







 这篇博客探讨了词汇语义学,包括WordNet数据库,同义词集,单词关系,以及如何通过路径长度、父节点深度和信息内容计算单词相似度。此外,还介绍了情感分析中的问题,如同义词和OOV词的处理。无监督和有监督的词义消歧方法也被提及。
这篇博客探讨了词汇语义学,包括WordNet数据库,同义词集,单词关系,以及如何通过路径长度、父节点深度和信息内容计算单词相似度。此外,还介绍了情感分析中的问题,如同义词和OOV词的处理。无监督和有监督的词义消歧方法也被提及。
注:
Unimelb Comp90042 NLP笔记
相关tutorial代码链接
词汇语义学
目录
1 情感分析
- 使用 BOW 和 KNN 分类器:
- 训练数据

- 测试数据
“This is a wonderful film.”
- 训练数据
- 会出现两个问题:
- 该模型不知道 " movie "和 " film "是
同义词。由于 "film "只出现在负面的例子中,模型只会知道它是一个否定词。 - 词汇表中没有 "wonderful "一词(属于OOV - Out-OfVocabulary)。
- 该模型不知道 " movie "和 " film "是
所以说直接对比单词是没有用,那应该怎么去对比单词的词义?
答案:把这些信息通过一个词库明确地添加。
2 单词语义学
可以实现单词词义的对比可以通过两种方式:
- 词汇语义学 (也是这篇文章会讲到的)
- 它能够展现单词和单词之间的意思是怎么相互链接的
- 人工搭建词汇数据库,即人为地把每个单词之间的意思
- 分布式语义学(下一篇会讲)
- 在文本中,单词之间是怎么互相关联的
- 自动从语料库中搭建资源(数据库)
2.1 词汇语义学是什么意思?
- 可以指的是单词的字典定义
- 但是字典定义可能会使循环的
- 只有当前单词意思能够被理解的前提,循环解释才能被理解
- 以下图为例,字典中 red 的解释为 “红宝石或者血的颜色”,然而 blood 的解释却为 “在动物的心脏、动脉循环的红色液体”

- 他们与其他单词的关系
- 因为记录的是单词之间的关系,所以最终也会形成环。但对于文本分析会更有帮助。
定义: 词义描述了词语含义的一个方面。(当一个词有多个词义时,它就是多义词(polysemous))
以 mouse 为例:
- 一个mouse可以控制电脑系统
- 一个安静的动物比如说mouse
通过字典解释的词义
- 术语:由词典提供的文本定义
- Bank ,通过词含义解释
- 一个bank可以在托管账户中持有投资
- 农业在东边的bank蓬勃发展
- Bank ,字典定义
- 接受存款并将资金用于借贷活动的金融机构
- 坡地(特别是水体旁的坡地)
通过关系解释的词义
- 另一种定义词义的方式是看这个单词和别的单词是什么关系
- 同义词(Synonymy):比如 big 和 large,vomit 和 throw up
- 反义词(Antonymy): long 和 short,big 和 little
- 上位词(Hypernymy):is-a 的关系
- 比如 cat is an animal,cat 是 animal 的子集
- 比如 mango is a fruit
- 整体部分关系(Meronymy):整体和部分关系
- 比如 leg is part of a chair
- 比如 wheel is part of car
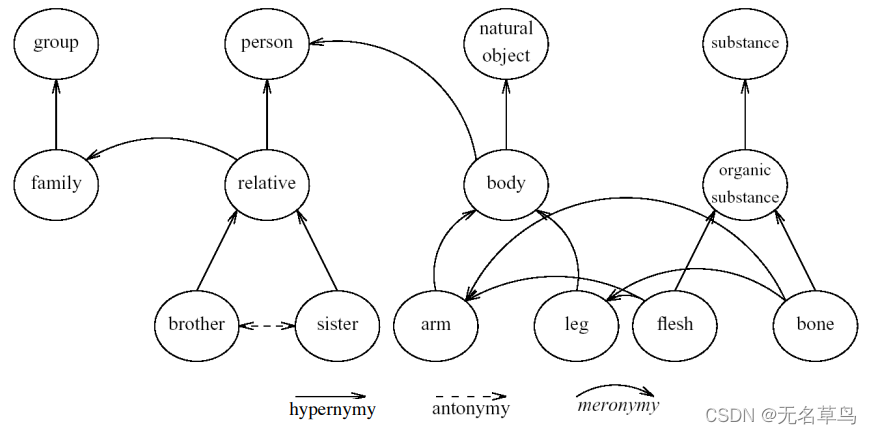
2.2 词网(WordNet)
- 是一个存储词义关系的数据库
- 英语词网包括大约120,000的名词,大约12,000的动词,大约21,000的形容词和大约4,000的副词。
- 平均下来,一个名词会有 1.23 的词义,动词有 2.16 个词义
- 大部分主要语言都有词网(www.globalwordnet.org, https://babelnet.org/)
- 英语词网可以免费使用(之间通过nltk即可)
WordNet 例子
在WordNet中,名词 bass 有8中解释,但其实5个都比较类似,和声音有关,另外3个都和水生动物有关。

2.2.1 同义词集(Synsets)
- WordNet的节点不是词或词干,而是词义。
- 它们由一组同义词,或称synsets来代表
- bass 的 synsets(同一个单词不同的词义都会组成自己不同的synsets):
- {bass1, deep6}
- {bass6, bass voice1, basso2}
- 其他 synset:
- {chump1, fool2, gull1, mark9, patsy1, fall guy1, sucker1, soft touch1, mug2}
- 上面的词义大致解释为:容易受骗,容易被人利用的人
nltk中使用wordnet
>>> nltk.corpus.wordnet.synsets(‘bank’)
找出了 bank 所有的Synsets。
[Synset('bank.n.01'), Synset('depository_financial_institution.n.01'), Synset('bank.n.03'),
Synset('bank.n.04'), Synset('bank.n.05'), Synset('bank.n.06'), Synset('bank.n.07'),爱他
Synset('savings_bank.n.02'), Synset('bank.n.09'), Synset('bank.n.10'), Synset('bank.v.01'),
Synset('bank.v.02'), Synset('bank.v.03'), Synset('bank.v.04'), Synset('bank.v.05'), Synset('deposit.v.02'),
Synset('bank.v.07'), Synset('trust.v.01')]
>>> nltk.corpus.wordnet.synsets(‘bank’)[0].definition()
找到 bank 第一个Synset的解释是什么
u'sloping land (especially the slope beside a body of water)‘
>>> nltk.corpus.wordnet.synsets(‘bank’)[1].lemma_names()
找到 bank 第二个同义词集中单词的词干
[u'depository_financial_institution', u'bank', u'banking_concern', u'banking_company']
2.2.2 WordNet中名词的关系

2.2.3 上位词链表(Hypernymy Chain)
拿 bass 的第三个词义和第七个词义为例,他们不断往上找父集,就可以看到最终会在 whole, unit 处相较,也就是这两种词义都是 whole, unit 的子集

2.3 单词相似度(Word Similarity)
- 同义词: film 和 movie 是同义词
- 那 show 和 film 怎么说? opera 和 film 呢?他们也很像,但不能说是同义词。
- 所以说单词相似度不能仅仅通过判断单词是否是同义词(这种二元关系)来决定。单词相似度是一个谱(spectrum), 对于两个单词是否相似的结果是连续的。
- 我们可以使用词义库(如WordNet)或词典来估计词的相似性。
2.3.1 通过路径长度判断单词相似度
- 给定一个词网,通过两个单词之间的路径长度判断相似度
- p a t h l e n ( c 1 , c 2 ) pathlen(c_1,c_2) pathlen(c1,c2) = 1 + c 1 c_1 c1和 c 2 c_2 c2之间的最短路径的边长度(注意这里的 c 是一个词义(或者一个同义词集),并不是一个单词)
- 因此两个同义词的相似度公式可以写成: s i m p a t h ( c 1 , c 2 ) = 1 p a t h l e n ( c 1 , c 2 ) simpath(c_1,c_2)=\frac{1}{pathlen(c_1,c_2)} simpath(c1,c2)=pathlen(c1,c2)1,即越长,相似度越低
- 那么单词的相似度的公式: w o r d s i m ( w 1 , w 2 ) = m a x c 1 ∈ s e n s e s ( w 1 ) , c 2 ∈ s e n s e s ( w 2 ) s i m p a t h ( c 1 , c 2 ) wordsim(w_1,w_2)=\underset{c_1\in senses(w_1),c_2\in senses(w_2)}{max}simpath(c_1,c_2) wordsim(w1,w2)=c1∈senses(w1),c2∈senses(w2)maxsimpath(c1,c2)
即遍历这两个单词所有的词义,查看每个词义之间的相似度,拿出最大的作为单词相似度。
例子
这里每个节点都是一个同义词集合,但为了方便,我们用单词来表示。
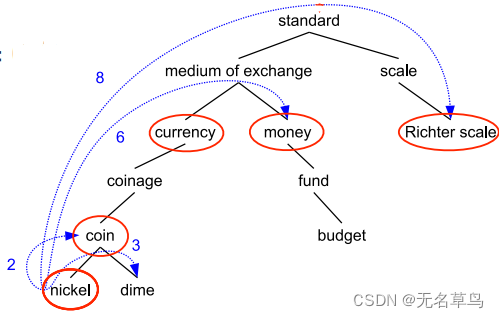
根据
s
i
m
p
a
t
h
(
c
1
,
c
2
)
=
1
p
a
t
h
l
e
n
(
c
1
,
c
2
)
=
1
1
+
e
d
g
e
l
e
n
(
c
1
,
c
2
)
simpath(c_1,c_2)=\frac{1}{pathlen(c_1,c_2)} = \frac{1}{1+edgelen(c_1,c_2)}
simpath(c1,c2)=pathlen(c1,c2)1=1+edgelen(c1,c2)1,这里之所以 + 1 是为了避免两个单词的某一个词义在同一个同义词集合里面,这样会导致分母为 0.
s
i
m
p
a
t
h
(
n
i
c
k
e
l
,
c
u
r
r
e
n
c
y
)
=
1
/
4
=
0.25
s
i
m
p
a
t
h
(
n
i
c
k
e
l
,
m
o
n
e
y
)
=
1
/
6
=
0.17
s
i
m
p
a
t
h
(
n
i
c
k
e
l
,
R
i
c
h
t
e
r
s
c
a
l
e
=
1
/
8
=
0.13
)
simpath(nickel,currency) = 1/4 = 0.25\\ simpath(nickel,money) = 1/6=0.17 \\ simpath(nickel,Richter\ scale = 1/8=0.13)
simpath(nickel,currency)=1/4=0.25simpath(nickel,money)=1/6=0.17simpath(nickel,Richter scale=1/8=0.13)
nickel 是五分美金的意思,所以它和currency货币 还有 money钱 的相似度比较高可以理解。
2.3.2 通过父节点和深度判断
问题是 nickel 和 Richter scale 里氏震级 的相似度也没比 nickel 和 money 低太多,毕竟Richter scale 都已经是另外一个大分支下的单词了。所以说,越靠近顶层的跳跃会产生更大的差距。
解决:将深度(depth)也考虑进来(Wu & Palmer)
- 找到最小的公共祖先(LCS,lowest common subsumer,也可以理解为二叉树里面的最小公共节点吧)
- 然后看这个公共祖先的节点深度,以及两个同义词集合的深度: s i m w u p ( c 1 , c 2 ) = 2 × d e p t h ( L C S ( c 1 , c 2 ) ) d e p t h ( c 1 ) + d e p t h ( c 2 ) simwup(c_1,c_2)=\frac{2 \times depth(LCS(c_1,c_2))}{depth(c_1)+depth(c_2)} simwup(c1,c2)=depth(c1)+depth(c2)2×depth(LCS(c1,c2)),当有 较高值的时候, 以为着父节点很深,词义很浅。
例子
还是那上面的那张图,此时
s
i
m
w
u
p
(
n
i
c
k
e
l
,
m
o
n
e
y
)
=
2
∗
2
/
(
6
+
3
)
=
0.44
simwup(nickel,money) = 2*2/(6+3)=0.44
simwup(nickel,money)=2∗2/(6+3)=0.44,
s
i
m
w
u
p
(
n
i
c
k
e
l
,
R
i
c
h
t
e
r
s
c
a
l
e
)
=
2
∗
1
/
(
6
+
3
)
=
0.22
simwup(nickel,Richter\ scale) = 2*1/(6+3)=0.22
simwup(nickel,Richter scale)=2∗1/(6+3)=0.22
区别没有我们想象的那么大,所以深度也不是一个很理想的用来做语义区分的方法。
- 那些在层级中靠近顶端的节点(词义)通常是非常抽象或者通俗的。我们怎么才能更好地抓住这个特性,帮助我们进一步完善语义相似度?
2.3.3 通过信息内容(Information Content)判断相似度
首先了解一个概念:概念概率(Concept Probability)
一个节点的概念概率:
概念概率(Concept Probability)用来表示这个节点有多么抽象,多么概念。
- 通俗的节点 就会有较高的概念概率,比如说 object (物体)
- 窄一点的节点 会有较低的概念概率,比如说 vocalist (声乐家)
- 概念概率 是通过把它孩子节点的unigram概率求和而得到的。 P ( c ) = ∑ s ∈ c h i l d ( c ) c o u n t ( s ) N P(c)=\frac{\sum_{s \in child(c)}count(s)}{N} P(c)=N∑s∈child(c)count(s),其中 N N N 为总的同义词集合数量。
- c h i l d ( c ) child(c) child(c)表示 c c c的子同义词集合
- c h i l d ( g e o l o g i c a l − i n f o r m a t i o n a ) = { h i l l , r i d g e , g r o t t o , c o a s t , n a t u r a l e l e v a t i o n , c a v e , s h o r e } child(geological-informationa)=\{hill, ridge, grotto, coast, natural\ elevation, cave, shore\} child(geological−informationa)={hill,ridge,grotto,coast,natural elevation,cave,shore}
-
c
h
i
l
d
(
n
a
t
u
r
a
l
e
l
e
v
a
t
i
o
n
)
=
{
h
i
l
l
,
r
i
d
g
e
}
child(natural\ elevation) = \{hill, ridge\}
child(natural elevation)={hill,ridge}
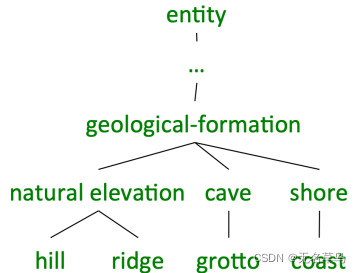
例子:
所以在顶层越抽象的节点会有更高的概率。

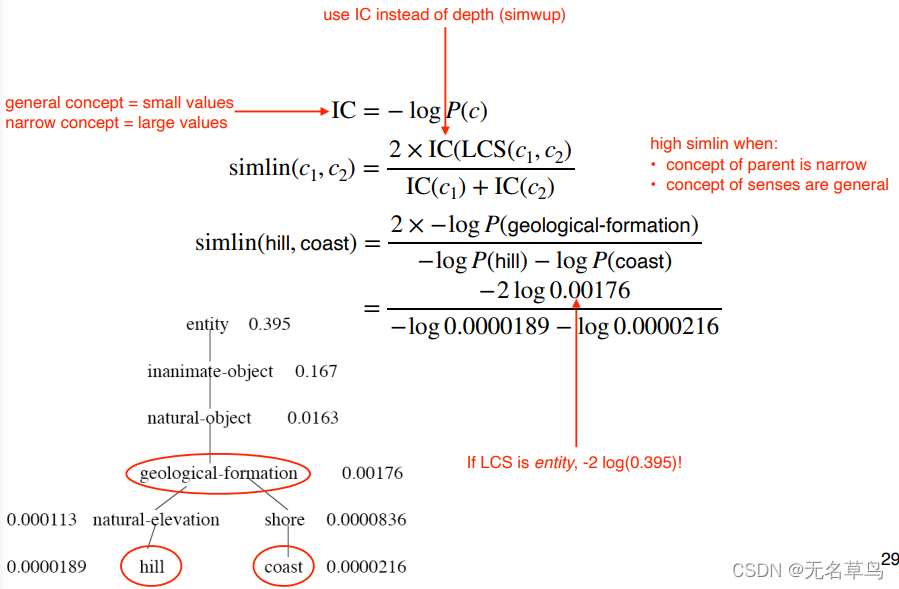
然后通过计算信息内容(Information Content) 来判断相似(见下图):
当
P
(
c
)
P(c)
P(c) 概念概率越大,则
I
C
IC
IC 越小,说明这个词义包含的信息越少。
然后用
I
C
IC
IC 替代之前的
d
e
p
t
h
depth
depth,当
s
i
m
l
i
n
simlin
simlin的值越高,说明它父节点的概念越窄(内容越详细),待判断的词义的概念越广泛。
假如 现在有两个完全不搭边的词义,他们两个的公共祖先就是 entity ,分子则会变得很小,从而使得相似度变低。
2.4 词义消歧(Word Sense Disambiguation)
- 任务: 为句子中的词语选择正确的意义
- Baseline:假设最流行的词义
- 良好的WSD可能对许多任务有用
- 比如说 了解句子中使用的是哪种意义的mouse很重要
- WSD 现在不那么流行了,因为词义会通过上下文表现而隐含地抓取到(后面篇幅会讲)。
2.4.1 有监督WSD
- 应用标准的机器分类器
- 特征向量通常是目标周围的单词和句法
- 但上下文也是含糊不清的(ambiguous)
- 上下文窗口应该有多大?(通常很小)。
- 需要已经词义标记的语料库
- 敏感度评估(SENSEVAL),SEMCOR(NLTK中提供)等。
- 创建非常耗费时间
2.4.2 无监督方法
Lesk
- Lesk:选择其WordNet注解中与上下文最重合的词义。
- 比如说一句话是 “The bank can guarantee deposits will eventually cover future tuition costs because it invests in adjustable-rate mortgage securities” (银行可以保证存款最终能支付未来的学费,因为它投资于可调整利率的抵押贷款证券)
- 通过在 WordNet中寻找 bank 的所有解释,我们发现在 bank1 注解中出现了两个与上下文重复的单词 deposits 和 mortgage;但是 bank2 里没有任何重叠的词。
- 所以这句话中 bank 的词义就是 bank1 的意思。

Clustering - 把一个单词的所有使用都聚集在一起:

- 然后在这些文字中使用聚类,以学习到不同的词义
- 合理性:如果词义相同那么它的上下文按理说也是差不多的。
- 缺点:但聚类出来的词义并不容易解释(只知道他们是一起的,但不知道是什么意思);需要配合词典进行解释
3 总结
- 词库的创建涉及专家策划(语言学家)。
- 最前沿的方法是试图从语料库中直接得出语义,不需要人工干预

















 5416
5416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









