







论文:FedDG: Federated Domain Generalization on Medical Image Segmentation via Episodic Learning in Continuous Frequency Space
收录情况:CVPR2021
pdf链接:https://arxiv.org/abs/2103.06030
代码:https://github.com/liuquande/FedDG-ELCFS
主要方法:使用多个域作为源域训练,但值得注意的是多个源域数据不是直接拿到,而是只拿到不同源域数据的幅度谱,另外增加了一个优化边界的损失函数,然模型泛化的未见过的目标域。
关键词:multi-source domain generalization
1. Abstract
联邦学习可以让分散的医疗中心获得共享的模型来分别训练自己的数据。但是在临床部署中,联邦学习训练的模型在完全没见过的数据集上性能仍然会下降。在这篇文章中,我们提出并解决了一个新的问题设定联邦预适应(FedDG),其目标是通过来自多个源域的数据学习一个联邦的模型从而能泛化到未见过的目标域数据。我们提出了一个新颖的方法叫做连续频域空间中的情景学习(ELCFS),使得每个分散的客户端能够利用多源域的数据分布。此方法通过连续频域空间插值机制传输数据信息,能有效保护客户端之间的数据隐私。另外,我们设计了一个针对优化边界的情景学习范式,来满足医学图像分割中模型泛化的问题。
2. Introduction
主要贡献点:
(1)提出了联邦预适应问题(Federated Domain Generalization, FedDG);
(2)使用了一种保护隐私的数据共享解决方法,即跨客户端的连续频率空间插值机制;
(3)针对客户端提出了一种面向边界的情景学习策略,能够改善因为域漂移导致的边界分割不清晰问题;
(4)在前列腺和眼底数据集上进行充分实验验证了方法的有效性。
3. Method
Related Work主要介绍Federated Learning和Domain Generalization,这里略过。
3.1 Federated Domain Generalization
- 问题设定:在FedDG中, ( X , Y ) (\mathcal X,\mathcal Y) (X,Y)表示图像空间和标签空间的联合分布, S = { S 1 , S 2 , … , S K } \mathcal{S}=\left\{\mathcal{S}^1, \mathcal{S}^2, \ldots, \mathcal{S}^K\right\} S={S1,S2,…,SK}表示 K K K个源域数据。 S k = { ( x i k , y i k ) } i = 1 N k \mathcal{S}^k=\left\{\left(x_i^k, y_i^k\right)\right\}_{i=1}^{N^k} Sk={(xik,yik)}i=1Nk表示其中一个源域 ( X k , Y ) (\mathcal{X}^k,\mathcal Y) (Xk,Y)的数据分布。FedDG的任务是利用 K K K个源域数据训练模型 f θ : X → Y f_\theta: \mathcal{X} \rightarrow \mathcal{Y} fθ:X→Y,使其在完全未见过的域 T \mathcal T T上有较好的表现。
- 挑战:(1)多源域数据是分布式存储的,每个客户端只能访问自己的数据集,这就限制了模型学习不同的数据分布;(2)能见到的多源域数据可能存在很大的异质性(就是data distribution差异较大),因此泛化到目标域时不能保证模型有良好的通用性;(3)医学图像通常分割边界较模糊,这对DG方法有较大挑战。
针对上面提出的挑战,文章后续提出了相应的解决方法。
3.2 Continuous Frequency Space Interpolation
- 对于某一张图像
x
i
k
∈
R
H
×
W
×
C
x_i^k \in \mathbb{R}^{H \times W \times C}
xik∈RH×W×C,对其进行FFT变换到频域:
F
(
x
i
k
)
(
u
,
v
,
c
)
=
∑
h
=
0
H
−
1
∑
w
=
0
W
−
1
x
i
k
(
h
,
w
,
c
)
e
−
j
2
π
(
h
H
u
+
w
W
v
)
\mathcal{F}\left(x_i^k\right)(u, v, c)=\sum_{h=0}^{H-1} \sum_{w=0}^{W-1} x_i^k(h, w, c) e^{-j 2 \pi\left(\frac{h}{H} u+\frac{w}{W} v\right)}
F(xik)(u,v,c)=h=0∑H−1w=0∑W−1xik(h,w,c)e−j2π(Hhu+Wwv)上面的频谱可以分解成幅度谱
A
i
k
∈
R
H
×
W
×
C
A_i^k \in \mathbb{R}^{H \times W \times C}
Aik∈RH×W×C和相位谱
P
i
k
∈
R
H
×
W
×
C
P_i^k \in \mathbb{R}^{H \times W \times C}
Pik∈RH×W×C,其中幅度谱反映了low-level的特征信息(比如图像风格),相位谱反映了high-level的图像语义信息。
为了构建不同客户端数据分布字典 A = [ A 1 , … , A K ] \mathcal{A}=\left[\mathcal{A}^1, \ldots, \mathcal{A}^K\right] A=[A1,…,AK],其中 A k = { A i k } i = 1 N k \mathcal{A}^k=\left\{\mathcal{A}_i^k\right\}_{i=1}^{N^k} Ak={Aik}i=1Nk表示第 k k k个客户端的图像幅度谱。这个字典在每一个客户端时可以共享的。 - 然后通过如下公式获得两个域
k
→
n
k \rightarrow n
k→n插值的幅度谱:
A
i
,
λ
k
→
n
=
(
1
−
λ
)
A
i
k
∗
(
1
−
M
)
+
λ
A
j
n
∗
M
\mathcal{A}_{i, \lambda}^{k \rightarrow n}=(1-\lambda) \mathcal{A}_i^k *(1-\mathcal{M})+\lambda \mathcal{A}_j^n * \mathcal{M}
Ai,λk→n=(1−λ)Aik∗(1−M)+λAjn∗M其中,
A
j
n
\mathcal{A}_j^n
Ajn是从distribution bank中随机采样的幅度谱,
A
i
k
\mathcal{A}_i^k
Aik是训练过程中输入的源域中图像的幅度谱,
M
=
1
(
h
,
w
)
∈
[
−
α
H
:
α
H
,
−
α
W
:
α
W
]
\mathcal{M}=\mathbb{1}_{(h, w) \in[-\alpha H: \alpha H,-\alpha W: \alpha W]}
M=1(h,w)∈[−αH:αH,−αW:αW]是对幅度谱低频部分取mask,
λ
\lambda
λ是
[
0.0
,
1.0
]
[0.0,1.0]
[0.0,1.0]随机采样。
对插值后的幅度谱进行反傅立叶变换: x i , λ k → n = F − 1 ( A i , λ k → n , P i k ) x_{i, \lambda}^{k \rightarrow n}=\mathcal{F}^{-1}\left(\mathcal{A}_{i, \lambda}^{k \rightarrow n}, \mathcal{P}_i^k\right) xi,λk→n=F−1(Ai,λk→n,Pik)另外, t i k = { x i , λ k → n } n ≠ k t_i^k=\left\{x_{i, \lambda}^{k \rightarrow n}\right\}_{n \neq k} tik={xi,λk→n}n=k - 注意:distribution bank是对
K
K
K个源域的图像进行傅立叶变化取幅度谱得到的,这一步计算容易,可以快速获得;另外对于每一个客户端训练模型时,随机采样共享的distribution bank中的幅度谱进行插值操作。
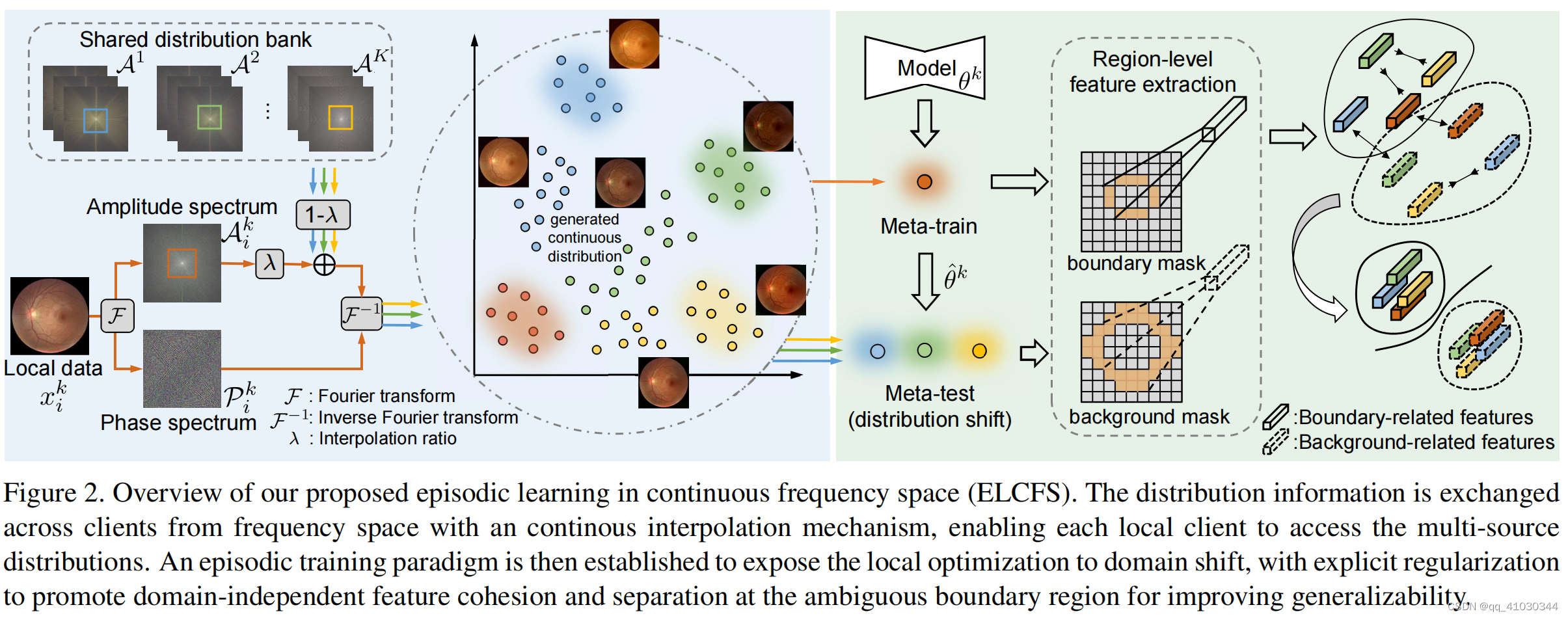
3.3 Boundary-oriented Episodic Learning
Episodic learning at local client
在不同客户端训练自己的数据看作是元学习,原始数据
x
i
k
x^k_i
xik是训练集,变换后的数据
t
i
k
t^k_i
tik为测试集。
首先,客户端模型根据dice loss更新参数:
θ
^
k
=
θ
k
−
β
∇
θ
k
L
s
e
g
(
x
i
k
;
θ
k
)
\hat{\theta}^k=\theta^k-\beta \nabla_{\theta^k} \mathcal{L}_{s e g}\left(x_i^k ; \theta^k\right)
θ^k=θk−β∇θkLseg(xik;θk)其次,挑选最优模型时用的是
t
i
k
t^k_i
tik作为验证集。
Boundary-oriented meta optimization
提出了一种优化边界的损失函数
- 原始训练图提取目标边缘和背景边缘一维特征向量: 根据
x
i
k
x^k_i
xik的label
y
i
k
y^k_i
yik,使用形态学算子可以提取到boundary mask
y
i
_
b
d
k
y_{i\_bd}^k
yi_bdk 和background mask
y
i
_
b
g
k
y_{i\_bg}^k
yi_bgk,上图右边所示。
分割网络最后一层的特征图 Z i k Z^k_i Zik与 y i _ b d k y_{i\_bd}^k yi_bdk, y i _ b g k y_{i\_bg}^k yi_bgk通过如下操作得到每张训练图片的一维特征向量,这个特征向量代表了边界的区域特征 h i − b d k = ∑ h , w Z i k ∗ y i − b d k ∑ h , w y i − b d k ; h i − b g k = ∑ h , w Z i k ∗ y i − b g k ∑ h , w y i − b g k h_{i_{-} b d}^k=\frac{\sum_{h, w} Z_i^k * y_{i-b d}^k}{\sum_{h, w} y_{i_{-b d}}^k} ; h_{i_{-} b g}^k=\frac{\sum_{h, w} Z_i^k * y_{i_{-} b g}^k}{\sum_{h, w} y_{i_{-} b g}^k} hi−bdk=∑h,wyi−bdk∑h,wZik∗yi−bdk;hi−bgk=∑h,wyi−bgk∑h,wZik∗yi−bgk - 变换图提取目标边缘和背景边缘一维特征向量: 对于每一张训练图 x i k x^k_i xik,都对应着 K − 1 K-1 K−1张变换图 t i k t^k_i tik,每一张变换图也可以根据label y i k y^k_i yik提取 h i − b d k h_{i_{-} b d}^k hi−bdk和 h i − b g k h_{i_{-} b g}^k hi−bgk。因此对于每一张训练图,最后都能得到 K K K个boundary-related和 K K K个background-related特征向量。
- 定义边界损失函数: 在 2 K 2K 2K个向量中,定义特征对 ( h m , h p ) (h_m,h_p) (hm,hp),正类对为都属于boundary-related或background-related的向量,负类对为一个是boundary-related另一个是background-related向量。对于每一个正类对,使用InfoNCE loss: ℓ ( h m , h p ) = − log exp ( h m ⊙ h p / τ ) ∑ q = 1 , q ≠ m 2 K F ( h m , h q ) ⋅ exp ( h m ⊙ h q / τ ) \ell\left(h_m, h_p\right)=-\log \frac{\exp \left(h_m \odot h_p / \tau\right)}{\sum_{q=1, q \neq m}^{2 K} \mathbb{F}\left(h_m, h_q\right) \cdot \exp \left(h_m \odot h_q / \tau\right)} ℓ(hm,hp)=−log∑q=1,q=m2KF(hm,hq)⋅exp(hm⊙hq/τ)exp(hm⊙hp/τ) ⊙ \odot ⊙为余弦相似度,正类对 F ( h m , h q ) \mathbb{F}\left(h_m, h_q\right) F(hm,hq)为0,负类对为1, τ \tau τ为温度系数。最后的 L boundary \mathcal{L}_\text{boundary} Lboundary为 ℓ \ell ℓ over所有正类对的平均: L boundary = ∑ m = 1 2 K ∑ p = m + 1 2 K ( 1 − F ( h m , h p ) ) ⋅ ℓ ( h m , h p ) B ( K , 2 ) × 2 \mathcal{L}_{\text {boundary }}=\sum_{m=1}^{2 K} \sum_{p=m+1}^{2 K} \frac{\left(1-\mathbb{F}\left(h_m, h_p\right)\right) \cdot \ell\left(h_m, h_p\right)}{B(K, 2) \times 2} Lboundary =m=1∑2Kp=m+1∑2KB(K,2)×2(1−F(hm,hp))⋅ℓ(hm,hp)其中 B ( K , 2 ) B(K, 2) B(K,2)为 K K K取2
- 总的损失函数: L meta = L seg ( t i k ; θ ^ k ) + γ L boundary ( x i k , t i k ; θ ^ k ) \mathcal{L}_{\text {meta }}=\mathcal{L}_{\text {seg }}\left(t_i^k ; \hat{\theta}^k\right)+\gamma \mathcal{L}_{\text {boundary }}\left(x_i^k, t_i^k ; \hat{\theta}^k\right) Lmeta =Lseg (tik;θ^k)+γLboundary (xik,tik;θ^k) arg min θ k L s e g ( x i k ; θ k ) + L m e t a ( x i k , t i k ; θ ^ k ) \underset{\theta^k}{\arg \min } \mathcal{L}_{s e g}\left(x_i^k ; \theta^k\right)+\mathcal{L}_{m e t a}\left(x_i^k, t_i^k ; \hat{\theta}^k\right) θkargminLseg(xik;θk)+Lmeta(xik,tik;θ^k)
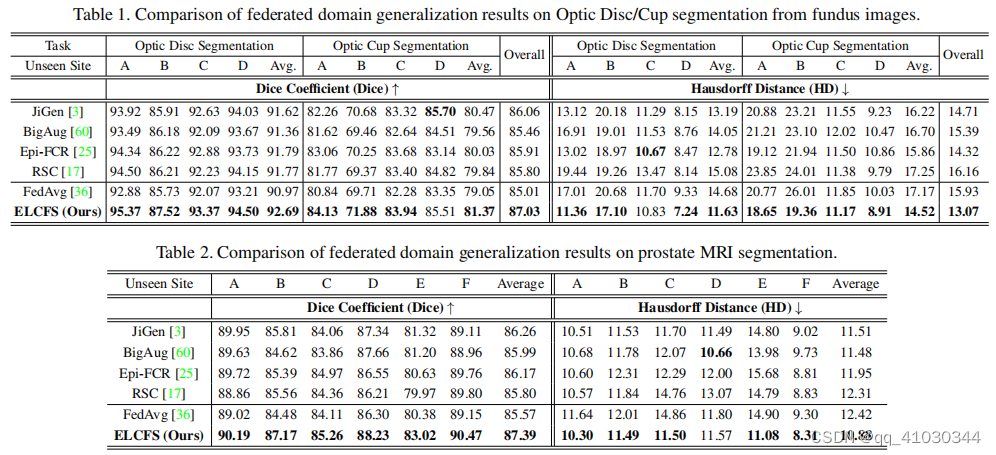
Experiments
采用leave-one-domain-out策略,即一个数据域作为unseen domain,其余数据域为source domain















 2465
2465











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









