









声纹识别之GMM-UBM系统框架简介
https://blog.csdn.net/weixin_38206214/article/details/81084456
声纹识别之I-Vector
https://blog.csdn.net/weixin_38206214/article/details/81096092
- d-vector
DNN训练好后,提取每一帧语音的Filterbank Energy 特征作为DNN输入,从Last Hidden Layer提取Activations,L2正则化,然后将其累加起来,得到的向量就被称为d-vector。如果一个人有多条Enroll语音,那么所有这些d-vectors做平均,就是这个人的Representation。DNN的网络结构如图1.2所示。
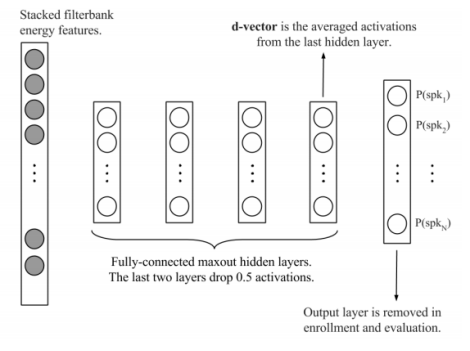
图1.2 用于提取d-vector的DNN模型
因为d-vector是从Last Hidden Layer提取的,通过移除Softmax Layer,可以缩减Model Size。而且,这也可以让我们在不改变Model Size的情况下,在训练过程中使用更多的说话人数据来做训练(因为Softmax Layer被移除了,不用考虑Softmax Layer的节点数)。DNN的训练过程,可以详细阅读参考文献[3]。
max-out层
https://www.bbsmax.com/A/QW5Yxl1MJm/

















 1392
1392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









