







文章目录
pands分为Series和DataFrame两种数据结构:
创建Series数据
pd.Series([1,2,3,4,5,6], index=pd.date_range('20130101',periods=6))
结果:
2013-01-01 1
2013-01-02 2
2013-01-03 3
2013-01-04 4
2013-01-05 5
2013-01-06 6
创建DataFrame数据
DataFrame的数据:
dates = pd.date_range('20200101',periods=6)
# 形式一:
data=np.random.randn(6,4)
df1 = pd.DataFrame(
data, # numpy数组形式
index=dates, # 行索引,默认是数字
columns=['a','b','c','d'] # 列索引
)
# 形式二:
data = {'a':[12,13,14,15,16],'b':[21,22,23,24,25],'c':[31,32,33,34,35]}
df2 = pd.DataFrame(
data, # 字典形式
index=dates, # 行索引,默认是数字
)
输出DataFrame的列索引:
df.columns
df.columns[0] # 输出第0列的索引
输出DataFrame的行索引:
df.index
以numpy的形式输出DataFrame的值:
df.values
翻转DataFrame:
df.T
根据DataFrame的索引进行排序:
df.sort_index(axis=0,ascending=False) //axis根据行索引排序,axis等于1的话时对列索引(行)进行排序,ascending=False表示降序。
根据DataFrame的值进行排序sort_values函数
df2.sort_values(by=dates[0],axis=1,ascending=False,inplace=False)
//by是索引的值,axis=1表示行排序,axis=0表示对列排序默认为0(列排序),inplace表示不替换
冷门使用
df.describe
df.dtypes
DataFrame选择数据
- 法一:
选择单列
df[‘A’] 显示索引A列
选择多行多列
df[[‘A’,‘B’,‘C’]] 显示多列
df[0:3] 显示多行 - 法二:根据行列标签
df.loc[:,[‘A’,‘B’,‘C’]] 选取所有行,第’A’,‘B’,'C’列
df.loc[:,‘A’:‘C’] 同上,必须有顺序
df.loc[0,‘A’] 选取第0行,第’A’列 - 法三:根据行号选择 ,可以跨行选取的操作:
df.iloc[[1,2,3],[2,3]] 选取第1,2,3行,第2,3列
df.iloc[0,0] 选取第0行第0列 - 法四:根据行号或者行标签
df.ix[[0,1,2],[‘A’,‘B’,‘C’]] 可以混合选择(虽然方便但是不严格,以后这个函数会过期)
根据DataFrame的值来进行筛选:
data[data.iloc[:,1]==0] # 选取所有行中,第一列中的值等于0的行。
data[data['A']==0] # 同上
总结: 标签使用loc, 索引号使用iloc, 尽量不使用ix。
DataFrame添加数据
- 添加行
data = pd.Series([1,2,3,4,5,6],index=df.columns) # 需要添加的数据
df.loc['a']=data # 增加 a 1 2 3 4 5 6
- 添加列
data = data = pd.Series([1,2,3,4,5,6],index=df.index)
df['f'] = data # 增加列 f 1 2 3 4 5 6 一定要对齐
设置DataFrame标签和索引
修改标签
set_index()函数:
- df.set_index(‘b’,inplace=True) # 把’b’列的内容作为标签并保存
rename()函数:参考rename()链接
- df.rename({2:‘f’},inplace=False) # 更改标签名称
- df.rename(index={2:‘f’},columns={‘A’:‘b’},inplace=Flase)
- rename()函数中通过映射来修改标签
df.rename(index=str.upper,columns=str.lower) - rename()函数通过自定义映射修改标签
def test_map(x):
return x+’_ABC’ df.rename(index=test_map,columns=test_map)
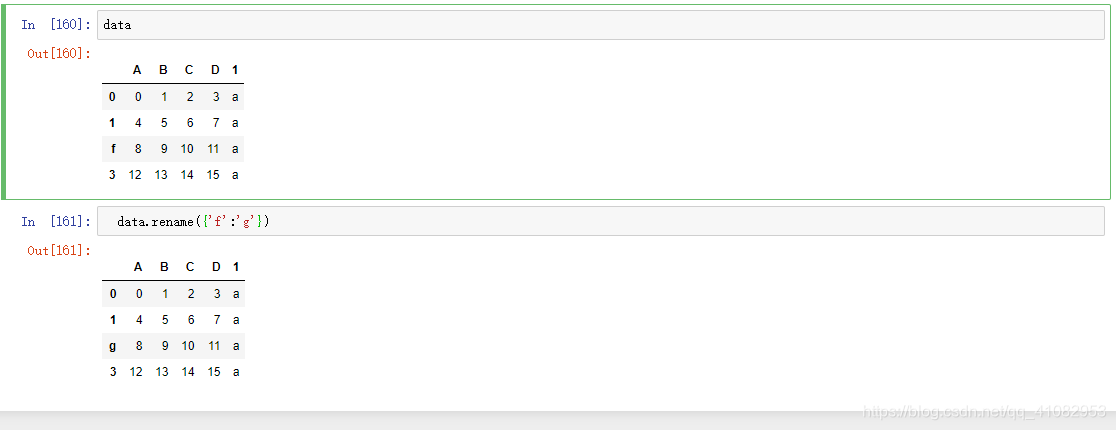
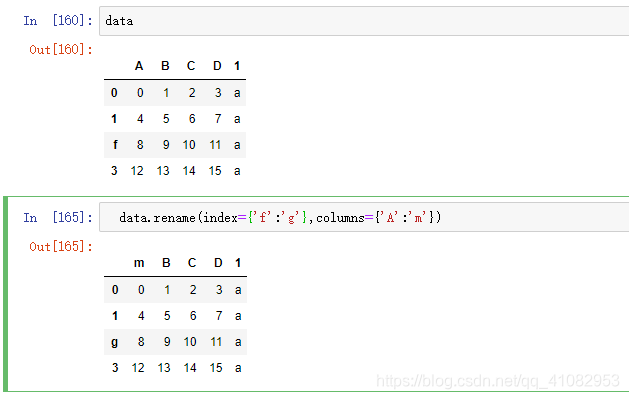
修改索引
- 重置索引:数据清洗时,会将带空值的行删除,此时DataFrame或Series类型的数据不再是连续的索引,可以使用reset_index()重置索引。
df.reset_index(drop=True,inplace=True) # drop代表放弃之前的index,inplace表示保存更换
清洗DataFrame的数据
df.dropna(
axis=0, # 0:对行进行操作;1:对列进行操作
how='any' # 'any'只要存在NaN就drop掉;'all':必须全部是NaN才drop掉
)
df.fillna(value=1) #NaN的值使用其他值代替,不如代替成1
pd.isnull() # 判断是否有缺失数据NaN,为True 表示缺失数据
print(np.any(df.isnull())==True) # True表示存在数据丢失
调整列的顺序
法一:
data = pd.DataFrame(np.random.randn(6,5),columns=list("ABCDE")) # 原始数据
df = data[list("DBCAE")] # 重新创建一组数据
法二:
data = pd.DataFrame(np.random.randn(6,5),columns=list("ABCDE")) # 原始数据
data_id = data['D'] # 需要调整的列
df = data.drop('D',axis=1) # 去除'D'列 ,不要忘记axis参数1代表列
df.insert(0,'M',data_id) # 在0处插入'D’的值并命名为'M'
多组DataFrame数据的连接合并(concatenating)
pd.concat()
pd.concat(
[df1,df2,df3], # 待合并的DateFrame
axis=0, # 0:纵向合并(上下合并);1:左右合并
ignore_index=True, # 重置行索引或列索引,默认为False
join='outer', # 当纵向合并时列索引标签不完全重合; 'outer':取并集(A+B),缺失值用NaN填充; 'inner'(AB):取交集
join_axes=[df1.index] # 根据df1的行索引进行横向合并(A-B),如果根据df1的行索引进行纵向合并时会报错
)
pd.append()
append只有纵向合并没有横向合并,相当于concat([df1,df2],axis=0,join=‘outer’),是纵向并集合并。
s1 = pd.Series([1,2,3,4], index=['a','b','c','d'])
df1.append(s1)
df1.append([df2,df3])
pd.merge
merge是根据某列标签内的值作为标志进行合并。
pd.merge(
df1,df2,
on=['key1','key2'],
how = 'outer',
indicator=True, # 查看合并的记录,indicator='Results',记录的结果标签设置为'Results'
left_index=True, # 根据左右资料集的index进行合并
right_index=True,
suffixes=['_boy','_girl'] # 解决overlapping的问题,方便合并后区分不同的标签
)
利用matplotlib画图
plot() 连续线图
df = pa.DataFrame(
np.random.randn(1000,4),
index=np.arange(1000),
columns=list("ABCD")
)
df = df.cumsum() # 可以对数据进行累加
df.plot()
plt.show()
scatter() 散点图
ax = df.plot.scatter(
x='A',
y='B',
color='LightGreen',
label='Class1'
)
df.plot.scatter(
x='A',
y='B',
color='DarkBlue',
label='Class2',
ax=ax
)
plt.show()
参考链接:
https://morvanzhou.github.io/tutorials/data-manipulation/np-pd/3-2-pd-indexing/
https://www.cnblogs.com/keye/p/7825280.html














 864
864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









