







1. 数据库的故障和恢复方法
错误的数据输入:应用程序的检测机制进行检测。系统错误:断电或软件错误。通过数据库的恢复机制进行恢复。介质故障:磁盘故障,可用数据存储的奇偶校验进行校正,或采用 RAID 技术。灾难性故障:火灾。及时备份(远程备份)。
2. 事务和日志的概念
事务:一系列的操作集合。特性(ACID):
- 原子性(Atomicity):要么全部成功,要么全部失败。
- 一致性(Consistency):事务必须从一个一致状态转变到另一个一致状态。
- 隔离性(Isolation):多个用户并发访问数据库时,并发事务要相互隔离,不能相互干扰。
- 持久性(Durability):一个事务一旦被提交,对数据库的改变是永久性的。
如果用 SQL 写事务的话,由 begin,transaction,commit,rollback 命令界定。
- 事务的状态

- 事务管理器的工作原理

3. 事务日志
一旦发生故障,数据管理系统的恢复管理器启动日志数据,日志数据被被扫描,然后基于恢复机制对数据库系统进行恢复,日志以文件形式存盘。
4. 事务的概念
4.1 用于记录日志的重要的事务原语
- 磁盘空间
- 缓冲区管理器所管理的主存地址与虚存地址
- 事务的局部地址空间

整个事务,整个数据如果从磁盘到内存(读入数据)里面经过的空间如下:
磁盘 => 缓冲区 => 事务的局部地址空间 => 赋给相应的变量.
写数据:
数据从事务的局部地址空间移到 => 缓冲区 => 磁盘
INPUT: 磁盘 => 缓冲区
OUTPUT: 缓冲区 => 磁盘
READ: 缓冲区 => 事务的局部地址空间
WRITE: 事务的局部地址空间 => 缓冲区
5. 日志的概念
日志记录操作的序列,一个日志可以记录多个事务的执行情况。日志记录以文件形式存盘,“刷新日志记录”命令(FLUSH LOG)使当前在缓冲区的日志记录强制性写入磁盘。如果系统崩溃则日志被查询,以恢复数据库的一致性。
- 日志记录所包涵的元素:
- : 标识事务的开始;
- : 标识事务执行成功;
- : 标识事务失败
- 数据对象更新操作类型,及某取值(原值/新值).
- 检查点记录 —— chenkpoint 记录。
6. 基于日志的恢复机制
- 常用的三种日志类型
- undo 日志
- redo 日志
- undo/redo 日志
- undo 日志及其恢复机制
日志文件更新数据的日志记录格式:
<T, op, x, v>:
op: 更新操作类型
x: 被更新的数据对象
v: x更新前的取值 (原值)
2.1 创建 undo 日志记录的规则
数据元素更新时,先把日志记录写入磁盘,后把更新数据写入磁盘。提交事务前,则先把所有更新数据写入磁盘,后立即把 记录写入磁盘。
写日志 => 更新数据 => commit
2.2 undo 日志的动态检查及其使用
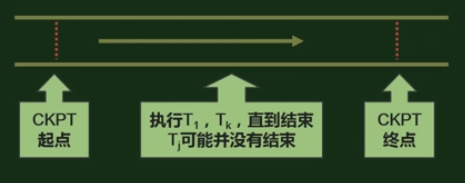
① 设置检查点的规则:
在某些事务开始时,写日志记录 <START CRPT(T1,…,TK)>,并刷新日志记录。
等待事务的提交或终止,在此期间可以有其它是事务 Tj 开始;
当 T1,…,TK 提交或终止后,写 End CKPT<T1,TK>,并刷新日志。
eg:
<START T1>
<T1, D, A, 10>
<START CKPT(T1)>
<START T2>
<COMMIT T1>
<END CKPT>
② 利用检查点恢复数据库策略:
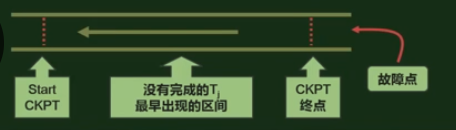
(1) 从故障点起,逆向扫描日志文件,以便确定故障发生时没有完成的事务。
- 若逆向扫描过程中,首先遇到
<END CKPT>, 则没有完成的事务T,必定没有相应的<COMMIT T>记录,且最早位于下列区间
- 若逆向扫描过程中,首先遇到
<START CKPT(T1,...Tk)>,则未完成的事务 Tj 没有相应的<COMMIT Tj>记录,且最早位于下列区间:

- redo 日志及其恢复机制
3.1 日志文件更新数据的日志记录格式:
<T, op, x, w>:
op: 更新操作类型
x: 被更新的数据对象
w: x更新后的取值 (新值)
3.2 创建 REDO 日志记录的规则
数据更新时,先把所有记载数据更新的日志记录和 <COMMIT T> 记录写入磁盘,后才把更新数据写入磁盘(先写日志,后写数据)。
3.3 恢复原则:重做已经提交的事务。
3.4 利用 redo 日志进行恢复
<START T1>
<T1, D, A, 20>
<START CKPT(T1)>
<START T2>
<T1, I, B, 20>
<END CKPT(T1)>
<COMMIT T1>
(1) 设置检查点的规则
- 写日志记录
<STATRT CKPT(Tj,...,Tk)>,并刷新日志记录;- 将写
<START CKPT(Tj,...,Tk)>日志记录时,缓冲区中所有已经提交,但未写入磁盘的数据库更新操作,完成写盘操作。- 写入
<END CKPT>日志记录,并刷新日志记录。

(2) 利用 REDO 日志恢复数据库类型
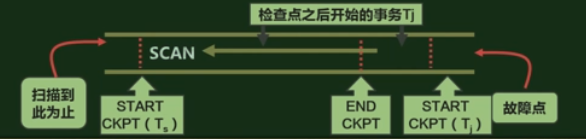
从故障点起,逆向扫描日志,以确定回复故障时需要重做的已提交事务:
- 若逆向扫描过程中,首先遇到
<END CKPT>, 则需要重做的事务时 Tr ∈ ({Tj} ∪ {T1,…,Tk}),且 Tr 必须是存在<COMMIT Tr>记录的事务
- 若逆向扫描过程中,首先遇到
<START CKPT(Ti)>,则应继续扫描,直到另一<START CKPT(Ts)>为止(它必有对应的<END CKPT>).则需要重做的事务时 Tr ∈ ({Tj} ∪ {T1,…,Tk}),且 Tr 必须是存在<COMMIT Tr>记录的事务

7. redo 和 undo 区别
-
Undo日志记录某数据被修改前的值,可以用来在事务失败时进行rollback;Redo日志记录某数据块被修改后的值,可以用来恢复未写入data file的已成功事务更新的数据。
undo:
写盘顺序:数据元素更新时,先把日志写入磁盘,后把更新的数据写入磁盘。提交事务前,先把所有更新数据写入磁盘,后立即把<COMMIT>写入磁盘。恢复原则: 进行恢复时,从后向前扫描日志,遇到有 commit 的事务忽略,没有 commit 的事务将对数据库的更新进行撤销。
设置检查点规则:事务开始时,写日志记录<START CKPT(T1,...,Tk)>,并刷新记录 (FLUSH LOG); 等待事务提交或终止;当 T1,…,Tk 提交或终止后,写<END CKPT(T1,...,Tk)>,并刷新日志。
redo:
写盘顺序: 数据元素更新时,先把更新的日志记录和<COMMIT T>写入磁盘;后才把更新数据写入磁盘。(先写日志,后写数据)恢复原则: 重做已经提交的事务。设置检查点规则:写日志<START CKPT(T1,...,Tk)>,并刷新日志记录;将写<START CKPT(T1,...,Tk)>时,缓冲区中所有已经提交但未写入磁盘的数据库更新操作,完成写盘操作;写入<END CKPT>日志记录,并刷新纪录。(数据先更新,然后设置检查点,结束检查点,数据提交到磁盘)
- 基于 undo/redo 日志的恢复机制
<T, op, x, v, w>:
op: 更新操作类型
x: 被更新的数据对象
v: x更新前的取值 (原值)
w: x更新后的取值 (新值)
3.1 创建 undo/redo 日志记录的规则:
数据元素更新时,先把数据更新日志记录写入磁盘。 记录可以在磁盘上数据库元素的修改之前或之后。
3.2 恢复原则:重做已经提交的事务,撤销没有做完的事务。
3.3 设置检查点规则:
- 写入 START CKPT(T1,…,Tk),并刷新日志记录;
- 把所有缓冲区的更新数据写入磁盘;
- 写入 END CKPT,并刷新日志记录;
3.4 恢复策略:
- 故障点起逆向扫描,确定需要重做和撤销的事务;
- 重做 COMMIT 的事务,逆向撤销没有 COMMIT 的事务;















 9260
9260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









