









 Apache Hive 是一个基于 Hadoop 的数据仓库软件,提供 SQL 查询和分析大规模数据的能力。Hive 支持 ETL、数据分析和报告任务,其数据组织包括数据库、表、分区和桶。数据存储在 HDFS 或其他系统中,查询通过 Tez、Spark 或 MapReduce 执行。Hive 使用 MySQL 作为元数据库,并具备灵活的数据类型和安装部署流程。
Apache Hive 是一个基于 Hadoop 的数据仓库软件,提供 SQL 查询和分析大规模数据的能力。Hive 支持 ETL、数据分析和报告任务,其数据组织包括数据库、表、分区和桶。数据存储在 HDFS 或其他系统中,查询通过 Tez、Spark 或 MapReduce 执行。Hive 使用 MySQL 作为元数据库,并具备灵活的数据类型和安装部署流程。
Hive介绍
Apache Hive 是一款基于 Hadoop 的数据仓库软件
Hadoop 为商品硬件上的数据存储和处理提供了大规模扩展和容错能力. Hive 的设计目的是为了方便地进行数据的汇总、临时查询和大量数据的分析
它支持 SQL 语句,因此用户可以在 Hive 中进行一些特殊的查询、汇总和数据分析. 同时,Hive 的 SQL 也为用户提供了诸如用户定义函数(UDF)的特性来支持自定义的分析.
总体而言, Hive 通过在分布式存储中支持 SQL ,能够简化对大数据的查询、分析和管理工作,它还提供了命令行工具和 JDBC 的驱动程序来支持来自外部程序的连接.
Hive架构
Hive 的两大组件主要是 HCatalog 和 WebHCat
其中,HCatalog 是 Hadoop 的表和存储管理层,允许使用不同数据处理工具(例如 MapReduce b)的用户更容易地在网格上进行数据的读写
而 WebHCat 提供了一个服务,用户可通过该服务来运行 MapReduce 任务、Pig 查询、Hive 作业,也可以使用 HTTP 的 REST 接口来执行一些 Hive 的元数据操作
Hive 数据仓库在架构上主要具有以下特点:
- 提供了利用 SQL 访问数据的工具,因此支持诸如提取、转换和加载(ETL)以及数据分析和报告等方面的的数据仓库任务。
- 在数据格式中通过结构来维护它们的关系。
- 本身不存储数据,其数据都是直接存储在 HDFS 或 HBase 等存储系统中。
- 查询操作可以通过 Tez、 Spark 或 MapReduce 等计算引擎来执行。
- 支持过程语言和 HPL-SQL 。
- 通过 Hive LLAP、YARN 和 Slider 的支持,可以进行次秒级的查询检索。
尽管 Hive 提供了标准的 SQL 功能,但它并不是为在线事务处理设计的,而更适用于数据仓库任务
Hive 的设计目的是实现可伸缩性、性能、可扩展性和容错的最大化,以及输入格式的松耦合,因此 Hive 中不存在唯一的数据存储格式,它支持带有内置连接器的逗号、制表符分隔值文件(例如 CSV 、TSV 格式的文件)、Parquet、ORC 等格式. 我们可以使用这些格式的连接器来扩展 Hive
Hive中的基本数据单元
按粒度排序,Hive 的数据组织单位分为以下几种:
-
**数据库(Database):**用来避免表、视图、分区、列等命名冲突的命名空间,还可用于加强用户或用户组的安全性
-
**表(Table):**具有相同模式(Schema)的同质数据单元。在稍后的课程内我们会以 page_views 表作为案例进行讲解,其中每一行可以包含以下列:
timestamp:INT 类型,表示对应于浏览页面时的 UNIX 时间戳。userid:BIGINT 类型,表示查看页面的用户。page_url:字符串类型,表示捕获页面的位置。referer_url:字符串类型,表示捕获用户到达当前页面的页面位置。IP:字符串类型,表示发出页面请求的 IP 地址。
-
**分区(Partition):**每个表都有一个或多个分区键来确定数据的存储方式
除了存储单元,分区能够让用户有效地识别满足指定条件的行: 例如,字符串类型的
date_partition和country_partition可以分别表示按日期的分区和按国家地区的分区。分区键中的每个唯一值用于定义表的一个分区。例如,2005-05-18中的所有CN数据都是page_views表的一个分区。因此,如果只对2005-10-18的CN数据进行分析,那么只能在表的相关分区上运行查询,因此分区能够提高分析效率。分区是为了方便而进行命名的,数据管理员负责来维护分区名称和数据内容之间的关系。而分区列是一种虚拟列,它们不是数据本身的一部分,而是根据负载派生的. -
桶(Bucket):也称为集群(Cluster),每个分区中的数据可以根据表中某个列的散列函数的值将其划分为不同的桶。例如,
page_views表可以基于userid进行桶的划分,但userid只是page_view表中的一个列,而不是分区列。划分了桶之后,系统在查询处理期间就可以删除大量的虚拟数据,因此数据的采样将会更加高效,也提高了查询效率。
Hive数据类型
Hive 支持一些原始和复杂的数据类型,可以访问官网的 Hive 数据类型 来查阅具体信息
Hive安装部署
下载和目录设置
使用 wget 命令从 Apache 下载镜像中下载最新稳定版本的 Hive . 此处我们选择了 Hive 的 2.3.3 版本.
wget https://labfile.oss.aliyuncs.com/courses/1136/apache-hive-2.3.3-bin.tar.gz
解压
tar -zxvf apache-hive-2.3.3-bin.tar.gz
移动到指定目录
sudo mv apache-hive-2.3.3-bin /usr/local/src/hive-2.3.3
环境变量设置
目录设置完成后,需要设置 Hive 相关的环境变量,使得 HIVE_HOME 指向其安装目录
vi /home/hadoop/.bashrc
在文件的末尾添加以下内容
export HIVE_HOME=/usr/local/src/hive-2.3.3
export PATH=$PATH:$HIVE_HOME/bin
其中 PATH 需要根据当前实验环境的实际情况进行修改,$PATH 指代的是之前已有的内容,请直接在 PATH 环境变量的最后添加 :$HIVE_HOME/bin 即可。
编辑完成后保存并退出,使用 source 命令来激活以上环境变量:
source ~/.bashrc
元数据库配置
在正式使用 Hive 之前,需要设置它的元数据存储
默认情况下, Hive 将元信息存储在嵌入式的 Derby 数据库中. 它在磁盘上的存储位置由 Hive 配置文件 conf/hive-default.xml 中的配置项 javax.jdo.option.ConnectionURL决定. 默认情况下,这个位置是 ./metastore_db 。
我们将采用 MySQL 作为元数据的存储。因此需要修改 Hive 的配置文件。
请在终端中输入以下命令,将配置模版文件复制一份使其生效:
cp $HIVE/conf/hive-default.xml.template $HIVE/conf/hive-site.xml

随后用 Vim 编辑器打开这个配置文件:
vim /opt/hive-2.3.3/conf/hive-site.xml

以下的配置项你可以通过 Vim 编辑器的搜索功能进行快速的定位(命令模式下按 / 键可以进行查找),也可以参考行数进行寻找
在第 545 行,找到名称为 javax.jdo.option.ConnectionURL 的配置项,将其配置值修改为 jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true
这是在设置元数据库的 JDBC 连接信息

在第 1020 行,找到名称为 javax.jdo.option.ConnectionDriverName 的配置项,将其配置值修改为 com.mysql.jdbc.Driver
这是在设置数据库连接的驱动程序名称

在第 1045 行,找到名称为 javax.jdo.option.ConnectionUserName 的配置项,将其配置值修改为 hive
这是在设置连接数据库所使用的用户名

在第 530 行,找到名称为 javax.jdo.option.ConnectionPassword 的配置项,将其配置值修改为 hive
这是在设置连接数据库所使用的密码

在第 39 行,找到名称为 hive.exec.scratchdir 的配置项,将其配置值修改为 /user/hive/tmp
这是在设置 HDFS 上临时文件的目录路径

在第 75 行,找到名称为 hive.exec.local.scratchdir 的配置项,将其配置值修改为 /tmp/hive
这是在设置本地文件系统中临时文件的目录路径
注意该路径不是 HDFS 上的路径,而是本地文件系统的路径

在第 1685 行,找到名称为 hive.querylog.location 的配置项,将其配置值修改为 /home/hadoop/hive/log
这是在设置查询日志的存放位置

在第 80 行,找到名称为 hive.downloaded.resources.dir 的配置项,将其配置值修改为 /tmp/hive
这是在设置下载资源的存放位置

对上述配置项编辑完成后,保存并退出编辑器。
随后,我们需要在 MySQL 数据库中创建上述配置项所用到的用户及密码。
数据库部署
安装
下载rpm包
wget https://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm
安装依赖
yum -y localinstall mysql57-community-release-el7-11.noarch.rpm

下载并安装mysql
yum -y install mysql-community-server

设置密码与用户
首先需要启动 MySQL 的服务,请在终端中输入以下命令:
sudo service mysql start
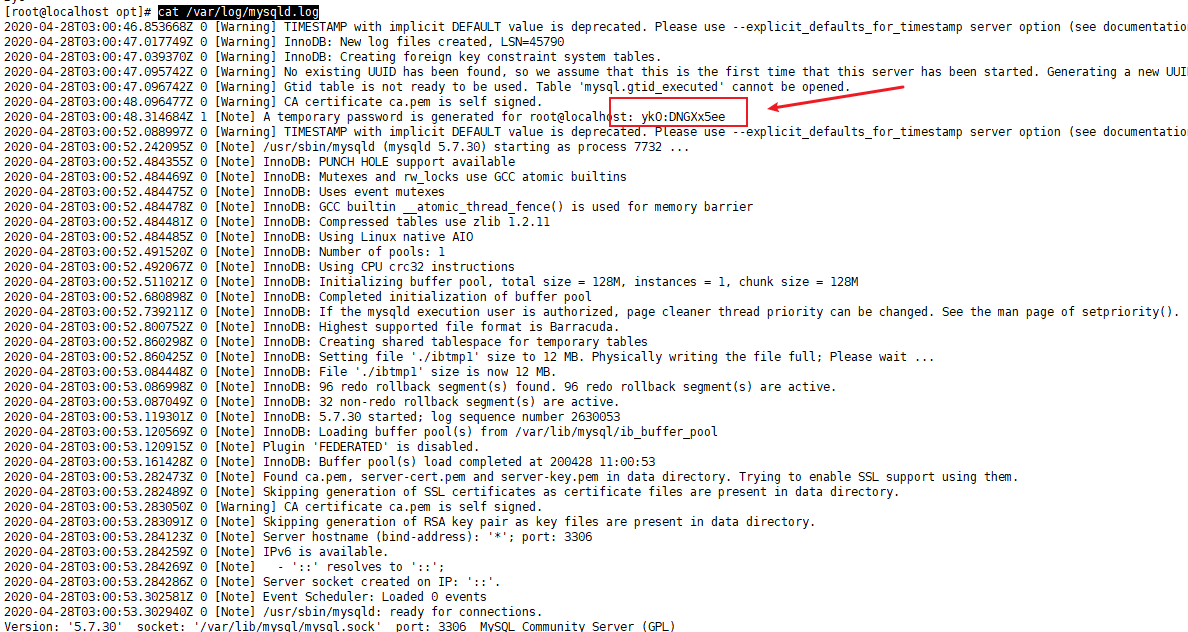
获取mysql默认密码
cat /var/log/mysqld.log
登陆
mysql -uroot -pykO:DNGXx5ee
修改默认密码
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Uiuingcom123@';
进入到 MySQL 的命令行之后,使用如下语句来创建名为 hive 的数据库用户,密码也设置为 hive
CREATE USER 'hive'@'%' IDENTIFIED BY 'hive';

然后为 hive 用户赋予权限并刷新:
grant all on hive.* to 'hive'@'%' identified by 'hive';flush privileges;
退出
exit;
重启服务
systemctl restart mysqld
配置JDBC驱动
前往hive驱动包目录
cd $HIVE_HOME/lib
下载驱动包
wget https://search.maven.org/remotecontent?filepath=mysql/mysql-connector-java/8.0.27/mysql-connector-java-8.0.27.jar
设置Hive体系参数
元数据库配置好之后,还需要设置 Hive 内部用于识别 Hadoop 位置、内部配置文件路径等方面的配置项
首先是使用 cp 命令将设置模版复制一份,使其生效
cp $HIVE_HOME/conf/hive-env.sh.template $HIVE_HOME/conf/hive-env.sh
随后用 vi 编辑器打开 hive-env.sh 文件:
vi $HIVE_HOME/conf/hive-env.sh
在第 48 行,设置 Hadoop 的安装路径:
HADOOP_HOME=/usr/local/src/hadoop-2.6.1
在第 51 行,设置 Hive 的配置文件目录路径:
export HIVE_CONF_DIR=/usr/local/src/hive-2.3.3/conf
在第 51 行,设置 Hive 的配置文件目录路径:
export HIVE_CONF_DIR=/usr/local/src/conf
对以上配置项编辑完成后,保存并退出编辑器
初始化元数据库
所有的配置工作完成后,就可以开始初始化元数据库了。
由于稍后用到的数据会存储在 HDFS 上,因此需要提前启动好 HDFS 。请在终端中输入以下命令来启动 HDFS :
sh $HADOOP_HOME/sbin/start-dfs.sh
sh $HADOOP_HOME/sbin/start-yarn.sh
如果是首次使用 Hadoop ,则需要通过 hdfs namenode -format 对其进行初始化。
此处将会使用 Hive 自带的 schematool 工具来完成初始化工作。请在终端中输入以下命令:
schematool -initSchema -dbType mysql

当提示信息中表示已经完成初始化之后,就可以通过 hive 命令进入到其命令行。请在终端中输入以下命令:
hive

启动
后台启动远程服务
hive --service metastore &
后台启动hive2
hive --service hiveserver2 &

















 580
580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











