







arxiv: https://arxiv.org/abs/2305.13626
背景
基于LLM的对话系统在对话积极主动性方面存在局限性,不能对模棱两可的问题提出澄清、不能拒绝有问题的用户请求。
-
本文对基于LLM的对话系统在三个方面对积极主动性进行了综合分析:
(1)信息寻求对话系统中的澄清能力。要求系统在遇到用户query的内容模棱两可时,可以主动提出澄清问题。(2)目标引导的开放领域对话。要求系统主动将对话引向指定目标。
(3)非协作任务导向对话。系统和用户的对话目标不相同时,系统要想办法让用户与系统达成战略共识。
-
本文三个设计了主动思维链(ProCoT)赋予LLM主动实现上述三个方面对话目标的能力。
本文方法 -
Proactive Prompting
通过提供可选对话行为的方式,让LLM应采取的回复,而不是只让LLM进行简单直接的回复。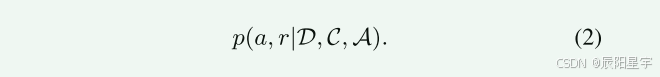
其中,D是背景信息,C是历史对话记录,A是可能的对话行为(例如,澄清问题或者直接回答)。a是LLM所所选择的动作,r是LLM的回复。
提示LLM选择最合适的对话行为a来生成响应r。
-
Proactive Chain-of-Thought Prompting
通过引入COT的方式,让LLM具备规划能力,让其可经过推理分析后再选择对话行为,提升性能。
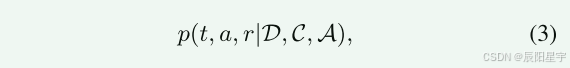
其中,D、C、A、a和r同上。t是选择对话行为a的推理分析。

实验情况
(1)澄清问题
-
定义问题
澄清问题可以被分为两个子问题:- 澄清需求预测(CNP),根据确定的文档D和对话文本C,进行二分类预测是否需要澄清问题。
- 澄清问题生成(CQG),如果需要澄清,则生成一个澄清响应。
-
实验设置
- 数据集
- Agb-CoQA通用领域数据集、PACIFIC金融数据集
- 评估指标
- 评估CNP:F1指标
- 评估CGQ:BLUE 1和 ROUGE-2(F1)指标、Help人工打分评估。
- 基座模型
- gpt-3.5-turbo-0301, temperature=0
- vicuna-13B-delta-v1.1, max token=2048
- 对比方法:
- 标注prompt、proactive prompt、ProCoT
- zero-shot、one-shot
- 数据集
-
实验结果
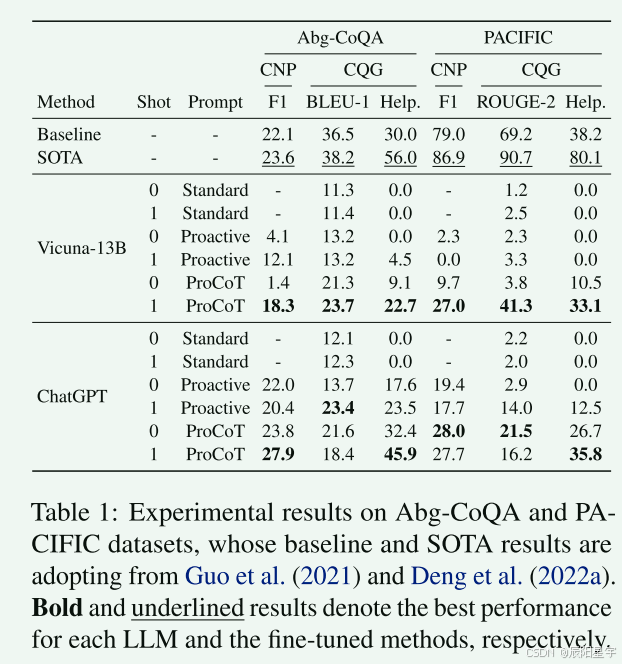
标准的prompt两个模型在人工评分的情况下,都不能针对问题进行澄清。在采用proactive、ProCoT下,能够对澄清问题的能力进行改善。
- 错误分析
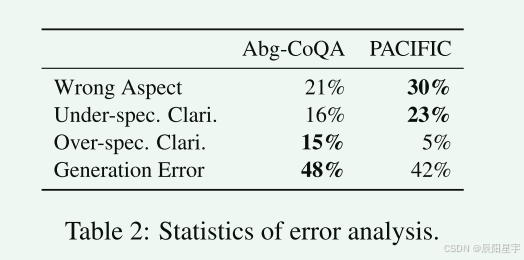
文中随机采样了100个错误样例进行分析,将错误示例分为四种:
- 错误方面:模型生成的澄清问题不是我们需要的澄清方面,澄清角度错误。
- 未具体说明澄清:模型产生了一个不够具体的澄清问题,其中所请求的信息过于笼统,因此用户很难提供反馈。
- 过度具体说明澄清:模型生成一个过于具体的澄清问题,其中所请求的信息在用户查询中已经很清楚了。
- 生成错误:虽然该模型识别了需要澄清的问题,但它没有生成所需格式的输出,例如没有澄清问题。
可以看出在金融领域中由于错误方面和未具体说明的澄清而导致失败的案例比例要高于通用领域。说明ChatGPT的错误可能是优于缺乏特定领域知识导致的。
(2)目标导向对话
-
定义问题
对话从一个任意的初始主题开始,系统需要产生多个回合的响应来引导对话走向最终目标。所产生的响应应满足:- 过渡流畅:在给定对话的语境下,内容自然适当。
- 目标实现:推动对话朝着指定目标发展。这个问题通常会被分解成两个子任务:下一个主题选择和过渡响应生成。
-
实验设置
- 数据集
- 回合级评估:OTTers数据集。在下一轮目标导向数据集上对目标引导能力进行回合级评估,这要求对话系统能主动桥接当前对话主题接近目标。
- 对话级评估:TGConv数据集。采用该数据集,用来证明将回合对话引导到目标话题能力作为对话级评估。
- 评估指标
- OTTers数据集
- 下一个主题预测指标:hits@k(k∈[1,3])
- 文本生成指标:BLEU、ROUGE-L、METEOR
- TGConv数据集
- Succ:8轮对话中生成目标词的成功率
- Turns:成功达到目标单词所有对话的平均回合数
- Coh:最后一个话语与生成的响应之间上下文语义的相似程度
- 人类评估
- 全局连贯性(G-Coh):整个对话在逻辑上和主题上是否连贯
- 有效性(Effect):达到目标的效率
- 分数等级[0, 1, 2],分数越高表明质量越好。
- OTTers数据集
- 基线对比
- 目标导向对话的微调基线模型:GPT-2、DKRN、CKC、TopKG、COLOR
- 数据集
-
实验结果
- 回合级评估
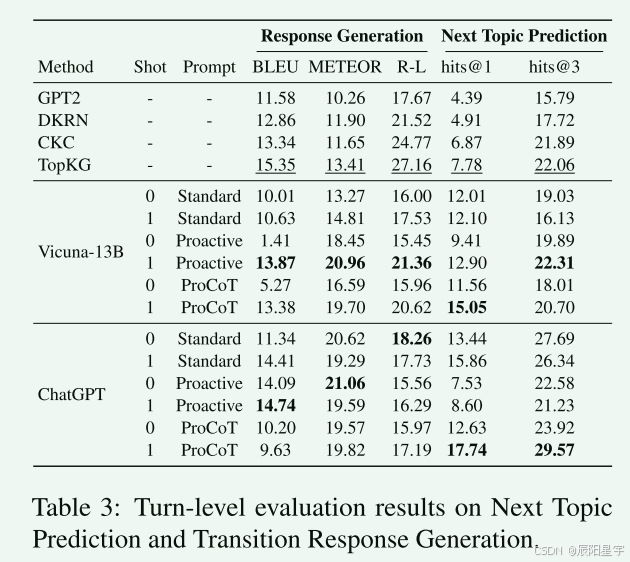
- 回合级评估
只有使用one-shot的ProCoT提示才能提高主题转移能力。如果没有演示,主动性和ProCoT提示的性能甚至比标准提示更差,因为llm可能会混淆需要的主题类型。
- 对话级评估
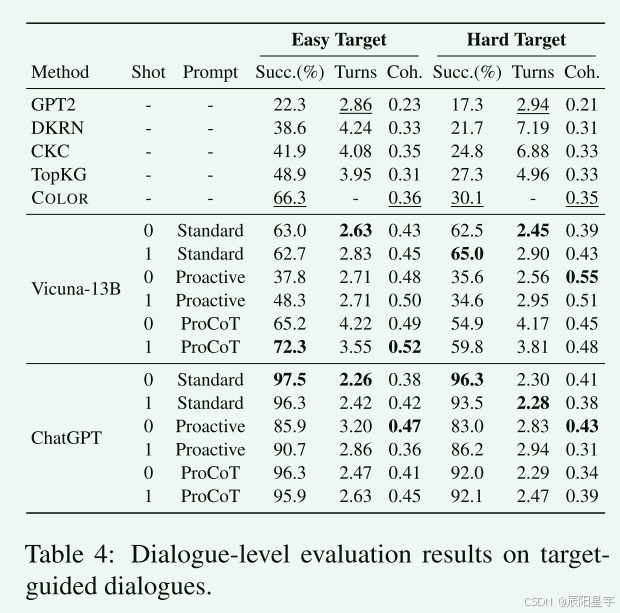
ProCoT提示使目标引导对话的主题转换更加顺畅。在主动提示下,通过主题规划提高了响应的连贯性。但是,成功率却受到负面影响。
- 人类评估
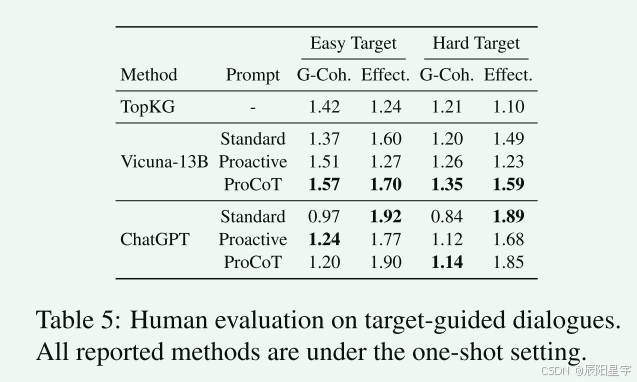
ChatGPT在达到目标的效率很高,但是在一致性上要低于TopKG。LLM的关键挑战是如何确保生成的过渡响应的局部平滑性和一致性。
(3)非协作对话
- 定义问题
用户和系统之间存在某种冲突,系统需要主动制定策略让用户可以朝着有利于系统设定的方向和系统进行合作,而不是被动地跟随用户意图。
目标是生成具有适当对话策略的响应ut,该策略可使系统和用户之间达成共识。预先定义了一组对话策略A用于预测。根据不同的应用,对话策略可以是粗的对话行为标签,也可以是细粒度的策略标签。
- 实验设置
- 数据集:CraigslistBargain数据集。评估基于LLM的对话系统处理非协作的能力,场景是『讨价还价』。
- 评估指标
- 谈判策略预测和对话行为预测评估指标:F1、ROC AUC
- 响应生成指标:BLEU
- 人类评估:
- 随机抽样100个样例进行人类评估
- 主观判断:针对说服力、连贯性、语言自然程度(像人类说话程度)打分[0, 1, 2]。
- 客观判断(议价能力):
S L % = b a r g a i n p r i c e − b u y e r t a r g e t p r i c e l i s t e d p r i c e − b u y e r t a r g e t p r i c e SL\%=\frac{bargain \ price - buyer \ target \ price}{listed \ price - buyer \ target \ price} SL%=listed price−buyer target pricebargain price−buyer target price
其中,bargain price是卖方当前愿意出售该物品的价格,buyer target price是买房当前愿意购买该物品的价格,listed price是当前物品的标价。
- 基线对比
- 几种微调后SOTA的对话基线:FeHED、HED+RNN/TFM、DIALOGRAPH
- 实验情况
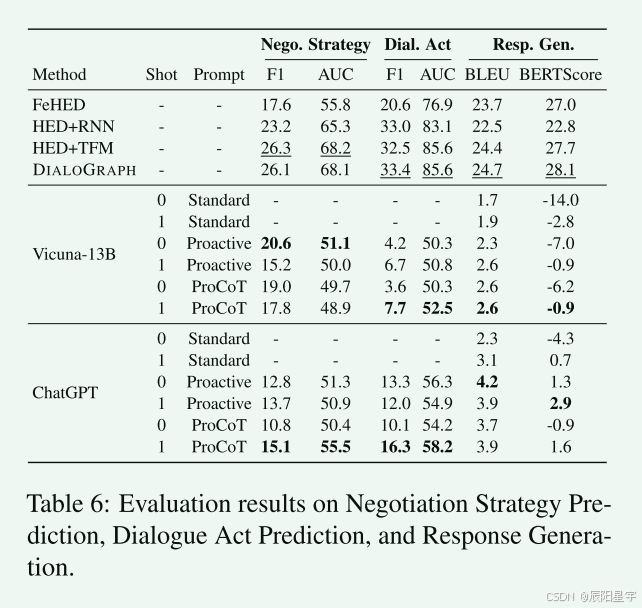
基于LLM的对话系统无法预测适当的谈判策略和对话行为。虽然主动提示和ProCoT提示方案都能略微提高响应生成的最终性能,但与根据自动评估指标进行微调的方法相比,仍有很大差距。
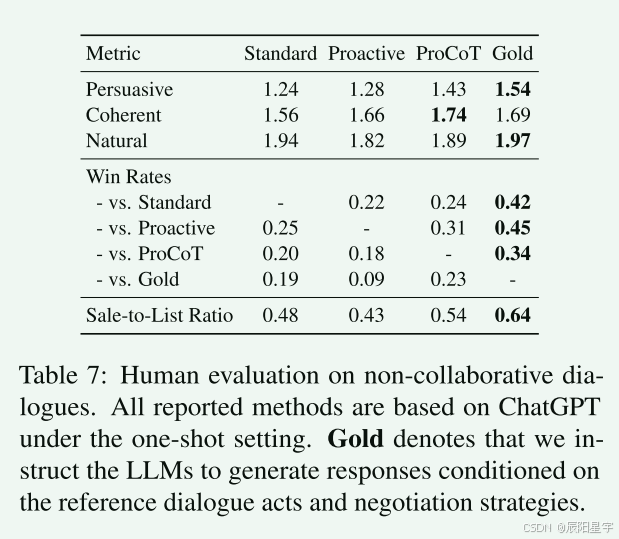
根据参考策略生成对话响应更有利。具体来说,ChatGPT保证了在类人响应生成(Natural)上的高分。使用ProCoT,生成的响应与会话历史更加一致(coherent)。根据示例观察,发现ChatGPT在谈判过程中倾向于与买方妥协,而不是策略性地采取行动使自身利益最大化。


















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











