









长短时记忆网络LSTM在针对短时时间序列预测问题上近来年受到大家的关注,但由于该方法为深度学习方法,通常面临着众多超参数的影响,而众所周知,关于深度学习超参数的设置并没有一直明确的指导方针,大多采用经验方法,比如学习率1e-3,1e-4啥的,迭代次数根据loss曲线的变化等进行设置,这种方法说简单的就是无限尝试,找到效果比较好的一组,耗时耗力。为此,本文将采用贝叶斯框架对 LSTM进行参数优化 , 同时采用同步挤压小波SWT对原始数据进行滤波降噪,并采用降噪会的数据进行建模,最后用实例验证表明 ,SWT-Bayesian-LSTM 模型的预测效果更佳。
本人电脑配置:matlab2020b,vs2015,cuda9.0,cudnn7.1,8g,gtx960 4g,(matlab2018之后的深度学习工具箱会自动调用可用gpu,加快训练速度,做深度学习推荐采用新版matlab,链接:https://pan.baidu.com/s/1l6VAiZYHQuPPIqSBSbQzCw 提取码:9q0f ,安装教程 http://www.xue51.com/tuwen/7941.html )
2.贝叶斯优化LSTM的时间序列预测
本文采用贝叶斯优化LSTM进行时间序列预测,数据如图所示。原始数据各波峰波谷存在大量的毛刺,这必将影响数据的预测精度。因此,为更好地实现建模,本文采用基于同步挤压小波变换SWT的降噪方法对该信号进行降噪处理,然后基于降噪后的信号进行时间序列预测分析。

2.1 基于同步挤压小波的数据降噪预处理
同步挤压小波变换(Synchrosqueezing Wavelet Transform,SWT,也有地方简称WSST ,SST啥的,这个不重要)的原理百度就有,工具箱链接:http://www.pudn.com/Download/item/id/2566950.html,自己去搜。主要写写自己的处理步骤:1)对数据进行SWT变换,得到信号的同步挤压输出。2)对1得到的同步挤压输出进行带通滤波,只保持固定的频率带,从而剔除高频噪点。3)对降噪后的输出进行SWT逆变换。降噪后的信号SWT时频图如下图所示,可以看出原信号35Hz以上的噪声已经不存在了。降噪前后的数据如图所示,通过局部放大进行可视化,可以看到降噪后的数据更加平滑。


2.2 基于贝叶斯优化LSTM的时间序列预测
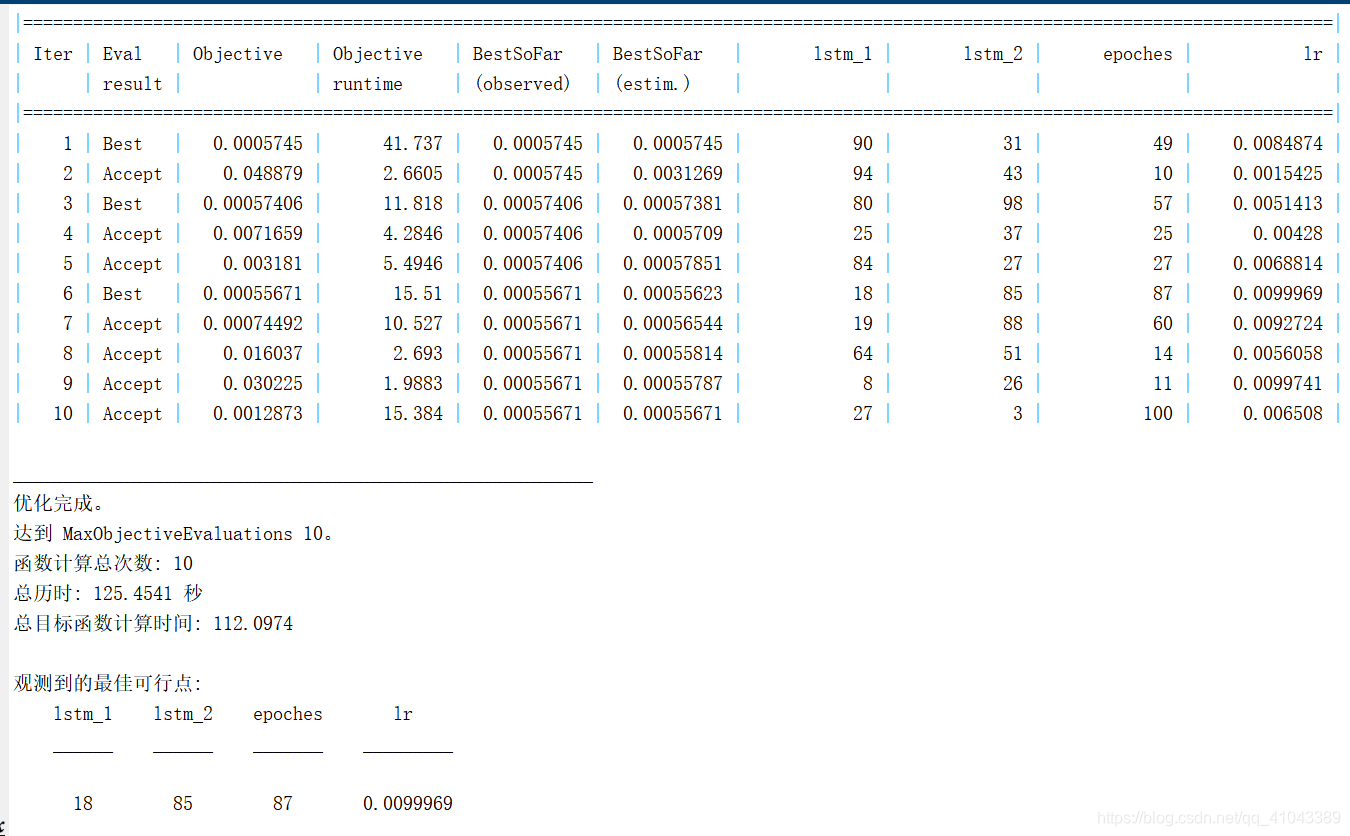
采用上述降噪后信号,进行滚动建模,具体操作为:采用1到n的值作为输入 第n+1时刻的值作为输出,然后2到n+1的值为输入 n+2的值为输出。。。这样实现滚动建模。针对LSTM的超参数选择问题,采用上述本文拟贝叶斯对LSTM的超参数进行寻优,超参数包括隐藏层神经元的个数L1和L2(L1和L2指的是第一层的LSTM单元的个数和第二层的LSTM单元的个数,范围为0-100)、学习率lr(范围为0.001-0.01)、迭代次数(范围为0-100),贝叶斯的评估数为10代,以网络输出的预测值和真实值的均方差为适应度函数,优化结果见下图。上图为适应度曲线(中图是放大一部分),表明贝叶斯能够找到一组超参数,用这组超参数训练的网络的误差更低,因此蓝色是一条下降的曲线,下图是各参数的变化截图,最终各参数为:L1:18 L2:85 K:87 lr:0.0099969


利用上述超参数重新建立LSTM网络,得到的预测结果如图所示:

2.3 各方法预测效果对比
将Bayesian-LSTM与没优化的LSTM,进行对比,结果如图


分析可知:采用同步挤压小波SWT降噪后的数据与贝叶斯优化长短时记忆网络LSTM的精度最高。
















 1640
1640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











