 允许HMM是无监督学习,不需要标注数据,模型自己学习到句子最有可能的标签。
判别式标注器(Discriminative Taggers)
t
^
=
a
r
g
m
a
x
t
P
(
t
∣
w
)
=
a
r
g
m
a
x
t
∏
i
P
(
t
i
∣
w
i
,
t
i
−
1
)
\hat{t} =argmax_tP(t|w)=argmax_t\prod_{i}P(t_i|w_i,t_{i-1})
t^=argmaxtP(t∣w)=argmaxt∏iP(ti∣wi,ti−1)
判别模式直接就求条件概率,不需要去拟合联合概率。即直接找到“在前一个单词标签为
t
i
−
1
t_{i-1}
ti−1且当前单词是
w
w
w的前提下,当前单词的标签是
t
i
t_i
ti的概率”。
- 支持更丰富的特征集,通常在大量的监督数据集上训练能得到更高的准确率。
- P ( t i ∣ w i , t i − 1 , x i , y i ) P(t_{i}|w_i,t_{i-1},x_{i},y_i) P(ti∣wi,ti−1,xi,yi)
- 判别式模型有最大熵马尔可夫模型(MEMM)、条件随机场(CRF)
- 大部分序列深度学习模型都是判别式
2.7 HMM 在NLP的应用
HMM在词性标注方面效果显著:
-
trigram HMM 能达到 96.5%的准确率
-
相关前沿模型的概率1:
- MEMMs 97%
- CRFs 97.6%
- Deep CRF 97.9%
-
除了词性标注,HMM 还可以应用于其他序列标注任务。
命名实体识别(named entity recognition)、浅层解析(shallow parsing)、对齐(alignment)等等。
其他领域:DNA、蛋白质序列、晶格图像等等。
2.8 总结
- HMM在序列标注方面是简洁有效的
- 快且有竞争力,一般用于其它序列标注模型的baseline
- 主要缺点:与MEMMs和CRFs相比,特征表示方面并不灵活
TODO: 后续会有实际代码
前沿模型概率:https://aclweb.org/aclwiki/index.php?title=POS_Tagging_(State_of_the_art) ↩︎


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









