







背景
SV(speaker verification)分为三个步骤:
Development: 模型训练
Enrollment: 新用户注册
Evaluation: 用户的识别
概念
在development时,输入为给定上下文(文本相关)的帧级语音,target为说话人身份,输出维数与说话人数量N相等,是一个 1-hot向量,即唯一的非零元素对应了说话人的身份。
在enrollment时,对每段语音来说,将每一帧数据分别输入DNN,d-vector(说话人的向量)为DNN最后一层隐藏层的输出之和。
在evaluation时,计算d-vector间的距离,从而判断说话人身份。
实现流程

对于一个说话人s的语音集
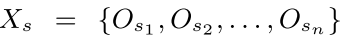
每一段语音可分为
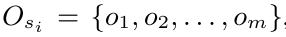
将每一个Osi的oj输入DNN,取最后一层隐藏层的输出L2标准化,并将每个Osi的oj输出求和,即可得到d-vector,最后将每段语音Osi的d-vector求和取平均,就得到了说话人的特征。
在evaluation时,计算d-vector间的cos distance,将distance与阈值比较,从而判断说话人身份。
DNN对后两层layer使用了Dropout来避免过拟合。
实验
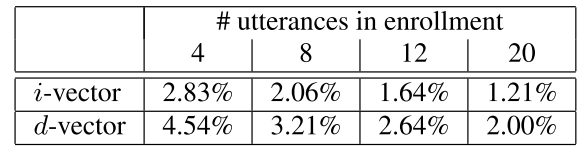

总的来说,i-vector的表现要好于d-vector,但在低错误拒绝了区间,d-vector要好于i-vector

在对enrollment与evaluation加上了10dB噪音后,噪音对d-vector的影响小于i-vector。















 949
949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









