







文章目录
一、数据库故障恢复思路
1.1 故障类型 影响
1.1.1 DMBS运行方式
利用主存(内存) 和 辅存(外存) 存储体系进行数据库管理
主存中分为:程序数据 + 系统数据
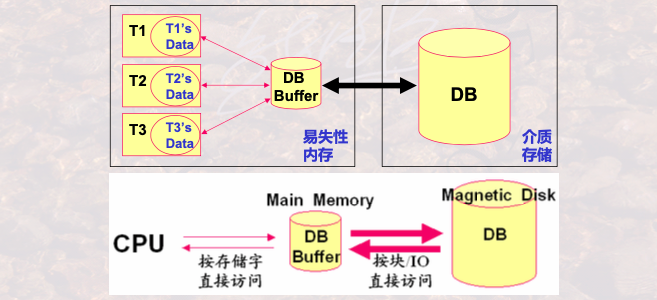
1.1.2 故障类型
事务故障
- 某个事务自身运行引起的故障
- 影响该事物本身
系统故障
- 掉电、非正常关机等引起的故障
- 影响正在运行的事务以及数据库缓冲区
介质故障
- 介质损坏影响的故障
- 影响是全面的,既影响内存中的数据,又影响介质中的数据
1.2 故障恢复
1.2.1 数据库故障恢复
把DB的当前不正确的状态恢复成已知的正确的状态
需要保证事务的:
- 原子性:事务的所有操作为一个整体
- 持久性:已经提交的事务,落盘 是 肯定的
1.2.2 事务故障恢复
事务可以通过重做事务Redo 和 撤销事务Undo来恢复
1.2.3 系统故障恢复
运行日志SystemLog
- Log是DBMS维护的一个文件,以流水方式记录了每一事务对DB的每一次操作&操作的顺序
- 运行日志直接写入介质存储上,会保持正确性
- 事务对DB操作时,先写日志(1) 成功后 在写入DB(2)
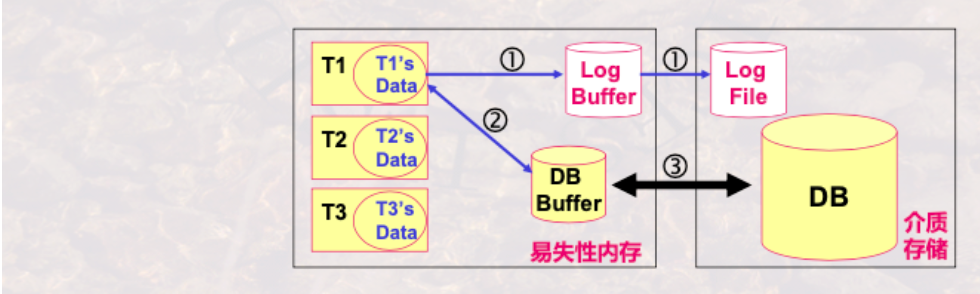
系统故障可以通过运行日志来恢复
故障恢复是需要时间的
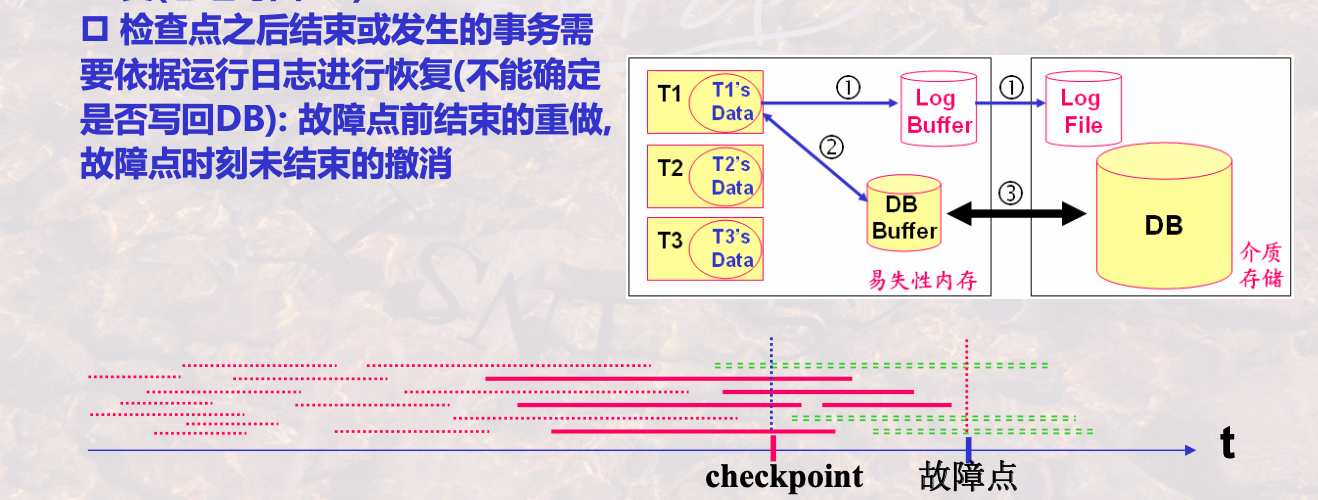
DBMS在运行日志中定期设置河更新检查点Checkpoint
- 检查点是这样的时刻:在该时刻,DBMS强制使内存DBbuffer中的内容和介质DB中的内容保持一致,将DBbuffer更新的所有内容写会DB中
- 检查点表示:在检查点之前,内存中的数据与介质中的数据保持一致
系统故障的恢复
- 检查点之前的事务不需要恢复(因为已经落盘)
- 检查点之后的事务需要恢复(结束的重做,未结束的撤销)
1.2.4 介质故障恢复
副本:在某一时刻,数据库的备份
用备份来替换损坏的数据库
介质故障的恢复:用副本来替换数据库
由于介质故障影响全面,在副本替换后 还需要 日志恢复
备份时刻:转储点
过频,影响性能;过疏,运行日志过大,恢复起来慢
频率和运行日志大小有关
数据库的系统故障分为三类:事务故障、系统故障和介质故障,下面分别介绍这三类故障及其例子:
事务故障
事务故障是指在多个事务并发执行时,由于事务之间相互干扰而导致的故障。例如,当两个事务同时对同一条记录进行更新时,由于数据竞争可能导致其中一个事务无法完成操作。这种情况下,数据库管理系统需要能够检测到此类故障,并回滚未完成的事务,以保证数据的一致性。
举例来说,假设有两个事务T1和T2,都要对银行账户的余额进行修改。T1从账户中取出了100元,T2向账户中存入了50元。由于这两个事务的执行时间是交错的,所以可能会发生以下两种情况:
T1先执行,将账户余额减去100元,然后T2执行,将账户余额加上50元。此时账户余额为950元。
T2先执行,将账户余额加上50元,然后T1执行,将账户余额减去100元。此时账户余额为900元。
由于这两种情况得到的结果不同,因此需要避免这种数据竞争导致的事务故障。
系统故障
系统故障是指由于硬件故障或软件问题导致的数据库系统崩溃或失效。例如,电源故障、网络故障、操作系统故障等都可能导致系统故障。这种故障需要进行紧急处理,保证系统能够尽快恢复正常运行。
举例来说,假设数据库在写入数据时出现了错误,导致存储介质损坏或无法访问,这种情况下将会导致系统故障。
介质故障
介质故障是指由于存储介质的物理损坏或软硬件环境变化导致的数据库故障。例如,磁盘损坏、电磁波干扰、温度过高等都可能导致介质故障。这种故障需要及时修复或更换存储介质,以避免数据的长期损失。
举例来说,假设数据库存储在一台服务器上,该服务器所在的机房发生火灾,导致存储介质被烧毁,这种情况下将会导致介质故障。
综上所述,事务故障、系统故障和介质故障是数据库系统常见的故障类型,需要通过适当的技术手段进行检测、修复和预防。
二、运行日志及其检查点
2.1 DB Log
2.1.1 事务的操作
事务读写元素
- Read(X,t):将元素X读到局部变量t中
- writex(X,t):将事物局部变量t学回元素X
- Input(X):将元素X从磁盘读入到内存缓冲区中
- Output(X):将元素X写回到磁盘中
每个事务都可以提交或者撤销 - commit
- abort
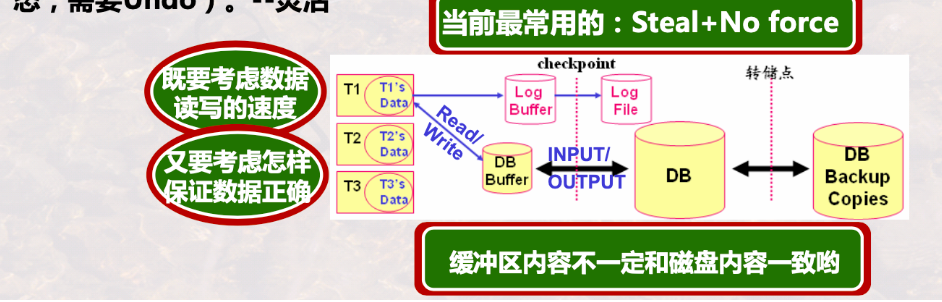
2.1.2 缓冲区处理策略
持久性的特性:
Force:内存中的数据最晚在commit的时候写入磁盘
No Steal:只能在commit的时候提交,不允许事务提前提交
No force:数据在内存中可以一直保留,在commit之后一段时间再写入磁盘,commit之后崩溃还没写,需要redo
Steal:允许commit之前落盘,if commit is failed, 需要undo
2.2 日志记录


三、三种类型的运行日志
3.1 Undo日志
记录原始值

Undo型日志:“将事务改变的所有数据写到磁盘前不能提交该事务”
记录的原始值
故障时直接恢复原始值
Undo日志:Undo日志记录了事务进行之前数据的原始状态,以及每个事务所做的修改,用于在回滚时恢复数据原始状态。在数据库回滚操作中,首先会根据事务的ID,找到该事务对应的Undo日志,然后根据Undo日志中的信息,恢复数据到事务之前的状态。例如,如果一个事务对某个用户的姓名进行了修改,在回滚时,可以使用Undo日志中记录的原始姓名信息,将数据恢复至修改之前的状态。
3.1.1 检查点

3.2 Redo日志
记录修改的操作
 记录修改操作 +1 +2 之类的
记录修改操作 +1 +2 之类的
Redo日志:Redo日志记录了每个事务所做的修改操作,用于在系统发生崩溃时进行恢复。在数据库恢复操作中,首先会根据Redo日志中的信息,将缺失的数据重新写入磁盘中,以保证数据的完整性。例如,在一个在线购物网站中,如果在用户提交订单后,系统崩溃了,使用Redo日志可以将该订单重新写入磁盘中,确保订单信息不会丢失。
只能有非静止检查点(增量检查点)
3.3 Undo/Redo日志结合
记录原始值和修改的值

Undo、Redo日志对比:
- Undo
- output必须先做
- if commit T可见,那么T已经落盘,不必重做。
- 导致频繁写磁盘
- Redo
- output必须后做
- if commit T 不可见,T确定没有任何数据落盘,因此无需撤销。
- 灵活性差,数据必须在commit之后才能见到
Redo/Undo日志:Redo/Undo日志综合了Undo和Redo日志的功能,在事务进行过程中,同时记录当前状态和操作,用于在系统崩溃时和事务回滚时进行数据恢复。在Redo/Undo日志中,Undo操作和Redo操作都会被记录下来,以保证数据的完整性和一致性。例如,如果在一个医院管理系统中,一个医生修改了某个病人的病历记录,系统同时会记录下原始病历记录和修改后的病历记录,以便在医生需要撤销修改或系统崩溃时恢复数据
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











